Arbeiten auf einem entfernten HPC-System
Zuletzt aktualisiert am 2026-02-26 | Diese Seite bearbeiten
Übersicht
Fragen
- “Was ist ein HPC-System?”
- “Wie funktioniert ein HPC-System?”
- “Wie melde ich mich bei einem entfernten HPC-System an?”
Ziele
- “Verbinden Sie sich mit einem entfernten HPC-System.”
- “Verstehen Sie die allgemeine HPC-Systemarchitektur.”
Was ist ein HPC-System?
Die Begriffe “Cloud”, “Cluster” und “High-Performance Computing” oder “HPC” werden in verschiedenen Zusammenhängen und mit unterschiedlichen Bedeutungen verwendet. Was bedeuten sie also? Und was noch wichtiger ist: Wie verwenden wir sie bei unserer Arbeit?
Die Cloud ist ein allgemeiner Begriff, der sich auf Computerressourcen bezieht, die a) den Benutzern auf Anfrage oder nach Bedarf zur Verfügung gestellt werden und b) reale oder virtuelle Ressourcen darstellen, die sich überall auf der Erde befinden können. So kann beispielsweise ein großes Unternehmen mit Rechenressourcen in Brasilien, Simbabwe und Japan diese Ressourcen als seine eigene interne Cloud verwalten, und dasselbe Unternehmen kann auch kommerzielle Cloud-Ressourcen von Amazon oder Google nutzen. Cloud-Ressourcen können sich auf Maschinen beziehen, die relativ einfache Aufgaben ausführen, wie z. B. die Bereitstellung von Websites, die Bereitstellung von gemeinsamem Speicherplatz, die Bereitstellung von Webdiensten (z. B. E-Mail oder Social-Media-Plattformen) sowie traditionellere rechenintensive Aufgaben wie die Ausführung einer Simulation.
Der Begriff HPC-System beschreibt dagegen eine eigenständige Ressource für rechenintensive Arbeitslasten. Sie bestehen in der Regel aus einer Vielzahl integrierter Verarbeitungs- und Speicherelemente, die darauf ausgelegt sind, große Datenmengen und/oder eine große Anzahl von Gleitkommaoperationen (FLOPS) mit der höchstmöglichen Leistung zu verarbeiten. So sind zum Beispiel alle Maschinen auf der Top-500 Liste HPC-Systeme. Um diesen Anforderungen gerecht zu werden, muss eine HPC-Ressource an einem bestimmten, festen Standort vorhanden sein: Netzwerkkabel können nur bis zu einem bestimmten Punkt verlegt werden, und elektrische und optische Signale können nur mit einer bestimmten Geschwindigkeit übertragen werden.
Der Begriff “Cluster” wird häufig für kleine bis mittelgroße HPC-Ressourcen verwendet, die weniger beeindruckend sind als die [Top-500] (https://www.top500.org). Cluster werden oft in Rechenzentren unterhalten, die mehrere solcher Systeme unterstützen, die alle ein gemeinsames Netzwerk und einen gemeinsamen Speicher nutzen, um gemeinsame rechenintensive Aufgaben zu unterstützen.
Anmelden
Der erste Schritt bei der Nutzung eines Clusters besteht darin, eine Verbindung zwischen unserem Laptop und dem Cluster herzustellen. Wenn wir an einem Computer sitzen (oder stehen, oder ihn in der Hand oder am Handgelenk halten), erwarten wir eine visuelle Anzeige mit Symbolen, Widgets und vielleicht einigen Fenstern oder Anwendungen: eine grafische Benutzeroberfläche (GUI). Da es sich bei Computerclustern um entfernte Ressourcen handelt, mit denen wir uns über oft langsame oder verzögerte Schnittstellen (insbesondere WiFi und VPNs) verbinden, ist es praktischer, eine Befehlszeilenschnittstelle (CLI) zu verwenden, bei der Befehle und Ergebnisse nur über Text übertragen werden. Alles, was nicht Text ist (z. B. Bilder), muss auf die Festplatte geschrieben und mit einem separaten Programm geöffnet werden.
Wenn Sie jemals die Windows-Eingabeaufforderung oder das macOS-Terminal geöffnet haben, haben Sie ein CLI gesehen. Wenn Sie bereits an den The Carpentries-Kursen über die UNIX-Shell oder Versionskontrolle teilgenommen haben, haben Sie die CLI auf Ihrem lokalen Rechner ziemlich ausgiebig genutzt. Der einzige Schritt, der hier gemacht werden muss, ist das Öffnen einer CLI auf einem entfernten Rechner, wobei einige Vorsichtsmaßnahmen getroffen werden müssen, damit andere Leute im Netzwerk die Befehle, die Sie ausführen, oder die Ergebnisse, die der entfernte Rechner zurücksendet, nicht sehen (oder ändern) können. Wir werden das Secure SHell-Protokoll (oder SSH) verwenden, um eine verschlüsselte Netzwerkverbindung zwischen zwei Rechnern herzustellen, die es Ihnen ermöglicht, Text und Daten zu senden und zu empfangen, ohne sich um neugierige Blicke sorgen zu müssen.

Stellen Sie sicher, dass Sie einen SSH-Client auf Ihrem Laptop
installiert haben. Lesen Sie den Abschnitt setup für weitere Details. SSH-Clients sind in der
Regel Befehlszeilen-Tools, bei denen Sie als einziges Argument die
Adresse des entfernten Rechners angeben müssen. Wenn sich Ihr
Benutzername auf dem entfernten System von dem unterscheidet, den Sie
lokal verwenden, müssen Sie auch diesen angeben. Wenn Ihr SSH-Client
über eine grafische Oberfläche verfügt, wie z. B. PuTTY oder MobaXterm,
geben Sie diese Argumente an, bevor Sie auf “Verbinden” klicken Im
Terminal schreiben Sie etwa ssh userName@hostname, wobei
das “@”-Symbol verwendet wird, um die beiden Teile eines einzelnen
Arguments zu trennen.
Öffnen Sie Ihr Terminal oder Ihren grafischen SSH-Client und melden Sie sich mit Ihrem Benutzernamen und dem entfernten Computer, den Sie von der Außenwelt aus erreichen können, cluster.hpc-carpentry.org, am Cluster an.
Denken Sie daran, yourUsername durch Ihren Benutzernamen
oder den von den Dozenten angegebenen zu ersetzen. Möglicherweise werden
Sie nach Ihrem Passwort gefragt. Achtung: Die Zeichen, die Sie nach der
Passwortabfrage eingeben, werden nicht auf dem Bildschirm angezeigt. Die
normale Ausgabe wird fortgesetzt, sobald Sie Enter
drücken.
Wo sind wir?
Sehr oft sind viele Benutzer versucht, sich eine
Hochleistungsrechner-Installation als eine riesige, magische Maschine
vorzustellen. Manchmal gehen sie davon aus, dass der Computer, an dem
sie sich angemeldet haben, der gesamte Computer-Cluster ist. Was
passiert also wirklich? Bei welchem Computer haben wir uns angemeldet?
Der Name des aktuellen Computers, auf dem wir angemeldet sind, kann mit
dem Befehl hostname überprüft werden. (Vielleicht bemerken
Sie auch, dass der aktuelle Hostname auch Teil unserer
Eingabeaufforderung ist)
AUSGABE
login1Was befindet sich in Ihrem Home-Verzeichnis?
Die Systemadministratoren haben Ihr Home-Verzeichnis möglicherweise
mit einigen hilfreichen Dateien, Ordnern und Verknüpfungen (Shortcuts)
zu für Sie reserviertem Speicherplatz auf anderen Dateisystemen
konfiguriert. Schauen Sie sich um und sehen Sie, was Sie finden können.
Tipp: Die Shell-Befehle pwd und ls
können dabei hilfreich sein. Der Inhalt des Home-Verzeichnisses variiert
von Benutzer zu Benutzer. Bitte besprechen Sie alle Unterschiede, die
Sie feststellen, mit Ihren Nachbarn.
Die tiefste Ebene sollte sich unterscheiden:
yourUsername ist eindeutig. Gibt es Unterschiede im Pfad
auf höheren Ebenen?
Wenn Sie beide leere Verzeichnisse haben, werden sie identisch aussehen. Wenn Sie oder Ihr Nachbar das System vorher benutzt haben, kann es Unterschiede geben. Woran arbeiten Sie?
Verwenden Sie pwd (print working directory), um den
aktuellen Verzeichnispfad zu drucken:
Sie können ls (list) ausführen, um den Inhalt des
Verzeichnisses aufzulisten, obwohl es möglich ist, dass nichts angezeigt
wird (wenn keine Dateien bereitgestellt wurden). Um sicher zu gehen,
benutzen Sie das -a Flag, um auch versteckte Dateien
anzuzeigen.
Dies zeigt zumindest das aktuelle Verzeichnis als . und
das übergeordnete Verzeichnis als .. an.
Knoten
Die einzelnen Computer, aus denen ein Cluster besteht, werden in der Regel Knoten genannt (obwohl man sie auch Server, Rechner und Maschinen nennen kann). In einem Cluster gibt es verschiedene Arten von Knoten für verschiedene Arten von Aufgaben. Der Knoten, an dem Sie sich gerade befinden, wird Kopfknoten, Anmeldeknoten, Landeplatz oder Übermittlungsknoten genannt. Ein Anmeldeknoten dient als Zugangspunkt zum Cluster.
Als Gateway ist er gut geeignet, um Dateien hoch- und herunterzuladen, Software einzurichten und schnelle Tests durchzuführen. Im Allgemeinen sollte der Login-Knoten nicht für zeit- oder ressourcenintensive Aufgaben verwendet werden. Sie sollten darauf achten und sich bei den Betreibern Ihrer Website oder in der Dokumentation darüber informieren, was erlaubt ist und was nicht. In diesen Lektionen werden wir es vermeiden, Aufträge auf dem Hauptknoten auszuführen.
Dedizierte Transferknoten
Wenn Sie größere Datenmengen in oder aus dem Cluster übertragen wollen, bieten einige Systeme dedizierte Knoten nur für Datentransfers an. Die Motivation dafür liegt darin, dass größere Datentransfers den Betrieb des Login-Knotens für alle anderen nicht behindern sollen. Erkundigen Sie sich in der Dokumentation Ihres Clusters oder bei dessen Support-Team, ob ein solcher Transferknoten verfügbar ist. Als Faustregel gilt, dass alle Übertragungen eines Volumens größer als 500 MB bis 1 GB als groß zu betrachten sind. Diese Zahlen können sich jedoch ändern, z.B. abhängig von der Netzwerkverbindung von Ihnen und Ihrem Cluster oder anderen Faktoren.
Die eigentliche Arbeit in einem Cluster wird von den Arbeiterknoten (oder Rechenknoten) erledigt. Arbeiterknoten gibt es in vielen Formen und Größen, aber im Allgemeinen sind sie für lange oder schwierige Aufgaben bestimmt, die viele Rechenressourcen erfordern.
Die gesamte Interaktion mit den Arbeiterknoten wird von einer speziellen Software namens Scheduler abgewickelt (der Scheduler, der in dieser Lektion verwendet wird, heißt Slurm). Wir werden in der nächsten Lektion mehr darüber lernen, wie man den Scheduler benutzt, um Jobs zu übermitteln, aber für den Moment kann er uns auch mehr Informationen über die Arbeiterknoten liefern.
Zum Beispiel können wir alle Arbeiterknoten anzeigen, indem wir den
Befehl sinfo ausführen.
AUSGABE
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
cpubase_bycore_b1* up infinite 4 idle node[1-2],smnode[1-2]
node up infinite 2 idle node[1-2]
smnode up infinite 2 idle smnode[1-2]Es gibt auch spezialisierte Maschinen, die für die Verwaltung von Plattenspeicher, Benutzerauthentifizierung und andere infrastrukturbezogene Aufgaben verwendet werden. Obwohl wir uns normalerweise nicht direkt an diesen Maschinen anmelden oder mit ihnen interagieren, ermöglichen sie eine Reihe von Schlüsselfunktionen, wie z.B. die Sicherstellung, dass unser Benutzerkonto und unsere Dateien im gesamten HPC-System verfügbar sind.
Was befindet sich in einem Knoten?
Alle Knoten in einem HPC-System haben die gleichen Komponenten wie Ihr eigener Laptop oder Desktop: CPUs (manchmal auch Prozessoren oder Cores genannt), Speicher (oder RAM) und Festplattenspeicher. CPUs sind das Werkzeug eines Computers, um Programme und Berechnungen auszuführen. Informationen über eine aktuelle Aufgabe werden im Arbeitsspeicher des Computers gespeichert. Der Begriff “Festplatte” bezieht sich auf den gesamten Speicher, auf den wie auf ein Dateisystem zugegriffen werden kann. In der Regel handelt es sich dabei um Speicher, der Daten dauerhaft speichern kann, d. h. die Daten sind auch dann noch vorhanden, wenn der Computer neu gestartet wurde. Während dieser Speicher lokal sein kann (eine Festplatte ist darin installiert), ist es üblicher, dass Knoten mit einem gemeinsam genutzten, entfernten Dateiserver oder einem Cluster von Servern verbunden sind.
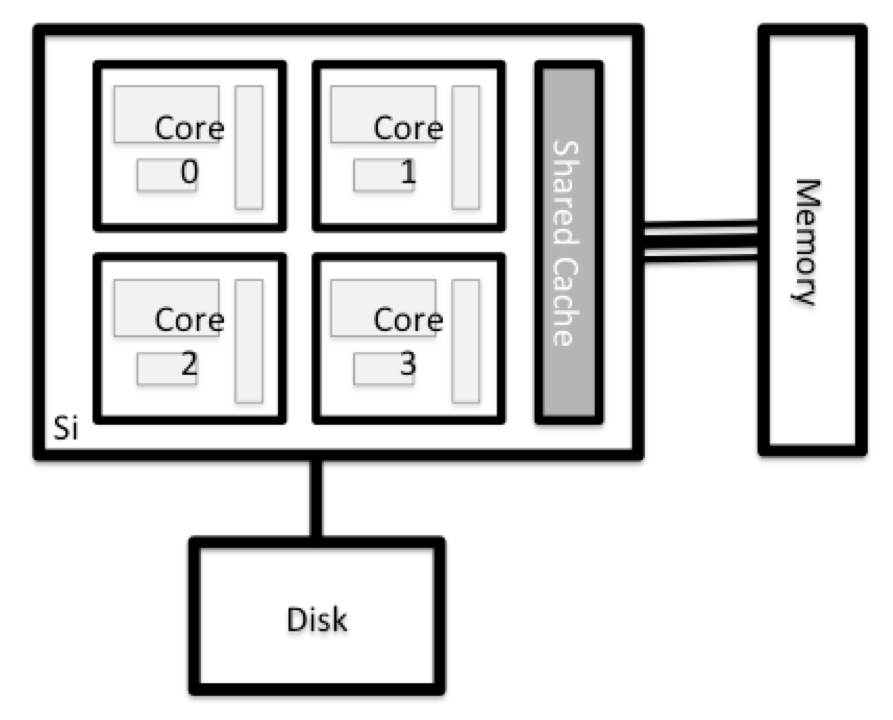
Untersuche deinen Computer
Versuchen Sie herauszufinden, wie viele CPUs und wie viel
Arbeitsspeicher auf Ihrem persönlichen Computer verfügbar sind. Beachten
Sie, dass Sie sich zuerst abmelden müssen, wenn Sie bei dem entfernten
Computer-Cluster angemeldet sind. Geben Sie dazu Ctrl+d
oder exit ein:
Es gibt mehrere Möglichkeiten, dies zu tun. Die meisten Betriebssysteme haben einen grafischen Systemmonitor, wie den Windows Task Manager. Ausführlichere Informationen können manchmal über die Befehlszeile abgerufen werden. Einige der Befehle, die auf einem Linux-System verwendet werden, sind zum Beispiel:
Systemdienstprogramme ausführen
Lesen von /proc
Verwenden Sie einen Systemmonitor
Erkundung des Anmeldeknotens
Vergleichen Sie nun die Ressourcen Ihres Computers mit denen des Hauptknotens.
BASH
[you@laptop:~]$ ssh yourUsername@cluster.hpc-carpentry.org
[yourUsername@login1 ~] nproc --all
[yourUsername@login1 ~] free -mSie können mehr Informationen über die Prozessoren erhalten, indem
Sie lscpu benutzen, und eine Menge Details über den
Speicher, indem Sie die Datei /proc/meminfo lesen:
Sie können auch die verfügbaren Dateisysteme mit df
(disk freespace )untersuchen, um Festplattenspeicher anzuzeigen. Das
Flag -h zeigt die Größen in einem menschenfreundlichen
Format an, d.h. GB statt B. Das type Flag -T zeigt, welche
Art von Dateisystem jede Ressource ist.
Die lokalen Dateisysteme (ext, tmp, xfs, zfs) hängen davon ab, ob Sie sich auf demselben Anmeldeknoten (oder Rechenknoten, später) befinden. Netzwerk-Dateisysteme (beegfs, cifs, gpfs, nfs, pvfs) werden ähnlich sein — können aber yourUsername enthalten, abhängig davon, wie es [gemountet] wird (https://en.wikipedia.org/wiki/Mount_(computing)).
Gemeinsame Dateisysteme
Dies ist ein wichtiger Punkt: Dateien, die auf einem Knoten (Computer) gespeichert sind, sind oft überall im Cluster verfügbar!
Vergleichen Sie Ihren Computer, den Anmeldeknoten und den Berechnungsknoten
Vergleichen Sie die Anzahl der Prozessoren und des Arbeitsspeichers Ihres Laptops mit den Zahlen, die Sie auf dem Hauptknoten und dem Arbeitsknoten des Clusters sehen. Diskutieren Sie die Unterschiede mit Ihrem Nachbarn.
Was denken Sie, welche Auswirkungen die Unterschiede auf die Durchführung Ihrer Forschungsarbeit auf den verschiedenen Systemen und Knotenpunkten haben könnten?
Unterschiede zwischen den Knoten
Viele HPC-Cluster haben eine Vielzahl von Knoten, die für bestimmte Arbeitslasten optimiert sind. Einige Knoten verfügen über eine größere Speichermenge oder spezialisierte Ressourcen wie grafische Verarbeitungseinheiten (GPUs).
Mit all dem im Hinterkopf werden wir nun besprechen, wie man mit dem Scheduler des Clusters kommuniziert und ihn benutzt, um unsere Skripte und Programme laufen zu lassen!
- “Ein HPC-System ist eine Gruppe von vernetzten Maschinen.”
- “HPC-Systeme bieten normalerweise Anmeldeknoten und eine Reihe von Arbeitsknoten.”
- “Die Ressourcen, die sich auf unabhängigen (Arbeits-)Knoten befinden, können in Umfang und Art variieren (Menge des Arbeitsspeichers, Prozessorarchitektur, Verfügbarkeit von im Netzwerk eingebundenen Dateisystemen usw.).”
- “Dateien, die auf einem Knoten gespeichert sind, sind auf allen Knoten verfügbar.”