Trabajar en un sistema HPC remoto
Última actualización: 2026-02-26 | Mejora esta página
Tiempo estimado: 35 minutos
Hoja de ruta
Preguntas
- “¿Qué es un sistema HPC?”
- “¿Cómo funciona un sistema HPC?”
- “¿Cómo me conecto a un sistema HPC remoto?”
Objetivos
- “Conectarse a un sistema HPC remoto”
- “Comprender la arquitectura general del sistema HPC”
¿Qué es un sistema HPC?
Las palabras “nube”, “clúster”, y la frase “computación de alto rendimiento” o “HPC” se utilizan mucho en diferentes contextos y con varios significados relacionados. ¿Qué significan? Y lo que es más importante, ¿cómo los utilizamos en nuestro trabajo?
La nube es un término genérico comúnmente utilizado para referirse a los recursos informáticos que son a) proporcionados a los usuarios bajo demanda o según sus necesidades y b) representan recursos reales o virtuales que pueden estar localizados en cualquier lugar de la Tierra. Por ejemplo, una gran empresa con recursos informáticos en Brasil, Zimbabue y Japón puede gestionar esos recursos como su propia nube interna y esa misma empresa puede utilizar también recursos comerciales en la nube proporcionados por Amazon o Google. Los recursos en la nube pueden referirse a máquinas que realizan tareas relativamente sencillas como servir sitios web, proporcionar almacenamiento compartido, proporcionar servicios web (como correo electrónico o plataformas de medios sociales), así como tareas más tradicionales de computación intensiva como ejecutar una simulación.
El término sistema HPC, por otro lado, describe un recurso independiente para cargas de trabajo computacionalmente intensivas. Suelen estar compuestos por una multitud de elementos integrados de procesamiento y almacenamiento, diseñados para manejar grandes volúmenes de datos y/o grandes números de operaciones en coma flotante (FLOPS) con el mayor rendimiento posible. Por ejemplo, todas las máquinas de la lista Top-500 son sistemas HPC. Para soportar estas limitaciones, un recurso HPC debe existir en una ubicación específica y fija: los cables de red sólo pueden estirarse hasta cierto punto, y las señales eléctricas y ópticas sólo pueden viajar a cierta velocidad.
La palabra “clúster” se utiliza a menudo para recursos HPC de escala pequeña a moderada menos impresionantes que el Top-500. Los clústeres suelen mantenerse en centros de cálculo que soportan varios sistemas de este tipo, todos ellos compartiendo redes y almacenamiento comunes para soportar tareas comunes de cálculo intensivo.
Inicio de sesión
El primer paso para utilizar un clúster es establecer una conexión entre nuestro portátil y el clúster. Cuando estamos sentados frente a un ordenador (o de pie, o sosteniéndolo en la mano o en la muñeca), esperamos ver una pantalla con iconos, widgets y quizás algunas ventanas o aplicaciones: una interfaz gráfica de usuario o GUI. Dado que los clústeres informáticos son recursos remotos a los que nos conectamos a través de interfaces a menudo lentas o con retardo (WiFi y VPN, especialmente), es más práctico utilizar una interfaz de línea de comandos, o CLI, en la que los comandos y los resultados se transmiten únicamente a través de texto. Todo lo que no sea texto (imágenes, por ejemplo) debe escribirse en disco y abrirse con un programa aparte.
Si alguna vez has abierto el símbolo del sistema de Windows o el terminal de macOS, habrás visto una CLI. Si ya has tomado los cursos de Las Carpinterías sobre la Shell UNIX o el Control de Versiones, has usado la CLI en tu máquina local algo extensamente. El único salto a dar aquí es abrir un CLI en una máquina remota, tomando algunas precauciones para que otras personas en la red no puedan ver (o cambiar) los comandos que estás ejecutando o los resultados que la máquina remota envía de vuelta. Usaremos el protocolo Secure SHell (o SSH) para abrir una conexión de red encriptada entre dos máquinas, permitiéndote enviar y recibir texto y datos sin tener que preocuparte de miradas indiscretas.

Asegúrese de que tiene un cliente SSH instalado en su portátil.
Consulte la sección setup para más detalles.
Los clientes SSH suelen ser herramientas de línea de comandos, donde se
proporciona la dirección de la máquina remota como único argumento
requerido. Si tu nombre de usuario en el sistema remoto difiere del que
usas localmente, debes proporcionarlo también. Si tu cliente SSH tiene
un front-end gráfico, como PuTTY o MobaXterm, establecerás estos
argumentos antes de hacer clic en “conectar” Desde el terminal,
escribirás algo como ssh userName@hostname, donde el
símbolo “@” se utiliza para separar las dos partes de un único
argumento.
Sigue adelante y abre tu terminal o cliente gráfico SSH, luego inicia sesión en el cluster usando tu nombre de usuario y el ordenador remoto al que puedes acceder desde el mundo exterior, cluster.hpc-carpentry.org.
Recuerda sustituir yourUsername por tu nombre de usuario
o el que te proporcionen los instructores. Es posible que te pidan tu
contraseña. Atención: los caracteres que escriba después de la solicitud
de contraseña no se mostrarán en pantalla. La salida normal se reanudará
cuando pulse Enter.
¿Dónde estamos?
Muy a menudo, muchos usuarios se ven tentados a pensar que una
instalación de computación de alto rendimiento es una máquina gigante y
mágica. A veces, la gente asume que el ordenador en el que han iniciado
sesión es todo el clúster de computación. Pero, ¿qué ocurre realmente?
¿En qué ordenador hemos iniciado sesión? El nombre del ordenador en el
que hemos iniciado sesión se puede comprobar con el comando
hostname. (¡También puedes notar que el nombre de host
actual es también parte de nuestro prompt!)
SALIDA
login1¿Qué hay en tu directorio de inicio?
Es posible que los administradores del sistema hayan configurado su
directorio personal con algunos archivos, carpetas y enlaces (accesos
directos) útiles a espacios reservados para usted en otros sistemas de
archivos. Eche un vistazo a ver qué encuentra. Sugerencia: Los
comandos del shell pwd y ls pueden resultarle
útiles. El contenido de los directorios personales varía de un usuario a
otro. Por favor, comenta cualquier diferencia que encuentres con tus
vecinos.
La capa más profunda debe diferir: yourUsername es
exclusivamente suya. ¿Hay diferencias en la ruta en los niveles
superiores?
Si ambos tienen directorios vacíos, se verán idénticos. Si tú o tu vecino habéis usado el sistema antes, puede haber diferencias. ¿En qué estás trabajando?
Utilice pwd para imprimir la ruta del directorio de
trabajo:
Puede ejecutar ls para
listar el contenido del directorio,
aunque es posible que no aparezca nada (si no se han proporcionado
ficheros). Para estar seguro, utilice también el indicador
-a para mostrar los archivos ocultos.
Como mínimo, esto mostrará el directorio actual como .,
y el directorio padre como ...
Nodos
Los ordenadores individuales que componen un clúster se suelen llamar nodos (aunque también se les llama servidores, ordenadores y máquinas). En un clúster, hay distintos tipos de nodos para distintos tipos de tareas. El nodo en el que te encuentras en este momento se llama nodo de cabecera, nodo de inicio de sesión, almohadilla de aterrizaje o nodo de envío. Un nodo de inicio de sesión sirve como punto de acceso al clúster.
Como pasarela, es muy adecuada para subir y descargar archivos, configurar software y realizar pruebas rápidas. En general, el nodo de acceso no debe utilizarse para tareas que consuman mucho tiempo o recursos. Deberías estar atento a esto, y comprobar con los operadores o la documentación de tu sitio los detalles de lo que está y no está permitido. En estas lecciones, evitaremos ejecutar trabajos en el nodo principal.
Nodos de transferencia dedicados
Si desea transferir grandes cantidades de datos hacia o desde el clúster, algunos sistemas ofrecen nodos dedicados sólo para transferencias de datos. La motivación de esto radica en el hecho de que las transferencias de datos más grandes no deben obstruir el funcionamiento del nodo de inicio de sesión para nadie más. Comprueba en la documentación de tu clúster o con su equipo de soporte si existe un nodo de transferencia de este tipo. Como regla general, considere todas las transferencias de un volumen superior a 500 MB a 1 GB como grandes. Pero estos números cambian, por ejemplo, en función de la conexión de red propia y de su clúster u otros factores.
El verdadero trabajo en un cluster lo hacen los nodos de trabajo (o computación). Los nodos de trabajo tienen muchas formas y tamaños, pero generalmente se dedican a tareas largas o difíciles que requieren muchos recursos computacionales.
Toda la interacción con los nodos trabajadores es manejada por una pieza especializada de software llamada planificador (el planificador utilizado en esta lección se llama Slurm). Aprenderemos más sobre cómo usar el planificador para enviar trabajos a continuación, pero por ahora, también puede darnos más información sobre los nodos trabajadores.
Por ejemplo, podemos ver todos los nodos trabajadores ejecutando el
comando sinfo.
SALIDA
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
cpubase_bycore_b1* up infinite 4 idle node[1-2],smnode[1-2]
node up infinite 2 idle node[1-2]
smnode up infinite 2 idle smnode[1-2]También hay máquinas especializadas que se utilizan para gestionar el almacenamiento en disco, la autenticación de usuarios y otras tareas relacionadas con la infraestructura. Aunque no solemos iniciar sesión o interactuar con estas máquinas directamente, permiten una serie de características clave como asegurar que nuestra cuenta de usuario y archivos están disponibles en todo el sistema HPC.
¿Qué hay en un Nodo?
Todos los nodos de un sistema HPC tienen los mismos componentes que su propio ordenador portátil o de sobremesa: CPUs (a veces también llamados procesadores o cores), memoria (o RAM) y espacio de disco. Las CPU son la herramienta de un ordenador para ejecutar programas y cálculos. La información sobre una tarea en curso se almacena en la memoria del ordenador. Disco se refiere a todo el almacenamiento al que se puede acceder como un sistema de archivos. Por lo general, se trata de un almacenamiento que puede guardar datos de forma permanente, es decir, los datos siguen ahí aunque se reinicie el ordenador. Aunque este almacenamiento puede ser local (un disco duro instalado en su interior), es más común que los nodos se conecten a un servidor de archivos compartido y remoto o a un clúster de servidores.
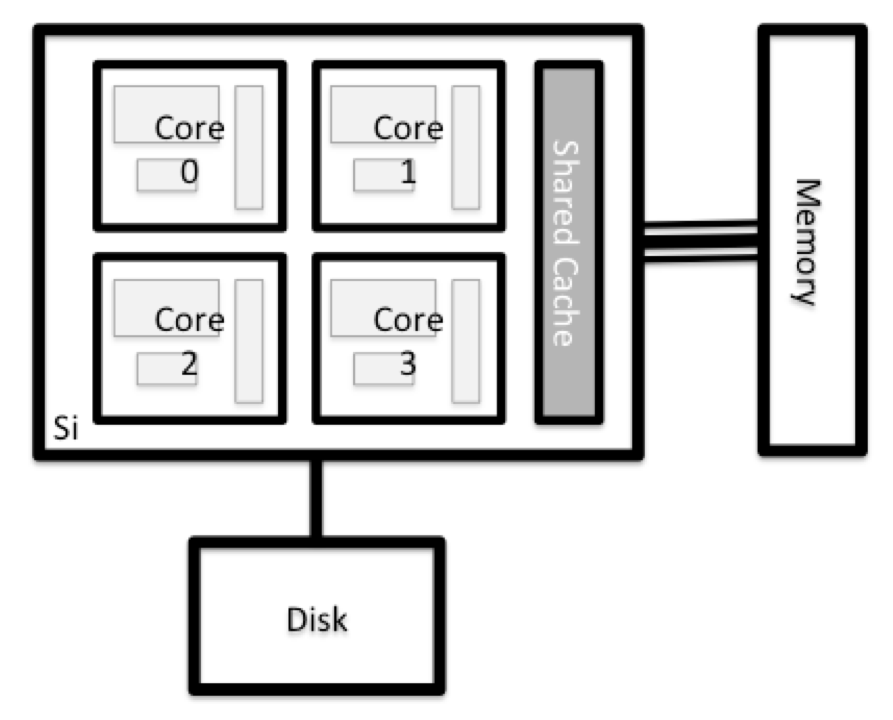
Explore su ordenador
Hay varias maneras de hacer esto. La mayoría de los sistemas operativos tienen un monitor gráfico del sistema, como el Administrador de tareas de Windows. A veces se puede encontrar información más detallada en la línea de comandos. Por ejemplo, algunos de los comandos utilizados en un sistema Linux son:
Ejecutar utilidades del sistema
Lectura de /proc
Utilizar un monitor del sistema
Explorar el nodo de acceso
Ahora compara los recursos de tu ordenador con los del nodo principal.
BASH
[you@laptop:~]$ ssh yourUsername@cluster.hpc-carpentry.org
[yourUsername@login1 ~] nproc --all
[yourUsername@login1 ~] free -mPuedes obtener más información sobre los procesadores usando
lscpu, y muchos detalles sobre la memoria leyendo el
fichero /proc/meminfo:
También puedes explorar los sistemas de ficheros disponibles usando
df para mostrar el espacio disk
free. La opción -h muestra los tamaños en
un formato amigable, es decir, GB en lugar de B. La opción
type -T muestra qué tipo de sistema de
ficheros es cada recurso.
Los sistemas de ficheros locales (ext, tmp, xfs, zfs) dependerán de si estás en el mismo nodo de login (o nodo de computación, más adelante). Los sistemas de ficheros en red (beegfs, cifs, gpfs, nfs, pvfs) serán similares — pero pueden incluir yourUsername, dependiendo de cómo esté montado.
Sistemas de archivos compartidos
Es importante recordar que los archivos guardados en un nodo (ordenador) suelen estar disponibles en cualquier parte del clúster
Compare su ordenador, el nodo de inicio de sesión y el nodo de cálculo
Compara el número de procesadores y memoria de tu portátil con los números que ves en el nodo cabeza del cluster y en el nodo trabajador. Discute las diferencias con tu vecino.
¿Qué implicaciones crees que pueden tener las diferencias a la hora de ejecutar tu trabajo de investigación en los distintos sistemas y nodos?
Diferencias entre nodos
Muchos clusters HPC tienen una variedad de nodos optimizados para cargas de trabajo particulares. Algunos nodos pueden tener una mayor cantidad de memoria, o recursos especializados como Unidades de Procesamiento Gráfico (GPUs).
Con todo esto en mente, ahora veremos cómo hablar con el planificador del clúster y utilizarlo para empezar a ejecutar nuestros scripts y programas
- “Un sistema HPC es un conjunto de máquinas conectadas en red”
- “Los sistemas HPC suelen proporcionar nodos de inicio de sesión y un conjunto de nodos trabajadores”
- “Los recursos que se encuentran en nodos independientes (trabajadores) pueden variar en volumen y tipo (cantidad de RAM, arquitectura del procesador, disponibilidad de sistemas de ficheros montados en red, etc.).”
- “Los archivos guardados en un nodo están disponibles en todos los nodos”