Content from Warum einen Cluster verwenden?
Zuletzt aktualisiert am 2026-02-26 | Diese Seite bearbeiten
Übersicht
Fragen
- Warum sollte ich mich für High Performance Computing (HPC) interessieren?
- Was kann ich von diesem Kurs erwarten?
Ziele
- Beschreiben Sie, was ein HPC-System ist
- Ermitteln Sie, welchen Nutzen ein HPC-System für Sie haben könnte.
Häufig wachsen Forschungsprobleme, die mit Hilfe von Computern bearbeitet werden, über die Möglichkeiten des Desktop- oder Laptop-Computers hinaus, auf dem sie begonnen haben:
- Ein Statistikstudent möchte ein Modell kreuzvalidieren. Dazu muss das Modell 1000 Mal ausgeführt werden, aber jeder Durchlauf dauert eine Stunde. Die Ausführung des Modells auf einem Laptop würde über einen Monat dauern! Bei diesem Forschungsproblem werden die Endergebnisse berechnet, nachdem alle 1000 Modelle gelaufen sind, aber normalerweise wird immer nur ein Modell (in Serie) auf dem Laptop ausgeführt. Da jeder der 1000 Durchläufe unabhängig von den anderen ist, ist es theoretisch möglich, sie alle gleichzeitig (parallel) laufen zu lassen, wenn genügend Computer vorhanden sind.
- Ein Genomforscher hat bisher mit kleinen Datensätzen von Sequenzdaten gearbeitet, wird aber bald eine neue Art von Sequenzierungsdaten erhalten, die zehnmal so groß sind. Es ist bereits eine Herausforderung, die Datensätze auf einem Computer zu öffnen - die Analyse dieser größeren Datensätze wird ihn wahrscheinlich zum Absturz bringen. Bei diesem Forschungsproblem könnten die erforderlichen Berechnungen nicht parallelisiert werden, aber ein Computer mit mehr Speicher wäre erforderlich, um den viel größeren zukünftigen Datensatz zu analysieren.
- Ein Ingenieur verwendet ein Strömungsdynamik-Paket, das über eine Option zur parallelen Ausführung verfügt. Bislang wurde diese Option auf einem Desktop nicht genutzt. Bei der Umstellung von 2D- auf 3D-Simulationen hat sich die Simulationszeit mehr als verdreifacht. Es könnte nützlich sein, diese Option oder Funktion zu nutzen. Bei diesem Forschungsproblem sind die Berechnungen in jeder Region der Simulation weitgehend unabhängig von den Berechnungen in anderen Regionen der Simulation. Es ist möglich, die Berechnungen in jeder Region gleichzeitig (parallel) auszuführen, ausgewählte Ergebnisse je nach Bedarf an benachbarte Regionen weiterzugeben und die Berechnungen zu wiederholen, um zu einem endgültigen Satz von Ergebnissen zu konvergieren. Beim Übergang von einem 2D- zu einem 3D-Modell nimmt sowohl die Datenmenge als auch die Menge der Berechnungen stark zu, und es ist theoretisch möglich, die Berechnungen auf mehrere Computer zu verteilen, die über ein gemeinsames Netzwerk kommunizieren.
In all diesen Fällen ist der Zugang zu mehr (und größeren) Computern erforderlich. Diese Rechner sollten gleichzeitig nutzbar sein, um parallel die Probleme vieler Forscher zu lösen.
Jargon Busting Präsentation
Öffnen Sie den HPC Jargon Buster
in einer neuen Registerkarte. Um den Inhalt zu präsentieren, drücken Sie
C, um eine clone in einem separaten
Fenster zu öffnen, und drücken Sie dann P, um den
Darstellungsmodus (presentation) umzuschalten.
Ich habe noch nie einen Server benutzt, oder?
Nehmen Sie sich eine Minute Zeit und überlegen Sie, für welche Ihrer täglichen Interaktionen mit einem Computer Sie möglicherweise einen entfernten Server oder sogar einen Cluster benötigen, um Ergebnisse zu erhalten.
- Abrufen von E-Mails: Ihr Computer (möglicherweise in Ihrer Hosentasche) kontaktiert einen entfernten Rechner, authentifiziert sich und lädt eine Liste neuer Nachrichten herunter; außerdem werden Änderungen des Nachrichtenstatus hochgeladen, z. B. ob Sie die Nachricht gelesen, als Junk markiert oder gelöscht haben. Da Ihr Konto nicht das einzige ist, ist der Mailserver wahrscheinlich einer von vielen in einem Rechenzentrum.
- Bei der Online-Suche nach einem Begriff wird der Suchbegriff mit einer umfangreichen Datenbank aller bekannten Websites verglichen und nach Übereinstimmungen gesucht. Diese “Abfrage” kann ganz einfach sein, aber der Aufbau dieser Datenbank ist eine monumentale Aufgabe! Bei jedem Schritt sind Server beteiligt.
- Bei der Suche nach einer Wegbeschreibung auf einer Karten-Website werden (A) Start- und (B) Endpunkt durch Durchqueren eines Graphen verbunden, um den “kürzesten” Weg nach Entfernung, Zeit, Kosten oder einer anderen Metrik zu finden. Die Umwandlung einer Karte in die richtige Form ist relativ einfach, aber die Berechnung aller möglichen Routen zwischen A und B ist aufwendig.
Das Abrufen von E-Mails könnte seriell sein: Ihr Rechner verbindet sich mit einem Server und tauscht Daten aus. Eine Suche durch Abfrage der Datenbank nach Ihrem Suchbegriff (oder Endpunkten) könnte ebenfalls seriell sein, da ein Rechner Ihre Anfrage erhält und das Ergebnis zurückgibt. Das Zusammenstellen und Speichern der gesamten Datenbank übersteigt jedoch bei weitem die Möglichkeiten eines einzelnen Rechners. Daher werden diese Funktionen parallel von einer großen, “hyperscale” Sammlung von Servern ausgeführt, die zusammenarbeiten.
- Beim High Performance Computing (HPC) wird in der Regel eine Verbindung zu sehr großen Rechensystemen an anderen Orten der Welt hergestellt.
- Diese anderen Systeme können für Arbeiten verwendet werden, die auf kleineren Systemen entweder unmöglich oder sehr viel langsamer wären.
- HPC-Ressourcen werden von mehreren Benutzern gemeinsam genutzt.
- Die Standardmethode zur Interaktion mit solchen Systemen erfolgt über eine Befehlszeilenschnittstelle.
Content from Verbinden mit einem entfernten HPC-System
Zuletzt aktualisiert am 2026-02-26 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie melde ich mich bei einem entfernten HPC-System an?
Ziele
- Konfigurieren Sie den sicheren Zugriff auf ein entferntes HPC-System.
- Verbinden Sie sich mit einem entfernten HPC-System.
Sichere Verbindungen
Der erste Schritt bei der Nutzung eines Clusters besteht darin, eine Verbindung von unserem Laptop zum Cluster herzustellen. Wenn wir an einem Computer sitzen (oder stehen oder ihn in der Hand oder am Handgelenk halten), erwarten wir eine visuelle Anzeige mit Symbolen, Widgets und vielleicht einigen Fenstern oder Anwendungen: eine grafische Benutzeroberfläche, oder GUI. Da es sich bei Computerclustern um entfernte Ressourcen handelt, mit denen wir uns über langsame oder unregelmäßige Schnittstellen (insbesondere WiFi und VPNs) verbinden, ist es praktischer, eine Befehlszeilenschnittstelle (CLI) zu verwenden, um Befehle im Klartext zu senden. Wenn ein Befehl eine Ausgabe zurückgibt, wird diese ebenfalls im Klartext ausgedruckt. Die Befehle, die wir heute ausführen, werden kein Fenster öffnen, um die Ergebnisse grafisch darzustellen.
Wenn Sie jemals die Windows-Eingabeaufforderung oder das macOS-Terminal geöffnet haben, haben Sie eine CLI gesehen. Wenn Sie bereits an den The Carpentries-Kursen über die UNIX-Shell oder Versionskontrolle teilgenommen haben, haben Sie die CLI auf Ihrem lokalen Rechner ausgiebig genutzt. Der einzige Sprung, den Sie hier machen müssen, ist das Öffnen einer CLI auf einem entfernten Rechner, wobei Sie einige Vorsichtsmaßnahmen treffen müssen, damit andere Leute im Netzwerk die Befehle, die Sie ausführen, oder die Ergebnisse, die der entfernte Rechner zurückschickt, nicht sehen (oder ändern) können. Wir werden das Secure SHell-Protokoll (oder SSH) verwenden, um eine verschlüsselte Netzwerkverbindung zwischen zwei Rechnern zu öffnen, die es Ihnen ermöglicht, Text und Daten zu senden und zu empfangen, ohne sich um neugierige Blicke sorgen zu müssen.

SSH-Clients sind in der Regel Kommandozeilenprogramme, bei denen Sie
als einziges Argument die Adresse des entfernten Rechners angeben
müssen. Wenn sich Ihr Benutzername auf dem entfernten System von dem
unterscheidet, den Sie lokal verwenden, müssen Sie auch diesen angeben.
Wenn Ihr SSH-Client über eine grafische Oberfläche verfügt, wie z. B.
PuTTY oder MobaXterm, geben Sie diese Argumente an, bevor Sie auf
“Verbinden” klicken Im Terminal schreiben Sie etwas wie
ssh userName@hostname, wobei das Argument wie eine
E-Mail-Adresse ist: das “@”-Symbol wird verwendet, um die persönliche ID
von der Adresse des entfernten Rechners zu trennen.
Bei der Anmeldung an einem Laptop, Tablet oder einem anderen
persönlichen Gerät sind normalerweise ein Benutzername, ein Kennwort
oder ein Muster erforderlich, um unbefugten Zugriff zu verhindern. In
diesen Situationen ist die Wahrscheinlichkeit, dass jemand anderes Ihr
Passwort abfängt, gering, da die Aufzeichnung Ihrer Tastenanschläge
einen böswilligen Exploit oder physischen Zugang erfordert. Bei Systemen
wie login1, auf denen ein SSH-Server läuft, kann sich jeder
im Netzwerk anmelden oder dies versuchen. Da Benutzernamen oft
öffentlich oder leicht zu erraten sind, ist Ihr Passwort oft das
schwächste Glied in der Sicherheitskette. Viele Cluster verbieten daher
die passwortbasierte Anmeldung und verlangen stattdessen, dass Sie ein
öffentlich-privates Schlüsselpaar mit einem viel stärkeren Passwort
erzeugen und konfigurieren. Auch wenn Ihr Cluster dies nicht
vorschreibt, wird der nächste Abschnitt Sie durch die Verwendung von
SSH-Schlüsseln und eines SSH-Agenten führen, um sowohl Ihre Sicherheit
zu erhöhen als auch die Anmeldung bei entfernten Systemen zu
erleichtern.
Bessere Sicherheit mit SSH-Schlüsseln
Die Lesson Setup enthält Anweisungen für die Installation einer Shell-Anwendung mit SSH. Falls Sie dies noch nicht getan haben, öffnen Sie bitte diese Shell-Anwendung mit einer Unix-ähnlichen Kommandozeilenschnittstelle auf Ihrem System.
SSH-Schlüssel sind eine alternative Methode zur Authentifizierung, um Zugang zu entfernten Computersystemen zu erhalten. Sie können auch zur Authentifizierung bei der Übertragung von Dateien oder für den Zugriff auf entfernte Versionskontrollsysteme (wie GitHub) verwendet werden. In diesem Abschnitt werden Sie ein Paar SSH-Schlüssel erstellen:
- ein privater Schlüssel, den Sie auf Ihrem eigenen Computer aufbewahren, und
- ein öffentlicher Schlüssel, der auf jedem entfernten System platziert werden kann, auf das Sie zugreifen wollen.
Private Schlüssel sind Ihr sicherer digitaler Reisepass
Ein privater Schlüssel, der für jeden außer Ihnen sichtbar ist, sollte als kompromittiert betrachtet werden und muss vernichtet werden. Dazu gehören unzulässige Rechte für das Verzeichnis, in dem er (oder eine Kopie) gespeichert ist, das Durchqueren eines nicht sicheren (verschlüsselten) Netzwerks, der Anhang einer unverschlüsselten E-Mail und sogar die Anzeige des Schlüssels in Ihrem Terminalfenster.
Schützen Sie diesen Schlüssel, als ob er Ihre Haustür aufschließen würde. In vielerlei Hinsicht tut er das auch.
Unabhängig von der Software oder dem Betriebssystem, das Sie verwenden, bitte wählen Sie ein starkes Passwort oder eine Passphrase, um Ihren privaten SSH-Schlüssel zusätzlich zu schützen.
Überlegungen zu SSH-Schlüsselpasswörtern
Wenn Sie dazu aufgefordert werden, geben Sie ein sicheres Passwort ein, das Sie sich merken können. Hierfür gibt es zwei gängige Ansätze:
- Erstellen Sie eine einprägsame Passphrase mit einigen Interpunktionszeichen und Buchstaben-Zahlen-Ersetzungen, 32 Zeichen oder länger. Straßenadressen eignen sich gut; seien Sie jedoch vorsichtig mit Social-Engineering- oder Public-Records-Angriffen.
- Verwenden Sie einen Passwort-Manager und seinen eingebauten Passwort-Generator mit allen Zeichenklassen, 25 Zeichen oder länger. KeePass und BitWarden sind zwei gute Optionen.
- Nichts ist weniger sicher als ein privater Schlüssel ohne Passwort. Wenn Sie die Passworteingabe versehentlich übersprungen haben, gehen Sie zurück und erzeugen Sie ein neues Schlüsselpaar mit einem starken Passwort.
SSH-Schlüssel auf Linux, Mac, MobaXterm und Windows Subsystem für Linux
Sobald Sie ein Terminal geöffnet haben, prüfen Sie, ob bereits SSH-Schlüssel und Dateinamen vorhanden sind, da vorhandene SSH-Schlüssel überschrieben werden.
Wenn ~/.ssh/id_ed25519 bereits existiert, müssen Sie
einen anderen Namen für das neue Schlüsselpaar angeben.
Erzeugen Sie ein neues Schlüsselpaar aus öffentlichem und privatem
Schlüssel mit dem folgenden Befehl, der einen stärkeren Schlüssel als
den Standardschlüssel ssh-keygen erzeugt, indem Sie diese
Flags aufrufen:
-
-a(Standardwert ist 16): Anzahl der Runden der Passphrasenableitung; erhöhen Sie diese, um Brute-Force-Angriffe zu verlangsamen. -
-t(Standard ist rsa): Geben Sie den “Typ” oder kryptographischen Algorithmus an.ed25519spezifiziert EdDSA mit einem 256-Bit-Schlüssel; er ist schneller als RSA mit einer vergleichbaren Stärke. -
-f(Standard ist /home/user/.ssh/id_algorithm): Dateiname zum Speichern Ihres privaten Schlüssels. Der Dateiname des öffentlichen Schlüssels ist identisch, mit der Erweiterung.pub.
Wenn Sie dazu aufgefordert werden, geben Sie ein sicheres Passwort ein, das die obigen Überlegungen berücksichtigt
Beachten Sie, dass sich das Terminal nicht zu ändern scheint, während Sie das Passwort eingeben: Das ist zu Ihrer Sicherheit so gewollt. Sie werden aufgefordert, es noch einmal einzugeben, also machen Sie sich nicht zu viele Gedanken über Tippfehler.
Werfen Sie einen Blick in ~/.ssh (verwenden Sie
ls ~/.ssh). Sie sollten zwei neue Dateien sehen:
- Ihr privater Schlüssel (
~/.ssh/id_ed25519): do not share with anyone! - den gemeinsam nutzbaren öffentlichen Schlüssel
(
~/.ssh/id_ed25519.pub): Wenn ein Systemadministrator nach einem Schlüssel fragt, ist dies der Schlüssel, den Sie senden müssen. Es ist auch sicher, ihn auf Websites wie GitHub hochzuladen: Er ist dafür gedacht, gesehen zu werden.
Verwenden Sie RSA für ältere Systeme
Wenn die Schlüsselerzeugung fehlgeschlagen ist, weil ed25519 nicht verfügbar ist, versuchen Sie es mit dem älteren (aber immer noch starken und vertrauenswürdigen) RSA Kryptosystem. Prüfen Sie auch hier zunächst, ob ein Schlüssel vorhanden ist:
Wenn ~/.ssh/id_rsa bereits existiert, müssen Sie einen
anderen Namen für das neue Schlüsselpaar wählen. Erzeugen Sie es wie
oben, mit den folgenden zusätzlichen Flags:
-
-blegt die Anzahl der Bits des Schlüssels fest. Die Vorgabe ist 2048. EdDSA verwendet eine feste Schlüssellänge, so dass dieses Flag keine Auswirkung haben würde. -
-o(kein Standard): Verwenden Sie das OpenSSH-Schlüsselformat, anstatt PEM.
Wenn Sie dazu aufgefordert werden, geben Sie ein sicheres Passwort ein und beachten Sie dabei die oben genannten Überlegungen.
Werfen Sie einen Blick in ~/.ssh (verwenden Sie
ls ~/.ssh). Sie sollten zwei neue Dateien sehen:
- Ihr privater Schlüssel (
~/.ssh/id_rsa): do not share with anyone! - den gemeinsam nutzbaren öffentlichen Schlüssel
(
~/.ssh/id_rsa.pub): Wenn ein Systemadministrator nach einem Schlüssel fragt, ist dies der Schlüssel, den Sie senden müssen. Es ist auch sicher, ihn auf Websites wie GitHub hochzuladen: Er ist dafür gedacht, gesehen zu werden.
SSH-Schlüssel auf PuTTY
Wenn Sie PuTTY unter Windows verwenden, laden Sie
puttygen herunter und verwenden Sie es, um das
Schlüsselpaar zu erzeugen. Siehe die PuTTY-Dokumentation
für Details.
- Wählen Sie
EdDSAals Schlüsseltyp. - Wählen Sie
255als Schlüsselgröße oder -stärke. - Klicken Sie auf die Schaltfläche “Generate”.
- Sie müssen keinen Kommentar eingeben.
- Wenn Sie dazu aufgefordert werden, geben Sie ein sicheres Passwort ein und beachten Sie dabei die oben genannten Überlegungen.
- Speichern Sie die Schlüssel in einem Ordner, den kein anderer Benutzer des Systems lesen kann.
Werfen Sie einen Blick in den von Ihnen angegebenen Ordner. Sie sollten zwei neue Dateien sehen:
- Ihr privater Schlüssel (
id_ed25519): do not share with anyone! - den gemeinsam nutzbaren öffentlichen Schlüssel
(
id_ed25519.pub): Wenn ein Systemadministrator nach einem Schlüssel fragt, ist dies der Schlüssel, den Sie senden müssen. Es ist auch sicher, ihn auf Websites wie GitHub hochzuladen: Er ist dafür gedacht, gesehen zu werden.
SSH Agent für einfachere Schlüsselverwaltung
Ein SSH-Schlüssel ist nur so stark wie das Passwort, mit dem er entsperrt wird. Andererseits ist es mühsam, jedes Mal ein komplexes Passwort einzugeben, wenn man sich mit einem Rechner verbindet, und wird schnell langweilig. An dieser Stelle kommt der SSH-Agent ins Spiel.
Wenn Sie einen SSH-Agenten verwenden, können Sie Ihr Passwort für den privaten Schlüssel einmal eingeben und dann den Agenten veranlassen, es für eine bestimmte Anzahl von Stunden oder bis zu Ihrer Abmeldung zu speichern. Solange kein böswilliger Akteur physischen Zugang zu Ihrem Rechner hat, ist das Kennwort auf diese Weise sicher, und Sie müssen das Kennwort nicht mehrmals eingeben.
Merken Sie sich Ihr Passwort, denn sobald es im Agenten abläuft, müssen Sie es erneut eingeben.
SSH-Agenten auf Linux, macOS und Windows
Öffnen Sie Ihr Terminalprogramm und prüfen Sie, ob ein Agent läuft:
-
Wenn Sie eine Fehlermeldung wie diese erhalten,
FEHLER
Error connecting to agent: No such file or directory… dann müssen Sie den Agenten wie folgt starten:
WichtigWas ist in einem
$(...)?Die Syntax dieses SSH-Agent-Befehls ist ungewöhnlich, basierend auf dem, was wir in der UNIX-Shell-Lektion gesehen haben. Das liegt daran, dass der
ssh-agent-Befehl eine Verbindung öffnet, auf die nur Sie Zugriff haben, und eine Reihe von Shell-Befehlen ausgibt, die verwendet werden können, um sie zu erreichen - aber sie werden nicht ausgeführt!AUSGABE
SSH_AUTH_SOCK=/tmp/ssh-Zvvga2Y8kQZN/agent.131521; export SSH_AUTH_SOCK; SSH_AGENT_PID=131522; export SSH_AGENT_PID; echo Agent pid 131522;Der Befehl
evalinterpretiert diese Textausgabe als Befehle und ermöglicht Ihnen den Zugriff auf die gerade erstellte SSH-Agent-Verbindung.Sie könnten jede Zeile der
ssh-agent-Ausgabe selbst ausführen und das gleiche Ergebnis erzielen. Die Verwendung vonevalmacht dies nur einfacher. Andernfalls läuft Ihr Agent bereits: Lassen Sie ihn in Ruhe.
Fügen Sie Ihren Schlüssel zum Agenten hinzu, wobei die Sitzung nach 8 Stunden abläuft:
AUSGABE
Enter passphrase for .ssh/id_ed25519:
Identity added: .ssh/id_ed25519
Lifetime set to 86400 secondsWährend der Dauer (8 Stunden) wird der SSH-Agent bei jeder Verwendung dieses Schlüssels den Schlüssel für Sie bereitstellen, ohne dass Sie einen einzigen Tastendruck eingeben müssen.
SSH-Agent auf PuTTY
Wenn Sie PuTTY unter Windows verwenden, laden Sie
pageant herunter und verwenden Sie es als SSH-Agent. Siehe
die PuTTY-Dokumentation.
Einloggen in den Cluster
Öffnen Sie Ihr Terminal oder Ihren grafischen SSH-Client und melden
Sie sich beim Cluster an. Ersetzen Sie yourUsername durch
Ihren Benutzernamen oder den von den Lehrkräften angegebenen.
Sie werden möglicherweise nach Ihrem Passwort gefragt. Achtung: Die
Zeichen, die Sie nach der Passwortabfrage eingeben, werden nicht auf dem
Bildschirm angezeigt. Die normale Ausgabe wird fortgesetzt, sobald Sie
Enter drücken.
Sie haben vielleicht bemerkt, dass sich die Eingabeaufforderung
geändert hat, als Sie sich mit dem Terminal beim entfernten System
angemeldet haben (wenn Sie sich mit PuTTY angemeldet haben, gilt dies
nicht, da PuTTY kein lokales Terminal anbietet). Diese Änderung ist
wichtig, weil sie Ihnen helfen kann, zu unterscheiden, auf welchem
System die von Ihnen eingegebenen Befehle ausgeführt werden, wenn Sie
sie an das Terminal übergeben. Diese Änderung ist auch eine kleine
Komplikation, mit der wir uns im Laufe des Workshops auseinandersetzen
müssen. Was genau als Eingabeaufforderung (die üblicherweise mit
$ endet) im Terminal angezeigt wird, wenn es mit dem
lokalen System und dem entfernten System verbunden ist, wird
normalerweise für jeden Benutzer unterschiedlich sein. Wir müssen aber
trotzdem angeben, auf welchem System wir Befehle eingeben, also werden
wir die folgende Konvention anwenden:
-
[you@laptop:~]$, wenn der Befehl auf einem Terminal eingegeben werden soll, das mit Ihrem lokalen Computer verbunden ist -
[yourUsername@login1 ~], wenn der Befehl auf einem Terminal eingegeben werden soll, das mit dem entfernten System verbunden ist -
$, wenn es wirklich keine Rolle spielt, mit welchem System das Terminal verbunden ist.
Schauen Sie sich in Ihrem Remote Home um
Sehr oft sind viele Benutzer versucht, sich eine
Hochleistungsrechner-Installation als eine riesige, magische Maschine
vorzustellen. Manchmal nehmen sie an, dass der Computer, an dem sie sich
angemeldet haben, der gesamte Computer-Cluster ist. Was passiert also
wirklich? Bei welchem Computer haben wir uns angemeldet? Der Name des
aktuellen Computers, auf dem wir angemeldet sind, kann mit dem Befehl
hostname überprüft werden. (Vielleicht bemerken Sie auch,
dass der aktuelle Hostname auch Teil unserer Eingabeaufforderung
ist)
AUSGABE
login1Wir befinden uns also definitiv auf dem entfernten Rechner. Als
Nächstes wollen wir herausfinden, wo wir uns befinden, indem wir
pwd ausführen, um das Arbeitsverzeichnis (print working
directory) auszugeben.
AUSGABE
/home/yourUsernameGroßartig, wir wissen, wo wir sind! Schauen wir mal, was sich in unserem aktuellen Verzeichnis befindet:
AUSGABE
id_ed25519.pubDie Systemadministratoren haben möglicherweise Ihr Home-Verzeichnis mit einigen hilfreichen Dateien, Ordnern und Verknüpfungen (Shortcuts) zu für Sie reserviertem Speicherplatz auf anderen Dateisystemen konfiguriert. Wenn dies nicht der Fall ist, kann Ihr Home-Verzeichnis leer erscheinen. Um dies zu überprüfen, nehmen Sie versteckte Dateien in Ihre Verzeichnisliste auf:
AUSGABE
. .bashrc id_ed25519.pub
.. .sshIn der ersten Spalte ist . ein Verweis auf das aktuelle
Verzeichnis und .. ein Verweis auf dessen übergeordnetes
Verzeichnis (/home). Sie können die anderen Dateien oder
ähnliche Dateien sehen, müssen es aber nicht: .bashrc ist
eine Shell-Konfigurationsdatei, die Sie mit Ihren Präferenzen bearbeiten
können; und .ssh ist ein Verzeichnis, das SSH-Schlüssel und
eine Aufzeichnung der autorisierten Verbindungen speichert.
Installieren Sie Ihren SSH-Schlüssel
Es gibt vielleicht einen besseren Weg
Die Richtlinien und Praktiken für den Umgang mit SSH-Schlüsseln variieren von HPC-Cluster zu HPC-Cluster: Befolgen Sie die von den Cluster-Administratoren oder der Dokumentation bereitgestellten Hinweise. Insbesondere wenn es ein Online-Portal für die Verwaltung von SSH-Schlüsseln gibt, verwenden Sie dieses anstelle der hier beschriebenen Anweisungen.
Wenn Sie Ihren öffentlichen SSH-Schlüssel mit scp
übertragen haben, sollten Sie id_ed25519.pub in Ihrem
Home-Verzeichnis sehen. Um diesen Schlüssel zu “installieren”, muss er
in einer Datei namens authorized_keys unter dem Ordner
.ssh aufgeführt sein.
Wenn der Ordner .ssh oben nicht aufgeführt wurde, dann
existiert er noch nicht: Erstellen Sie ihn.
Verwenden Sie nun cat, um Ihren öffentlichen Schlüssel
zu drucken, aber leiten Sie die Ausgabe um, indem Sie sie an die Datei
authorized_keys anhängen:
Das war’s! Trennen Sie die Verbindung und versuchen Sie dann, sich wieder bei der Gegenstelle anzumelden: Wenn Ihr Schlüssel und Ihr Agent korrekt konfiguriert wurden, sollten Sie nicht nach dem Passwort für Ihren SSH-Schlüssel gefragt werden.
- Ein HPC-System ist eine Gruppe von vernetzten Maschinen.
- HPC-Systeme bieten typischerweise Login-Knoten und eine Reihe von Worker-Knoten.
- Die Ressourcen auf den unabhängigen (Arbeits-)Knoten können in Umfang und Art variieren (Menge des Arbeitsspeichers, Prozessorarchitektur, Verfügbarkeit von über das Netzwerk eingebundenen Dateisystemen usw.).
- Dateien, die auf einem Knoten gespeichert sind, sind auf allen Knoten verfügbar.
Content from Arbeiten auf einem entfernten HPC-System
Zuletzt aktualisiert am 2026-02-26 | Diese Seite bearbeiten
Übersicht
Fragen
- “Was ist ein HPC-System?”
- “Wie funktioniert ein HPC-System?”
- “Wie melde ich mich bei einem entfernten HPC-System an?”
Ziele
- “Verbinden Sie sich mit einem entfernten HPC-System.”
- “Verstehen Sie die allgemeine HPC-Systemarchitektur.”
Was ist ein HPC-System?
Die Begriffe “Cloud”, “Cluster” und “High-Performance Computing” oder “HPC” werden in verschiedenen Zusammenhängen und mit unterschiedlichen Bedeutungen verwendet. Was bedeuten sie also? Und was noch wichtiger ist: Wie verwenden wir sie bei unserer Arbeit?
Die Cloud ist ein allgemeiner Begriff, der sich auf Computerressourcen bezieht, die a) den Benutzern auf Anfrage oder nach Bedarf zur Verfügung gestellt werden und b) reale oder virtuelle Ressourcen darstellen, die sich überall auf der Erde befinden können. So kann beispielsweise ein großes Unternehmen mit Rechenressourcen in Brasilien, Simbabwe und Japan diese Ressourcen als seine eigene interne Cloud verwalten, und dasselbe Unternehmen kann auch kommerzielle Cloud-Ressourcen von Amazon oder Google nutzen. Cloud-Ressourcen können sich auf Maschinen beziehen, die relativ einfache Aufgaben ausführen, wie z. B. die Bereitstellung von Websites, die Bereitstellung von gemeinsamem Speicherplatz, die Bereitstellung von Webdiensten (z. B. E-Mail oder Social-Media-Plattformen) sowie traditionellere rechenintensive Aufgaben wie die Ausführung einer Simulation.
Der Begriff HPC-System beschreibt dagegen eine eigenständige Ressource für rechenintensive Arbeitslasten. Sie bestehen in der Regel aus einer Vielzahl integrierter Verarbeitungs- und Speicherelemente, die darauf ausgelegt sind, große Datenmengen und/oder eine große Anzahl von Gleitkommaoperationen (FLOPS) mit der höchstmöglichen Leistung zu verarbeiten. So sind zum Beispiel alle Maschinen auf der Top-500 Liste HPC-Systeme. Um diesen Anforderungen gerecht zu werden, muss eine HPC-Ressource an einem bestimmten, festen Standort vorhanden sein: Netzwerkkabel können nur bis zu einem bestimmten Punkt verlegt werden, und elektrische und optische Signale können nur mit einer bestimmten Geschwindigkeit übertragen werden.
Der Begriff “Cluster” wird häufig für kleine bis mittelgroße HPC-Ressourcen verwendet, die weniger beeindruckend sind als die [Top-500] (https://www.top500.org). Cluster werden oft in Rechenzentren unterhalten, die mehrere solcher Systeme unterstützen, die alle ein gemeinsames Netzwerk und einen gemeinsamen Speicher nutzen, um gemeinsame rechenintensive Aufgaben zu unterstützen.
Anmelden
Der erste Schritt bei der Nutzung eines Clusters besteht darin, eine Verbindung zwischen unserem Laptop und dem Cluster herzustellen. Wenn wir an einem Computer sitzen (oder stehen, oder ihn in der Hand oder am Handgelenk halten), erwarten wir eine visuelle Anzeige mit Symbolen, Widgets und vielleicht einigen Fenstern oder Anwendungen: eine grafische Benutzeroberfläche (GUI). Da es sich bei Computerclustern um entfernte Ressourcen handelt, mit denen wir uns über oft langsame oder verzögerte Schnittstellen (insbesondere WiFi und VPNs) verbinden, ist es praktischer, eine Befehlszeilenschnittstelle (CLI) zu verwenden, bei der Befehle und Ergebnisse nur über Text übertragen werden. Alles, was nicht Text ist (z. B. Bilder), muss auf die Festplatte geschrieben und mit einem separaten Programm geöffnet werden.
Wenn Sie jemals die Windows-Eingabeaufforderung oder das macOS-Terminal geöffnet haben, haben Sie ein CLI gesehen. Wenn Sie bereits an den The Carpentries-Kursen über die UNIX-Shell oder Versionskontrolle teilgenommen haben, haben Sie die CLI auf Ihrem lokalen Rechner ziemlich ausgiebig genutzt. Der einzige Schritt, der hier gemacht werden muss, ist das Öffnen einer CLI auf einem entfernten Rechner, wobei einige Vorsichtsmaßnahmen getroffen werden müssen, damit andere Leute im Netzwerk die Befehle, die Sie ausführen, oder die Ergebnisse, die der entfernte Rechner zurücksendet, nicht sehen (oder ändern) können. Wir werden das Secure SHell-Protokoll (oder SSH) verwenden, um eine verschlüsselte Netzwerkverbindung zwischen zwei Rechnern herzustellen, die es Ihnen ermöglicht, Text und Daten zu senden und zu empfangen, ohne sich um neugierige Blicke sorgen zu müssen.

Stellen Sie sicher, dass Sie einen SSH-Client auf Ihrem Laptop
installiert haben. Lesen Sie den Abschnitt setup für weitere Details. SSH-Clients sind in der
Regel Befehlszeilen-Tools, bei denen Sie als einziges Argument die
Adresse des entfernten Rechners angeben müssen. Wenn sich Ihr
Benutzername auf dem entfernten System von dem unterscheidet, den Sie
lokal verwenden, müssen Sie auch diesen angeben. Wenn Ihr SSH-Client
über eine grafische Oberfläche verfügt, wie z. B. PuTTY oder MobaXterm,
geben Sie diese Argumente an, bevor Sie auf “Verbinden” klicken Im
Terminal schreiben Sie etwa ssh userName@hostname, wobei
das “@”-Symbol verwendet wird, um die beiden Teile eines einzelnen
Arguments zu trennen.
Öffnen Sie Ihr Terminal oder Ihren grafischen SSH-Client und melden Sie sich mit Ihrem Benutzernamen und dem entfernten Computer, den Sie von der Außenwelt aus erreichen können, cluster.hpc-carpentry.org, am Cluster an.
Denken Sie daran, yourUsername durch Ihren Benutzernamen
oder den von den Dozenten angegebenen zu ersetzen. Möglicherweise werden
Sie nach Ihrem Passwort gefragt. Achtung: Die Zeichen, die Sie nach der
Passwortabfrage eingeben, werden nicht auf dem Bildschirm angezeigt. Die
normale Ausgabe wird fortgesetzt, sobald Sie Enter
drücken.
Wo sind wir?
Sehr oft sind viele Benutzer versucht, sich eine
Hochleistungsrechner-Installation als eine riesige, magische Maschine
vorzustellen. Manchmal gehen sie davon aus, dass der Computer, an dem
sie sich angemeldet haben, der gesamte Computer-Cluster ist. Was
passiert also wirklich? Bei welchem Computer haben wir uns angemeldet?
Der Name des aktuellen Computers, auf dem wir angemeldet sind, kann mit
dem Befehl hostname überprüft werden. (Vielleicht bemerken
Sie auch, dass der aktuelle Hostname auch Teil unserer
Eingabeaufforderung ist)
AUSGABE
login1Was befindet sich in Ihrem Home-Verzeichnis?
Die Systemadministratoren haben Ihr Home-Verzeichnis möglicherweise
mit einigen hilfreichen Dateien, Ordnern und Verknüpfungen (Shortcuts)
zu für Sie reserviertem Speicherplatz auf anderen Dateisystemen
konfiguriert. Schauen Sie sich um und sehen Sie, was Sie finden können.
Tipp: Die Shell-Befehle pwd und ls
können dabei hilfreich sein. Der Inhalt des Home-Verzeichnisses variiert
von Benutzer zu Benutzer. Bitte besprechen Sie alle Unterschiede, die
Sie feststellen, mit Ihren Nachbarn.
Die tiefste Ebene sollte sich unterscheiden:
yourUsername ist eindeutig. Gibt es Unterschiede im Pfad
auf höheren Ebenen?
Wenn Sie beide leere Verzeichnisse haben, werden sie identisch aussehen. Wenn Sie oder Ihr Nachbar das System vorher benutzt haben, kann es Unterschiede geben. Woran arbeiten Sie?
Verwenden Sie pwd (print working directory), um den
aktuellen Verzeichnispfad zu drucken:
Sie können ls (list) ausführen, um den Inhalt des
Verzeichnisses aufzulisten, obwohl es möglich ist, dass nichts angezeigt
wird (wenn keine Dateien bereitgestellt wurden). Um sicher zu gehen,
benutzen Sie das -a Flag, um auch versteckte Dateien
anzuzeigen.
Dies zeigt zumindest das aktuelle Verzeichnis als . und
das übergeordnete Verzeichnis als .. an.
Knoten
Die einzelnen Computer, aus denen ein Cluster besteht, werden in der Regel Knoten genannt (obwohl man sie auch Server, Rechner und Maschinen nennen kann). In einem Cluster gibt es verschiedene Arten von Knoten für verschiedene Arten von Aufgaben. Der Knoten, an dem Sie sich gerade befinden, wird Kopfknoten, Anmeldeknoten, Landeplatz oder Übermittlungsknoten genannt. Ein Anmeldeknoten dient als Zugangspunkt zum Cluster.
Als Gateway ist er gut geeignet, um Dateien hoch- und herunterzuladen, Software einzurichten und schnelle Tests durchzuführen. Im Allgemeinen sollte der Login-Knoten nicht für zeit- oder ressourcenintensive Aufgaben verwendet werden. Sie sollten darauf achten und sich bei den Betreibern Ihrer Website oder in der Dokumentation darüber informieren, was erlaubt ist und was nicht. In diesen Lektionen werden wir es vermeiden, Aufträge auf dem Hauptknoten auszuführen.
Dedizierte Transferknoten
Wenn Sie größere Datenmengen in oder aus dem Cluster übertragen wollen, bieten einige Systeme dedizierte Knoten nur für Datentransfers an. Die Motivation dafür liegt darin, dass größere Datentransfers den Betrieb des Login-Knotens für alle anderen nicht behindern sollen. Erkundigen Sie sich in der Dokumentation Ihres Clusters oder bei dessen Support-Team, ob ein solcher Transferknoten verfügbar ist. Als Faustregel gilt, dass alle Übertragungen eines Volumens größer als 500 MB bis 1 GB als groß zu betrachten sind. Diese Zahlen können sich jedoch ändern, z.B. abhängig von der Netzwerkverbindung von Ihnen und Ihrem Cluster oder anderen Faktoren.
Die eigentliche Arbeit in einem Cluster wird von den Arbeiterknoten (oder Rechenknoten) erledigt. Arbeiterknoten gibt es in vielen Formen und Größen, aber im Allgemeinen sind sie für lange oder schwierige Aufgaben bestimmt, die viele Rechenressourcen erfordern.
Die gesamte Interaktion mit den Arbeiterknoten wird von einer speziellen Software namens Scheduler abgewickelt (der Scheduler, der in dieser Lektion verwendet wird, heißt Slurm). Wir werden in der nächsten Lektion mehr darüber lernen, wie man den Scheduler benutzt, um Jobs zu übermitteln, aber für den Moment kann er uns auch mehr Informationen über die Arbeiterknoten liefern.
Zum Beispiel können wir alle Arbeiterknoten anzeigen, indem wir den
Befehl sinfo ausführen.
AUSGABE
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
cpubase_bycore_b1* up infinite 4 idle node[1-2],smnode[1-2]
node up infinite 2 idle node[1-2]
smnode up infinite 2 idle smnode[1-2]Es gibt auch spezialisierte Maschinen, die für die Verwaltung von Plattenspeicher, Benutzerauthentifizierung und andere infrastrukturbezogene Aufgaben verwendet werden. Obwohl wir uns normalerweise nicht direkt an diesen Maschinen anmelden oder mit ihnen interagieren, ermöglichen sie eine Reihe von Schlüsselfunktionen, wie z.B. die Sicherstellung, dass unser Benutzerkonto und unsere Dateien im gesamten HPC-System verfügbar sind.
Was befindet sich in einem Knoten?
Alle Knoten in einem HPC-System haben die gleichen Komponenten wie Ihr eigener Laptop oder Desktop: CPUs (manchmal auch Prozessoren oder Cores genannt), Speicher (oder RAM) und Festplattenspeicher. CPUs sind das Werkzeug eines Computers, um Programme und Berechnungen auszuführen. Informationen über eine aktuelle Aufgabe werden im Arbeitsspeicher des Computers gespeichert. Der Begriff “Festplatte” bezieht sich auf den gesamten Speicher, auf den wie auf ein Dateisystem zugegriffen werden kann. In der Regel handelt es sich dabei um Speicher, der Daten dauerhaft speichern kann, d. h. die Daten sind auch dann noch vorhanden, wenn der Computer neu gestartet wurde. Während dieser Speicher lokal sein kann (eine Festplatte ist darin installiert), ist es üblicher, dass Knoten mit einem gemeinsam genutzten, entfernten Dateiserver oder einem Cluster von Servern verbunden sind.
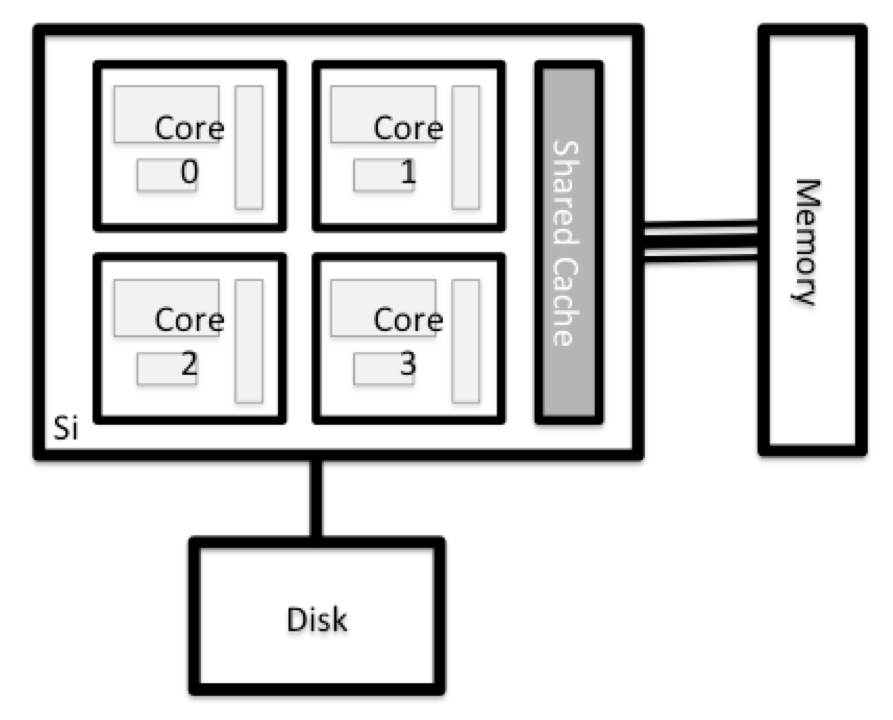
Untersuche deinen Computer
Versuchen Sie herauszufinden, wie viele CPUs und wie viel
Arbeitsspeicher auf Ihrem persönlichen Computer verfügbar sind. Beachten
Sie, dass Sie sich zuerst abmelden müssen, wenn Sie bei dem entfernten
Computer-Cluster angemeldet sind. Geben Sie dazu Ctrl+d
oder exit ein:
Es gibt mehrere Möglichkeiten, dies zu tun. Die meisten Betriebssysteme haben einen grafischen Systemmonitor, wie den Windows Task Manager. Ausführlichere Informationen können manchmal über die Befehlszeile abgerufen werden. Einige der Befehle, die auf einem Linux-System verwendet werden, sind zum Beispiel:
Systemdienstprogramme ausführen
Lesen von /proc
Verwenden Sie einen Systemmonitor
Erkundung des Anmeldeknotens
Vergleichen Sie nun die Ressourcen Ihres Computers mit denen des Hauptknotens.
BASH
[you@laptop:~]$ ssh yourUsername@cluster.hpc-carpentry.org
[yourUsername@login1 ~] nproc --all
[yourUsername@login1 ~] free -mSie können mehr Informationen über die Prozessoren erhalten, indem
Sie lscpu benutzen, und eine Menge Details über den
Speicher, indem Sie die Datei /proc/meminfo lesen:
Sie können auch die verfügbaren Dateisysteme mit df
(disk freespace )untersuchen, um Festplattenspeicher anzuzeigen. Das
Flag -h zeigt die Größen in einem menschenfreundlichen
Format an, d.h. GB statt B. Das type Flag -T zeigt, welche
Art von Dateisystem jede Ressource ist.
Die lokalen Dateisysteme (ext, tmp, xfs, zfs) hängen davon ab, ob Sie sich auf demselben Anmeldeknoten (oder Rechenknoten, später) befinden. Netzwerk-Dateisysteme (beegfs, cifs, gpfs, nfs, pvfs) werden ähnlich sein — können aber yourUsername enthalten, abhängig davon, wie es [gemountet] wird (https://en.wikipedia.org/wiki/Mount_(computing)).
Gemeinsame Dateisysteme
Dies ist ein wichtiger Punkt: Dateien, die auf einem Knoten (Computer) gespeichert sind, sind oft überall im Cluster verfügbar!
Vergleichen Sie Ihren Computer, den Anmeldeknoten und den Berechnungsknoten
Vergleichen Sie die Anzahl der Prozessoren und des Arbeitsspeichers Ihres Laptops mit den Zahlen, die Sie auf dem Hauptknoten und dem Arbeitsknoten des Clusters sehen. Diskutieren Sie die Unterschiede mit Ihrem Nachbarn.
Was denken Sie, welche Auswirkungen die Unterschiede auf die Durchführung Ihrer Forschungsarbeit auf den verschiedenen Systemen und Knotenpunkten haben könnten?
Unterschiede zwischen den Knoten
Viele HPC-Cluster haben eine Vielzahl von Knoten, die für bestimmte Arbeitslasten optimiert sind. Einige Knoten verfügen über eine größere Speichermenge oder spezialisierte Ressourcen wie grafische Verarbeitungseinheiten (GPUs).
Mit all dem im Hinterkopf werden wir nun besprechen, wie man mit dem Scheduler des Clusters kommuniziert und ihn benutzt, um unsere Skripte und Programme laufen zu lassen!
- “Ein HPC-System ist eine Gruppe von vernetzten Maschinen.”
- “HPC-Systeme bieten normalerweise Anmeldeknoten und eine Reihe von Arbeitsknoten.”
- “Die Ressourcen, die sich auf unabhängigen (Arbeits-)Knoten befinden, können in Umfang und Art variieren (Menge des Arbeitsspeichers, Prozessorarchitektur, Verfügbarkeit von im Netzwerk eingebundenen Dateisystemen usw.).”
- “Dateien, die auf einem Knoten gespeichert sind, sind auf allen Knoten verfügbar.”
Content from Grundlagen des Schedulers
Zuletzt aktualisiert am 2026-02-26 | Diese Seite bearbeiten
Übersicht
Fragen
- Was ist ein Scheduler und warum braucht ein Cluster einen?
- Wie starte ich ein Programm zur Ausführung auf einem Rechenknoten im Cluster?
- Wie kann ich die Ausgabe eines Programms erfassen, das auf einem Knoten im Cluster ausgeführt wird?
Ziele
- Übermittelt ein einfaches Skript an den Cluster.
- Überwachen Sie die Ausführung von Aufträgen mit Hilfe von Kommandozeilenwerkzeugen.
- Überprüfen Sie die Ausgabe- und Fehlerdateien Ihrer Aufträge.
- Finden Sie den richtigen Ort, um große Datensätze auf dem Cluster abzulegen.
Job Scheduler
Ein HPC-System kann Tausende von Knoten und Tausende von Benutzern haben. Wie wird entschieden, wer was und wann bekommt? Wie wird sichergestellt, dass eine Aufgabe mit den erforderlichen Ressourcen ausgeführt wird? Diese Aufgabe wird von einer speziellen Software, dem Scheduler, übernommen. Auf einem HPC-System verwaltet der Scheduler, welche Aufgaben wo und wann ausgeführt werden.
Die folgende Abbildung vergleicht diese Aufgaben eines Job Schedulers mit denen eines Kellners in einem Restaurant. Wenn Sie sich vorstellen können, dass Sie eine Weile in einer Schlange warten mussten, um in ein beliebtes Restaurant zu kommen, dann verstehen Sie jetzt vielleicht, warum Ihr Job manchmal nicht sofort startet, wie bei Ihrem Laptop.

Der in dieser Lektion verwendete Scheduler ist Slurm. Obwohl Slurm nicht überall verwendet wird, ist die Ausführung von Aufträgen ziemlich ähnlich, unabhängig davon, welche Software verwendet wird. Die genaue Syntax kann sich ändern, aber die Konzepte bleiben die gleichen.
Ausführen eines Batch-Jobs
Die einfachste Anwendung des Schedulers ist die nicht-interaktive Ausführung eines Befehls. Jeder Befehl (oder eine Reihe von Befehlen), den Sie auf dem Cluster ausführen möchten, wird als Job bezeichnet, und der Prozess der Verwendung eines Schedulers zur Ausführung des Jobs wird Batch Job Submission genannt.
In diesem Fall handelt es sich bei dem Auftrag, den wir ausführen wollen, um ein Shell-Skript - im Wesentlichen eine Textdatei mit einer Liste von UNIX-Befehlen, die nacheinander ausgeführt werden sollen. Unser Shell-Skript wird aus drei Teilen bestehen:
- In der allerersten Zeile fügen Sie
#!/bin/bashein. Das#!(ausgesprochen “hash-bang” oder “shebang”) sagt dem Computer, welches Programm den Inhalt dieser Datei verarbeiten soll. In diesem Fall teilen wir ihm mit, dass die folgenden Befehle für die Kommandozeilen-Shell geschrieben sind (in der wir bisher alles gemacht haben). - Irgendwo unterhalb der ersten Zeile fügen wir einen
echo-Befehl mit einer freundlichen Begrüßung ein. Wenn es ausgeführt wird, gibt das Shell-Skript im Terminal alles aus, was nachechokommt.-
echo -ndruckt alles, was folgt, ohne die Zeile mit einem Zeilenumbruch zu beenden.
-
- In der letzten Zeile rufen wir den Befehl
hostnameauf, der den Namen des Rechners ausgibt, auf dem das Skript ausgeführt wird.
Erstellen unseres Testjobs
Führen Sie das Skript aus. Wird es auf dem Cluster oder nur auf unserem Anmeldeknoten ausgeführt?
Dieses Skript lief auf dem Anmeldeknoten, aber wir wollen die
Vorteile der Rechenknoten nutzen: Wir brauchen den Scheduler, um
example-job.sh in die Warteschlange zu stellen, damit er
auf einem Rechenknoten läuft.
Um diese Aufgabe an den Scheduler zu senden, benutzen wir den Befehl
sbatch. Dies erzeugt einen Job, der das
Skript ausführt, wenn er an einen Rechenknoten
gesendet wird, den das Warteschlangensystem als verfügbar für
die Ausführung der Arbeit identifiziert hat.
AUSGABE
Submitted batch job 7Und das ist alles, was wir tun müssen, um einen Auftrag abzuschicken.
Unsere Arbeit ist getan - jetzt übernimmt der Scheduler und versucht,
den Auftrag für uns auszuführen. Während der Auftrag darauf wartet,
ausgeführt zu werden, wird er in eine Liste von Aufträgen aufgenommen,
die Warteschlange. Um den Status unseres Jobs (oder Auftrags)
zu überprüfen, können wir die Warteschlange mit dem Befehl
squeue -u yourUsername überprüfen.
AUSGABE
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
9 cpubase_b example- user01 R 0:05 1 node1Wir können alle Details zu unserem Auftrag sehen, vor allem, dass er
sich im Status R oder RUNNING befindet.
Manchmal müssen unsere Aufträge in einer Warteschlange warten
(PENDING) oder haben einen Fehler (E).
Wo ist die Ausgabe?
Auf dem Login-Knoten gab dieses Skript eine Ausgabe auf dem Terminal
aus – aber jetzt, wenn squeue anzeigt, dass der Job beendet
ist, wurde nichts auf dem Terminal ausgegeben.
Die Ausgabe eines Cluster-Jobs wird normalerweise in eine Datei in
dem Verzeichnis umgeleitet, aus dem Sie ihn gestartet haben. Verwenden
Sie ls zum Suchen und cat zum Lesen der
Datei.
Anpassen eines Jobs
Der Auftrag, den wir gerade ausgeführt haben, verwendete alle Standardoptionen des Schedulers. In einem realen Szenario ist das wahrscheinlich nicht das, was wir wollen. Die Standardoptionen stellen ein vernünftiges Minimum dar. Wahrscheinlich benötigen wir mehr Kerne, mehr Arbeitsspeicher, mehr Zeit und andere spezielle Überlegungen. Um Zugang zu diesen Ressourcen zu erhalten, müssen wir unser Jobskript anpassen.
Kommentare in UNIX-Shell-Skripten (gekennzeichnet durch
#) werden normalerweise ignoriert, aber es gibt Ausnahmen.
Zum Beispiel gibt der spezielle Kommentar #! am Anfang von
Skripten an, welches Programm benutzt werden soll, um es auszuführen
(typischerweise steht hier #!/usr/bin/env bash). Scheduler
wie Slurm haben auch einen speziellen Kommentar, um spezielle
Scheduler-spezifische Optionen zu kennzeichnen. Obwohl diese Kommentare
von Scheduler zu Scheduler unterschiedlich sind, ist der spezielle
Kommentar von Slurm #SBATCH. Alles, was dem Kommentar
#SBATCH folgt, wird als Anweisung an den Scheduler
interpretiert.
Lassen Sie uns dies an einem Beispiel verdeutlichen. Standardmäßig
ist der Name eines Jobs der Name des Skripts, aber mit der Option
-J kann man den Namen eines Jobs ändern. Fügen Sie eine
Option in das Skript ein:
Übermitteln Sie den Auftrag und überwachen Sie seinen Status:
AUSGABE
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
10 cpubase_b hello-wo user01 R 0:02 1 node1Fantastisch, wir haben den Namen unseres Jobs erfolgreich geändert!
Ressourcenanfragen
Was ist mit wichtigeren Änderungen, wie der Anzahl der Kerne und des Speichers für unsere Jobs? Eine Sache, die bei der Arbeit an einem HPC-System absolut entscheidend ist, ist die Angabe der für die Ausführung eines Auftrags erforderlichen Ressourcen. So kann der Scheduler die richtige Zeit und den richtigen Ort für die Ausführung unseres Auftrags finden. Wenn Sie die Anforderungen (z. B. die benötigte Zeit) nicht angeben, werden Sie wahrscheinlich mit den Standardressourcen Ihrer Website arbeiten, was wahrscheinlich nicht das ist, was Sie wollen.
Es folgen mehrere wichtige Ressourcenanfragen:
--ntasks=<ntasks>oder-n <ntasks>: Wie viele CPU-Kerne benötigt Ihr Job insgesamt?--time <days-hours:minutes:seconds>oder-t <days-hours:minutes:seconds>: Wie viel reale Zeit (Walltime) wird Ihr Job für die Ausführung benötigen? Der Teil<days>kann weggelassen werden.--mem=<megabytes>: Wie viel Speicher auf einem Knoten benötigt Ihr Auftrag in Megabyte? Sie können auch Gigabytes angeben, indem Sie ein kleines “g” anhängen (Beispiel:--mem=5g)--nodes=<nnodes>oder-N <nnodes>: Auf wie vielen separaten Rechnern muss Ihr Auftrag laufen? Beachten Sie, dass, wenn Sientasksauf eine Zahl setzen, die größer ist als die, die eine Maschine bieten kann, Slurm diesen Wert automatisch einstellt.
Beachten Sie, dass das bloße Anfordern dieser Ressourcen Ihren Auftrag nicht schneller laufen lässt und auch nicht unbedingt bedeutet, dass Sie alle diese Ressourcen verbrauchen werden. Es bedeutet nur, dass sie Ihnen zur Verfügung gestellt werden. Es kann sein, dass Ihr Auftrag am Ende weniger Speicher, weniger Zeit oder weniger Knoten benötigt, als Sie angefordert haben, und er wird trotzdem ausgeführt.
Es ist am besten, wenn Ihre Anfragen die Anforderungen Ihres Auftrags genau widerspiegeln. In einer späteren Folge dieser Lektion werden wir mehr darüber sprechen, wie Sie sicherstellen können, dass Sie die Ressourcen effektiv nutzen.
Übermittlung von Ressourcenanfragen
Ändern Sie unser hostname-Skript so, dass es eine Minute
lang läuft, und senden Sie dann einen Job dafür an den Cluster.
Ressourcenanforderungen sind normalerweise verbindlich. Wenn Sie diese überschreiten, wird Ihr Auftrag abgebrochen. Nehmen wir die Walltime als Beispiel. Wir fordern 1 Minute Walltime an und versuchen, einen Auftrag zwei Minuten lang laufen zu lassen.
BASH
#!/bin/bash
#SBATCH -J long_job
#SBATCH -t 00:01 # timeout in HH:MM
echo "This script is running on ... "
sleep 240 # time in seconds
hostnameSenden Sie den Auftrag ab und warten Sie, bis er beendet ist. Sobald er beendet ist, überprüfen Sie die Protokolldatei.
AUSGABE
This script is running on ...
slurmstepd: error: *** JOB 12 ON node1 CANCELLED AT 2021-02-19T13:55:57
DUE TO TIME LIMIT ***Unser Auftrag wurde abgebrochen, weil er die angeforderte Menge an Ressourcen überschritten hat. Obwohl dies hart erscheint, handelt es sich dabei um eine Funktion. Die strikte Einhaltung der Ressourcenanforderungen ermöglicht es dem Scheduler, den bestmöglichen Platz für Ihre Jobs zu finden. Noch wichtiger ist jedoch, dass dadurch sichergestellt wird, dass ein anderer Benutzer nicht mehr Ressourcen verwenden kann, als ihm zugewiesen wurden. Wenn ein anderer Benutzer einen Fehler macht und versehentlich versucht, alle Kerne oder den gesamten Speicher eines Knotens zu nutzen, wird Slurm entweder seinen Job auf die angeforderten Ressourcen beschränken oder den Job ganz beenden. Andere Jobs auf dem Knoten sind davon nicht betroffen. Das bedeutet, dass ein Benutzer nicht die Erfahrungen anderer Benutzer durcheinander bringen kann, die einzigen Jobs, die von einem Fehler in der Planung betroffen sind, sind die eigenen.
Abbrechen eines Jobs
Manchmal machen wir einen Fehler und müssen einen Auftrag abbrechen.
Das kann man mit dem Befehl scancel machen. Lassen Sie uns
einen Job abschicken und ihn dann mit seiner Jobnummer abbrechen (denken
Sie daran, die Walltime so zu ändern, dass er lange genug läuft, damit
Sie ihn abbrechen können, bevor er beendet wird).
AUSGABE
Submitted batch job 13
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
13 cpubase_b long_job user01 R 0:02 1 node1Stornieren Sie nun den Auftrag mit seiner Auftragsnummer (die in Ihrem Terminal ausgedruckt wird). Eine saubere Rückkehr Ihrer Eingabeaufforderung zeigt an, dass die Anfrage zum Abbrechen des Auftrags erfolgreich war.
BASH
[yourUsername@login1 ~] scancel 38759
# It might take a minute for the job to disappear from the queue...
[yourUsername@login1 ~] squeue -u yourUsernameAUSGABE
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)Abbrechen mehrerer Jobs
Wir können auch alle unsere Aufträge auf einmal mit der Option
-u löschen. Damit werden alle Aufträge für einen bestimmten
Benutzer (in diesem Fall für Sie selbst) gelöscht. Beachten Sie, dass
Sie nur Ihre eigenen Aufträge löschen können.
Versuchen Sie, mehrere Aufträge einzureichen und sie dann alle abzubrechen.
Andere Arten von Jobs
Bis zu diesem Punkt haben wir uns auf die Ausführung von Jobs im
Batch-Modus konzentriert. Slurm bietet auch die
Möglichkeit, eine interaktive Sitzung zu starten.
Es gibt sehr häufig Aufgaben, die interaktiv erledigt werden müssen.
Ein ganzes Job-Skript zu erstellen, wäre vielleicht übertrieben, aber
die Menge der benötigten Ressourcen ist zu groß für einen Login-Knoten.
Ein gutes Beispiel hierfür ist die Erstellung eines Genomindexes für das
Alignment mit einem Tool wie HISAT2.
Glücklicherweise können wir diese Art von Aufgaben einmalig mit
srun ausführen.
srun führt einen einzelnen Befehl auf dem Cluster aus
und beendet sich dann. Lassen Sie uns dies demonstrieren, indem wir den
Befehl hostname mit srun ausführen. (Wir
können einen srun-Job mit Ctrl-c
abbrechen.)
AUSGABE
smnode1srun akzeptiert die gleichen Optionen wie
sbatch. Allerdings werden diese Optionen nicht in einem
Skript angegeben, sondern auf der Kommandozeile, wenn ein Job gestartet
wird. Um einen Job zu starten, der 2 CPUs benutzt, könnte man z.B. den
folgenden Befehl verwenden:
AUSGABE
This job will use 2 CPUs.
This job will use 2 CPUs.Typischerweise wird die resultierende Shell-Umgebung die gleiche sein
wie die für sbatch.
Interaktive Jobs
Manchmal braucht man viele Ressourcen für die interaktive Nutzung.
Vielleicht führen wir zum ersten Mal eine Analyse durch oder versuchen,
einen Fehler zu beheben, der bei einem früheren Auftrag aufgetreten ist.
Glücklicherweise macht es Slurm einfach, einen interaktiven Job mit
srun zu starten:
Sie sollten nun eine Bash-Eingabeaufforderung erhalten. Beachten Sie,
dass sich die Eingabeaufforderung wahrscheinlich ändert, um Ihren neuen
Standort wiederzugeben, in diesem Fall den Rechenknoten, an dem wir
angemeldet sind. Sie können dies auch mit hostname
überprüfen.
Erstellen von Remote-Grafiken
Um die grafische Ausgabe innerhalb Ihrer Aufträge zu sehen, müssen
Sie die X11-Weiterleitung verwenden. Um diese Funktion zu aktivieren,
verwenden Sie die Option -Y, wenn Sie sich mit dem Befehl
ssh anmelden, z.B.
ssh -Y yourUsername@cluster.hpc-carpentry.org.
Um zu demonstrieren, was passiert, wenn Sie ein Grafikfenster auf dem
entfernten Knoten erstellen, verwenden Sie den Befehl
xeyes. Ein relativ hübsches Augenpaar sollte auftauchen
(drücken Sie Ctrl-C, um zu stoppen). Wenn Sie einen Mac
verwenden, müssen Sie XQuartz installiert (und Ihren Computer neu
gestartet) haben, damit dies funktioniert.
Wenn Ihr Cluster das slurm-spank-x11
Plugin installiert hat, können Sie die X11-Weiterleitung innerhalb
interaktiver Jobs sicherstellen, indem Sie die Option --x11
für srun mit dem Befehl srun --x11 --pty bash
verwenden.
Wenn Sie mit dem interaktiven Job fertig sind, geben Sie
exit ein, um Ihre Sitzung zu beenden.
- Der Scheduler verwaltet die Aufteilung der Rechenressourcen zwischen den Benutzern.
- Ein Job ist einfach ein Shell-Skript.
- Fordern Sie geringfügig mehr Ressourcen an, als Sie brauchen werden.
Content from Umgebungsvariablen
Zuletzt aktualisiert am 2026-02-26 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie werden Variablen in der Unix-Shell gesetzt und angesprochen?
- Wie kann ich Variablen verwenden, um den Ablauf eines Programms zu verändern?
Ziele
- Verstehen, wie Variablen in der Shell implementiert werden
- Den Wert einer bestehenden Variable auslesen
- Erstellen Sie neue Variablen und ändern Sie deren Werte
- Ändern Sie das Verhalten eines Programms mit Hilfe einer Umgebungsvariablen
- Erkläre, wie die Shell die Variable
PATHbenutzt, um nach ausführbaren Dateien zu suchen
Herkunft der Episode
Diese Folge wurde aus der [Shell-Extras-Folge über Shell-Variablen] (https://github.com/carpentries-incubator/shell-extras/blob/gh-pages/_episodes/08-environment-variables.md) und der [HPC-Shell-Folge über Skripte] (https://github.com/hpc-carpentry/hpc-shell/blob/gh-pages/_episodes/05-scripts.md) neu zusammengestellt.
Die Shell ist nur ein Programm, und wie andere Programme auch, hat sie Variablen. Diese Variablen steuern ihre Ausführung, so dass Sie durch Ändern ihrer Werte das Verhalten der Shell (und mit etwas mehr Aufwand auch das Verhalten anderer Programme) beeinflussen können.
Variablen sind eine gute Möglichkeit, Informationen unter einem Namen zu speichern, auf den man später zugreifen kann. In Programmiersprachen wie Python und R können Variablen so ziemlich alles speichern, was man sich vorstellen kann. In der Shell speichern sie normalerweise nur Text. Der beste Weg, um zu verstehen, wie sie funktionieren, ist, sie in Aktion zu sehen.
Beginnen wir damit, den Befehl set auszuführen und
einige der Variablen in einer typischen Shell-Sitzung zu betrachten:
AUSGABE
COMPUTERNAME=TURING
HOME=/home/vlad
HOSTNAME=TURING
HOSTTYPE=i686
NUMBER_OF_PROCESSORS=4
PATH=/Users/vlad/bin:/usr/local/git/bin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin
PWD=/home/vlad
UID=1000
USERNAME=vlad
...Wie Sie sehen können, gibt es ziemlich viele - tatsächlich vier- oder
fünfmal so viele, wie hier gezeigt werden. Und ja, set zu
benutzen, um Dinge anzuzeigen, mag ein wenig seltsam
erscheinen, selbst für Unix, aber wenn Sie ihr keine Argumente geben,
kann sie Ihnen auch Dinge zeigen, die Sie einstellen
könnten.
Jede Variable hat einen Namen. Alle Werte von Shell-Variablen sind
Zeichenketten, auch solche (wie UID), die wie Zahlen
aussehen. Es liegt an den Programmen, diese Zeichenketten bei Bedarf in
andere Typen zu konvertieren. Wenn ein Programm zum Beispiel
herausfinden wollte, wie viele Prozessoren der Computer hat, würde es
den Wert der Variablen NUMBER_OF_PROCESSORS von einer
Zeichenkette in eine ganze Zahl umwandeln.
Den Wert einer Variablen anzeigen
Zeigen wir den Wert der Variable HOME:
AUSGABE
HOMEDas gibt nur “HOME” aus, was nicht das ist, was wir wollten (obwohl es das ist, wonach wir eigentlich gefragt haben). Versuchen wir stattdessen dies:
AUSGABE
/home/vladDas Dollarzeichen sagt der Shell, dass wir den Wert der
Variable wollen und nicht ihren Namen. Das funktioniert genau wie bei
Wildcards: die Shell ersetzt die Variable vor der Ausführung
des gewünschten Programms. Dank dieser Erweiterung ist das, was wir
tatsächlich ausführen, echo /home/vlad, was das Richtige
anzeigt.
Erstellen und Ändern von Variablen
Eine Variable zu erstellen ist einfach - wir weisen einem Namen mit
“=” einen Wert zu (wir müssen nur daran denken, dass die Syntax
verlangt, dass keine Leerzeichen um das = herum
sind!)
AUSGABE
DraculaUm den Wert zu ändern, weisen Sie einfach einen neuen Wert zu:
AUSGABE
CamillaUmgebungsvariablen
Als wir den set-Befehl ausführten, sahen wir, dass es
eine Menge Variablen gab, deren Namen in Großbuchstaben geschrieben
waren. Das liegt daran, dass Variablen, die auch von anderen
Programmen verwendet werden können, in Großbuchstaben benannt werden.
Solche Variablen werden Umgebungsvariablen genannt, da es sich
um Shell-Variablen handelt, die für die aktuelle Shell definiert sind
und an alle untergeordneten Shells oder Prozesse vererbt werden.
Um eine Umgebungsvariable zu erstellen, müssen Sie eine
Shell-Variable export angeben. Um zum Beispiel unser
SECRET_IDENTITY für andere Programme, die wir von unserer
Shell aus aufrufen, verfügbar zu machen, können wir folgendes tun:
Sie können die Variable auch in einem einzigen Schritt erstellen und exportieren:
Verwendung von Umgebungsvariablen zur Änderung des Programmverhaltens
Setze eine Shell-Variable TIME_STYLE auf den Wert
iso und prüfe diesen Wert mit dem Befehl
echo.
Führen Sie nun den Befehl ls mit der Option
-l aus (was ein langes Format ergibt).
export die Variable und führen Sie den Befehl
ls -l erneut aus. Bemerkst du einen Unterschied?
Die Variable TIME_STYLE wird von ls nicht
gesehen, bis sie exportiert wird. Zu diesem Zeitpunkt wird sie
von ls benutzt, um zu entscheiden, welches Datumsformat bei
der Darstellung des Zeitstempels von Dateien zu verwenden ist.
Sie können den kompletten Satz von Umgebungsvariablen in Ihrer
aktuellen Shell-Sitzung mit dem Befehl env sehen (der eine
Teilmenge dessen zurückgibt, was der Befehl set uns gegeben
hat). Der komplette Satz von Umgebungsvariablen wird als
Laufzeitumgebung bezeichnet und kann das Verhalten der von
Ihnen ausgeführten Programme beeinflussen.
Job-Umgebungsvariablen
Wenn Slurm einen Job ausführt, setzt es eine Reihe von
Umgebungsvariablen für den Job. Mit einer dieser Variablen können wir
überprüfen, von welchem Verzeichnis aus unser Job-Skript eingereicht
wurde. Die Variable SLURM_SUBMIT_DIR wird auf das
Verzeichnis gesetzt, von dem aus unser Job eingereicht wurde. Ändern Sie
Ihren Job mit Hilfe der Variable SLURM_SUBMIT_DIR so, dass
er das Verzeichnis ausgibt, von dem aus der Job übermittelt wurde.
Um eine Variable oder Umgebungsvariable zu entfernen, können Sie zum
Beispiel den Befehl unset verwenden:
Die PATH Umgebungsvariable
In ähnlicher Weise speichern einige Umgebungsvariablen (wie
PATH) Listen von Werten. In diesem Fall ist die Konvention,
einen Doppelpunkt ‘:’ als Trennzeichen zu verwenden. Wenn ein Programm
die einzelnen Elemente einer solchen Liste benötigt, muss es den
String-Wert der Variablen in Stücke aufteilen.
Schauen wir uns die Variable PATH genauer an. Ihr Wert
definiert den Suchpfad der Shell für ausführbare Programme, d.h. die
Liste der Verzeichnisse, in denen die Shell nach ausführbaren Programmen
sucht, wenn Sie einen Programmnamen eintippen, ohne anzugeben, in
welchem Verzeichnis er sich befindet.
Wenn wir zum Beispiel einen Befehl wie analyze eingeben,
muss die Shell entscheiden, ob sie ./analyze oder
/bin/analyze ausführen soll. Die Regel, die sie dabei
anwendet, ist einfach: Die Shell prüft jedes Verzeichnis in der
Variablen PATH der Reihe nach und sucht nach einem Programm
mit dem gewünschten Namen in diesem Verzeichnis. Sobald sie eine
Übereinstimmung findet, hört sie auf zu suchen und führt das Programm
aus.
Um zu zeigen, wie das funktioniert, sind hier die Komponenten von
PATH aufgelistet, eine pro Zeile:
AUSGABE
/Users/vlad/bin
/usr/local/git/bin
/usr/bin
/bin
/usr/sbin
/sbin
/usr/local/binAuf unserem Computer gibt es eigentlich drei Programme namens
analyze in drei verschiedenen Verzeichnissen:
/bin/analyze, /usr/local/bin/analyze, und
/users/vlad/analyze. Da die Shell die Verzeichnisse in der
Reihenfolge durchsucht, in der sie in PATH aufgelistet
sind, findet sie /bin/analyze zuerst und führt es aus.
Beachten Sie, dass sie das Programm /users/vlad/analyze
nie finden wird, es sei denn, wir geben den vollständigen Pfad
zum Programm ein, da das Verzeichnis /users/vlad nicht in
PATH enthalten ist.
Das bedeutet, dass ich ausführbare Dateien an vielen verschiedenen
Orten haben kann, solange ich daran denke, dass ich mein
PATH aktualisieren muss, damit meine Shell sie finden
kann.
Was ist, wenn ich zwei verschiedene Versionen desselben Programms
ausführen möchte? Da sie den gleichen Namen haben, wird, wenn ich sie
beide zu meinem PATH hinzufüge, immer die erste gefundene
Version gewinnen. In der nächsten Folge werden wir lernen, wie wir
Hilfsmittel verwenden können, die uns bei der Verwaltung unserer
Laufzeitumgebung helfen, damit dies möglich ist, ohne dass wir eine
Menge Buchhaltung darüber führen müssen, welchen Wert PATH
(und andere wichtige Umgebungsvariablen) haben oder haben sollten.
- Shell-Variablen werden standardmäßig als Zeichenketten behandelt
- Variablen werden mit “
=” zugewiesen und mit dem Variablennamen, dem “$” vorangestellt ist, abgerufen - Verwenden Sie “
export”, um eine Variable für andere Programme verfügbar zu machen - Die Variable
PATHdefiniert den Suchpfad der Shell
Content from Zugriff auf Software über Module
Zuletzt aktualisiert am 2026-02-26 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie laden und entladen wir Softwarepakete?
Ziele
- Ein Softwarepaket laden und verwenden.
- Erklären Sie, wie sich die Shell-Umgebung verändert, wenn der Modulmechanismus Pakete lädt oder entlädt.
Auf einem Hochleistungsrechnersystem ist die Software, die wir benutzen wollen, selten verfügbar, wenn wir uns anmelden. Sie ist zwar installiert, aber wir müssen sie erst “laden”, bevor sie ausgeführt werden kann.
Bevor wir jedoch anfangen, einzelne Softwarepakete zu verwenden, sollten wir die Gründe für diesen Ansatz verstehen. Die drei wichtigsten Faktoren sind:
- Software-Inkompatibilitäten
- Versionierung
- Abhängigkeiten
Software-Inkompatibilität ist ein großes Problem für Programmierer.
Manchmal führt das Vorhandensein (oder Fehlen) eines Softwarepakets
dazu, dass andere Pakete, die davon abhängen, nicht mehr funktionieren.
Zwei bekannte Beispiele sind Python und C-Compiler-Versionen. Python 3
bietet bekanntlich einen python-Befehl, der im Widerspruch
zu dem von Python 2 steht. Software, die mit einer neueren Version der
C-Bibliotheken kompiliert und dann auf einem Rechner ausgeführt wird,
auf dem ältere C-Bibliotheken installiert sind, führt zu einem
unangenehmen 'GLIBCXX_3.4.20' not found-Fehler.
Software Versionierung ist ein weiteres häufiges Problem. Ein Team könnte für sein Forschungsprojekt auf eine bestimmte Paketversion angewiesen sein - wenn sich die Softwareversion ändert (z.B. wenn ein Paket aktualisiert wird), könnte dies die Ergebnisse beeinflussen. Durch den Zugriff auf mehrere Softwareversionen kann eine Gruppe von Forschern verhindern, dass Softwareversionsprobleme ihre Ergebnisse beeinträchtigen.
Von Abhängigkeiten spricht man, wenn ein bestimmtes Softwarepaket (oder sogar eine bestimmte Version) vom Zugriff auf ein anderes Softwarepaket (oder sogar eine bestimmte Version eines anderen Softwarepakets) abhängig ist. Zum Beispiel kann die VASP-Materialwissenschaftssoftware davon abhängen, dass eine bestimmte Version der FFTW-Softwarebibliothek (Fastest Fourier Transform in the West) verfügbar ist, damit sie funktioniert.
Umgebungsmodule
Umgebungsmodule sind die Lösung für diese Probleme. Ein Modul ist eine in sich geschlossene Beschreibung eines Softwarepakets - es enthält die Einstellungen, die zum Ausführen eines Softwarepakets erforderlich sind, und kodiert in der Regel auch die erforderlichen Abhängigkeiten von anderen Softwarepaketen.
Es gibt eine Reihe von verschiedenen Implementierungen von
Umgebungsmodulen, die häufig auf HPC-Systemen verwendet werden: die
beiden häufigsten sind TCL-Module und Lmod. Beide
verwenden eine ähnliche Syntax und die Konzepte sind die gleichen, so
dass Sie, wenn Sie lernen, eines davon zu verwenden, dasjenige verwenden
können, das auf dem von Ihnen verwendeten System installiert ist. In
beiden Implementierungen wird der Befehl module verwendet,
um mit Umgebungsmodulen zu interagieren. Normalerweise wird dem Befehl
ein zusätzlicher Unterbefehl hinzugefügt, um anzugeben, was Sie tun
wollen. Für eine Liste von Unterbefehlen können Sie
module -h oder module help verwenden. Wie für
alle Befehle können Sie die vollständige Hilfe auf den
man-Seiten mit man module aufrufen.
Bei der Anmeldung können Sie mit einem Standardsatz von geladenen Modulen oder mit einer leeren Umgebung starten; dies hängt von der Einrichtung des von Ihnen verwendeten Systems ab.
Auflistung der verfügbaren Module
Um verfügbare Softwaremodule zu sehen, verwenden Sie
module avail:
AUSGABE
~~~ /cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/modules/all ~~~
Bazel/3.6.0-GCCcore-x.y.z NSS/3.51-GCCcore-x.y.z
Bison/3.5.3-GCCcore-x.y.z Ninja/1.10.0-GCCcore-x.y.z
Boost/1.72.0-gompi-2020a OSU-Micro-Benchmarks/5.6.3-gompi-2020a
CGAL/4.14.3-gompi-2020a-Python-3.x.y OpenBLAS/0.3.9-GCC-x.y.z
CMake/3.16.4-GCCcore-x.y.z OpenFOAM/v2006-foss-2020a
[removed most of the output here for clarity]
Where:
L: Module is loaded
Aliases: Aliases exist: foo/1.2.3 (1.2) means that "module load foo/1.2"
will load foo/1.2.3
D: Default Module
Use "module spider" to find all possible modules and extensions.
Use "module keyword key1 key2 ..." to search for all possible modules matching
any of the "keys".Laden und Entladen von Software
Um ein Softwaremodul zu laden, verwenden Sie
module load. In diesem Beispiel werden wir Python 3
verwenden.
Anfangs ist Python 3 nicht geladen. Wir können dies mit dem Befehl
which testen. der Befehl which sucht auf die
gleiche Weise wie die Bash nach Programmen, so dass wir ihn verwenden
können, um uns zu sagen, wo eine bestimmte Software gespeichert ist.
Wenn der Befehl python3 nicht verfügbar wäre, würden wir
folgende Ausgabe sehen
AUSGABE
/usr/bin/which: no python3 in (/cvmfs/pilot.eessi-hpc.org/2020.12/compat/linux/x86_64/usr/bin:/opt/software/slurm/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/puppetlabs/bin:/home/yourUsername/.local/bin:/home/yourUsername/bin)Beachten Sie, dass dieser Text in Wirklichkeit eine Liste ist, mit
Werten, die durch das Zeichen : getrennt sind. Die Ausgabe
sagt uns, dass der Befehl which die folgenden Verzeichnisse
nach python3 durchsucht hat, ohne Erfolg:
AUSGABE
/cvmfs/pilot.eessi-hpc.org/2020.12/compat/linux/x86_64/usr/bin
/opt/software/slurm/bin
/usr/local/bin
/usr/bin
/usr/local/sbin
/usr/sbin
/opt/puppetlabs/bin
/home/yourUsername/.local/bin
/home/yourUsername/binIn unserem Fall haben wir jedoch ein vorhandenes python3
zur Verfügung, so dass wir sehen
AUSGABE
/cvmfs/pilot.eessi-hpc.org/2020.12/compat/linux/x86_64/usr/bin/python3Wir benötigen jedoch ein anderes Python als das vom System bereitgestellte, also laden wir ein Modul, um darauf zuzugreifen.
Wir können den Befehl python3 mit
module load laden:
AUSGABE
/cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/Python/3.x.y-GCCcore-x.y.z/bin/python3Was ist gerade passiert?
Um die Ausgabe zu verstehen, müssen wir zuerst die Natur der
Umgebungsvariablen $PATH verstehen. $PATH ist
eine spezielle Umgebungsvariable, die steuert, wo ein UNIX-System nach
Software sucht. Genauer gesagt ist $PATH eine Liste von
Verzeichnissen (getrennt durch :), die das Betriebssystem
nach einem Befehl durchsucht, bevor es aufgibt und uns mitteilt, dass es
ihn nicht finden kann. Wie bei allen Umgebungsvariablen können wir sie
mit echo ausgeben.
AUSGABE
/cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/Python/3.x.y-GCCcore-x.y.z/bin:/cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/SQLite/3.31.1-GCCcore-x.y.z/bin:/cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/Tcl/8.6.10-GCCcore-x.y.z/bin:/cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/GCCcore/x.y.z/bin:/cvmfs/pilot.eessi-hpc.org/2020.12/compat/linux/x86_64/usr/bin:/opt/software/slurm/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/puppetlabs/bin:/home/user01/.local/bin:/home/user01/binSie werden eine Ähnlichkeit mit der Ausgabe des Befehls
which feststellen. In diesem Fall gibt es nur einen
Unterschied: das andere Verzeichnis am Anfang. Als wir den Befehl
module load ausführten, fügte er ein Verzeichnis am Anfang
unseres $PATH hinzu. Schauen wir uns an, was dort
steht:
BASH
[yourUsername@login1 ~] ls /cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/Python/3.x.y-GCCcore-x.y.z/binAUSGABE
2to3 nosetests-3.8 python rst2s5.py
2to3-3.8 pasteurize python3 rst2xetex.py
chardetect pbr python3.8 rst2xml.py
cygdb pip python3.8-config rstpep2html.py
cython pip3 python3-config runxlrd.py
cythonize pip3.8 rst2html4.py sphinx-apidoc
easy_install pybabel rst2html5.py sphinx-autogen
easy_install-3.8 __pycache__ rst2html.py sphinx-build
futurize pydoc3 rst2latex.py sphinx-quickstart
idle3 pydoc3.8 rst2man.py tabulate
idle3.8 pygmentize rst2odt_prepstyles.py virtualenv
netaddr pytest rst2odt.py wheel
nosetests py.test rst2pseudoxml.pyUm es auf den Punkt zu bringen: module load fügt
Software zu Ihrem $PATH hinzu. Es “lädt” Software. Ein
spezieller Hinweis dazu - je nachdem, welche Version des Programms
module bei Ihnen installiert ist, wird
module load auch erforderliche Software-Abhängigkeiten
laden.
Zur Veranschaulichung wollen wir module list verwenden.
module list zeigt alle geladenen Softwaremodule an.
AUSGABE
Currently Loaded Modules:
1) GCCcore/x.y.z 4) GMP/6.2.0-GCCcore-x.y.z
2) Tcl/8.6.10-GCCcore-x.y.z 5) libffi/3.3-GCCcore-x.y.z
3) SQLite/3.31.1-GCCcore-x.y.z 6) Python/3.x.y-GCCcore-x.y.zAUSGABE
Currently Loaded Modules:
1) GCCcore/x.y.z 14) libfabric/1.11.0-GCCcore-x.y.z
2) Tcl/8.6.10-GCCcore-x.y.z 15) PMIx/3.1.5-GCCcore-x.y.z
3) SQLite/3.31.1-GCCcore-x.y.z 16) OpenMPI/4.0.3-GCC-x.y.z
4) GMP/6.2.0-GCCcore-x.y.z 17) OpenBLAS/0.3.9-GCC-x.y.z
5) libffi/3.3-GCCcore-x.y.z 18) gompi/2020a
6) Python/3.x.y-GCCcore-x.y.z 19) FFTW/3.3.8-gompi-2020a
7) GCC/x.y.z 20) ScaLAPACK/2.1.0-gompi-2020a
8) numactl/2.0.13-GCCcore-x.y.z 21) foss/2020a
9) libxml2/2.9.10-GCCcore-x.y.z 22) pybind11/2.4.3-GCCcore-x.y.z-Pytho...
10) libpciaccess/0.16-GCCcore-x.y.z 23) SciPy-bundle/2020.03-foss-2020a-Py...
11) hwloc/2.2.0-GCCcore-x.y.z 24) networkx/2.4-foss-2020a-Python-3.8...
12) libevent/2.1.11-GCCcore-x.y.z 25) GROMACS/2020.1-foss-2020a-Python-3...
13) UCX/1.8.0-GCCcore-x.y.zIn diesem Fall hat das Laden des Moduls GROMACS (ein
Bioinformatik-Softwarepaket) auch GMP/6.2.0-GCCcore-x.y.z
und SciPy-bundle/2020.03-foss-2020a-Python-3.x.y geladen.
Lassen Sie uns versuchen, das Paket GROMACS zu
entladen.
AUSGABE
Currently Loaded Modules:
1) GCCcore/x.y.z 13) UCX/1.8.0-GCCcore-x.y.z
2) Tcl/8.6.10-GCCcore-x.y.z 14) libfabric/1.11.0-GCCcore-x.y.z
3) SQLite/3.31.1-GCCcore-x.y.z 15) PMIx/3.1.5-GCCcore-x.y.z
4) GMP/6.2.0-GCCcore-x.y.z 16) OpenMPI/4.0.3-GCC-x.y.z
5) libffi/3.3-GCCcore-x.y.z 17) OpenBLAS/0.3.9-GCC-x.y.z
6) Python/3.x.y-GCCcore-x.y.z 18) gompi/2020a
7) GCC/x.y.z 19) FFTW/3.3.8-gompi-2020a
8) numactl/2.0.13-GCCcore-x.y.z 20) ScaLAPACK/2.1.0-gompi-2020a
9) libxml2/2.9.10-GCCcore-x.y.z 21) foss/2020a
10) libpciaccess/0.16-GCCcore-x.y.z 22) pybind11/2.4.3-GCCcore-x.y.z-Pytho...
11) hwloc/2.2.0-GCCcore-x.y.z 23) SciPy-bundle/2020.03-foss-2020a-Py...
12) libevent/2.1.11-GCCcore-x.y.z 24) networkx/2.4-foss-2020a-Python-3.x.yDie Verwendung von module unload “entlädt” also ein
Modul, und je nachdem, wie eine Site konfiguriert ist, kann es auch alle
Abhängigkeiten entladen (in unserem Fall nicht). Wenn wir alles auf
einmal entladen wollten, könnten wir module purge ausführen
(entlädt alles).
AUSGABE
No modules loadedBeachten Sie, dass module purge informativ ist. Es teilt
uns auch mit, ob ein Standardsatz von “anhaftenden” (“sticky”) Paketen
nicht entladen werden kann (und wie man diese tatsächlich entlädt, wenn
man das wirklich möchte).
Beachten Sie, dass dieser Modulladeprozess hauptsächlich durch die
Manipulation von Umgebungsvariablen wie $PATH erfolgt.
Normalerweise ist nur ein geringer oder gar kein Datentransfer
beteiligt.
Der Modulladeprozess manipuliert auch andere spezielle Umgebungsvariablen, einschließlich Variablen, die beeinflussen, wo das System nach Softwarebibliotheken sucht, und manchmal Variablen, die kommerziellen Softwarepaketen mitteilen, wo sie Lizenzserver finden.
Der Modulbefehl setzt auch diese Shell-Umgebungsvariablen in ihren vorherigen Zustand zurück, wenn ein Modul entladen wird.
Software-Versionierung
Bis jetzt haben wir gelernt, wie man Softwarepakete lädt und entlädt. Das ist sehr nützlich. Wir haben uns jedoch noch nicht mit dem Thema der Softwareversionierung befasst. Irgendwann werden Sie auf Probleme stoßen, für die nur eine bestimmte Version einer Software geeignet ist. Vielleicht wurde ein wichtiger Fehler nur in einer bestimmten Version behoben, oder Version X ist nicht mehr mit einem von Ihnen verwendeten Dateiformat kompatibel. In jedem dieser Fälle ist es hilfreich, sehr genau zu wissen, welche Software geladen wird.
Schauen wir uns die Ausgabe von module avail näher
an.
AUSGABE
~~~ /cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/modules/all ~~~
Bazel/3.6.0-GCCcore-x.y.z NSS/3.51-GCCcore-x.y.z
Bison/3.5.3-GCCcore-x.y.z Ninja/1.10.0-GCCcore-x.y.z
Boost/1.72.0-gompi-2020a OSU-Micro-Benchmarks/5.6.3-gompi-2020a
CGAL/4.14.3-gompi-2020a-Python-3.x.y OpenBLAS/0.3.9-GCC-x.y.z
CMake/3.16.4-GCCcore-x.y.z OpenFOAM/v2006-foss-2020a
[removed most of the output here for clarity]
Where:
L: Module is loaded
Aliases: Aliases exist: foo/1.2.3 (1.2) means that "module load foo/1.2"
will load foo/1.2.3
D: Default Module
Use "module spider" to find all possible modules and extensions.
Use "module keyword key1 key2 ..." to search for all possible modules matching
any of the "keys".Verwendung von Software-Modulen in Skripten
Erstellen Sie einen Job, der in der Lage ist,
python3 --version auszuführen. Denken Sie daran, dass
standardmäßig keine Software geladen ist! Das Ausführen eines Jobs ist
genau wie das Anmelden am System (Sie sollten nicht davon ausgehen, dass
ein auf dem Anmeldeknoten geladenes Modul auch auf einem Rechenknoten
geladen ist).
- Software mit
module load softwareNameladen. - Entladen von Software mit
module unload - Das Modulsystem kümmert sich automatisch um Softwareversionen und Paketkonflikte.
Content from Übertragen von Dateien mit remote Computern
Zuletzt aktualisiert am 2026-02-26 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie übertrage ich Dateien zum (und vom) Cluster?
Ziele
- Übertragen Sie Dateien zu und von einem Computer-Cluster.
Die Arbeit auf einem remote Computer ist nicht sehr nützlich, wenn wir keine Dateien zum oder vom Cluster bekommen können. Es gibt mehrere Optionen für die Übertragung von Daten zwischen Computerressourcen mit Hilfe von CLI- und GUI-Dienstprogrammen, von denen wir einige vorstellen werden.
Herunterladen von Lektionsdateien aus dem Internet
Einer der einfachsten Wege, Dateien herunterzuladen, ist die
Verwendung von curl oder wget. Eines von
beiden ist normalerweise in den meisten Linux-Shells, auf Mac OS
Terminal und in GitBash installiert. Jede Datei, die über einen direkten
Link in Ihrem Webbrowser heruntergeladen werden kann, kann mit
curl oder wget heruntergeladen werden. Dies
ist ein schneller Weg, um Datensätze oder Quellcode herunterzuladen. Die
Syntax für diese Befehle lautet
wget [-O new_name] https://some/link/to/a/filecurl [-o new_name] https://some/link/to/a/file
Probieren Sie es aus, indem Sie etwas Material, das wir später benutzen werden, von einem Terminal auf Ihrem lokalen Rechner herunterladen, indem Sie die URL der aktuellen Codebase benutzen:
https://github.com/hpc-carpentry/amdahl/tarball/main
Download des “Tarballs”
Das Wort “tarball” in der obigen URL bezieht sich auf ein
komprimiertes Archivformat, das häufig unter Linux verwendet wird, dem
Betriebssystem, mit dem die meisten HPC-Cluster-Maschinen arbeiten. Ein
Tarball ist vergleichbar mit einer .zip-Datei. Die
eigentliche Dateierweiterung lautet .tar.gz, was den
zweistufigen Prozess zur Erstellung der Datei widerspiegelt: Die Dateien
oder Ordner werden mit tar zu einer einzigen Datei
zusammengeführt, die dann mit gzip komprimiert wird, so
dass die Dateierweiterung “tar-dot-g-z” lautet Das ist etwas langatmig,
deshalb sagen die Leute stattdessen oft “der xyz Tarball”.
Sie können auch die Erweiterung .tgz sehen, was nur eine
Abkürzung für .tar.gz ist.
Standardmäßig laden curl und wget Dateien
unter demselben Namen wie die URL herunter: in diesem Fall
main. Verwenden Sie einen der oben genannten Befehle, um
den Tarball unter amdahl.tar.gz zu speichern.
Nachdem Sie die Datei heruntergeladen haben, benutzen Sie
ls, um sie in Ihrem Arbeitsverzeichnis zu sehen:
Dateien archivieren
Eine der größten Herausforderungen bei der Übertragung von Daten zwischen remote HPC-Systemen ist die große Anzahl von Dateien. Die Übertragung jeder einzelnen Datei ist mit einem Overhead verbunden, und wenn wir eine große Anzahl von Dateien übertragen, verlangsamen diese Overheads unsere Übertragungen in hohem Maße.
Die Lösung für dieses Problem ist die Archivierung mehrerer
Dateien in eine kleinere Anzahl größerer Dateien, bevor wir die Daten
übertragen, um unsere Übertragungseffizienz zu verbessern. Manchmal wird
die Archivierung mit einer Komprimierung kombiniert, um die zu
übertragende Datenmenge zu verringern und so die Übertragung zu
beschleunigen. Der gebräuchlichste Archivierungsbefehl, den Sie auf
einem (Linux-)HPC-Cluster verwenden werden, ist tar.
tar kann verwendet werden, um Dateien und Ordner zu
einer einzigen Archivdatei zusammenzufassen und das Ergebnis optional zu
komprimieren. Schauen wir uns die Datei an, die wir von der
Lektionsseite heruntergeladen haben, amdahl.tar.gz.
Der Teil .gz steht für gzip, eine
Kompressionsbibliothek. Es ist üblich (aber nicht notwendig!), dass
diese Art von Datei durch das Lesen ihres Namens interpretiert werden
kann: Es scheint, dass jemand Dateien und Ordner, die sich auf etwas
namens “amdahl” beziehen, in eine einzige Datei mit tar
verpackt hat und dann dieses Archiv mit gzip komprimiert
hat, um Platz zu sparen.
Schauen wir mal, ob das der Fall ist, ohne die Datei zu
entpacken. tar gibt das Inhaltsverzeichnis
(“table of contents”) mit dem -t Flag aus,
für die mit dem -f Flag angegebene Datei, gefolgt vom
Dateinamen. Beachten Sie, dass Sie die beiden Flags verketten können:
das Schreiben von -t -f ist austauschbar mit dem Schreiben
von -tf zusammen. Allerdings muss das Argument nach
-f ein Dateiname sein, also funktioniert -ft
nicht.
BASH
[you@laptop:~]$ tar -tf amdahl.tar.gz
hpc-carpentry-amdahl-46c9b4b/
hpc-carpentry-amdahl-46c9b4b/.github/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/python-publish.yml
hpc-carpentry-amdahl-46c9b4b/.gitignore
hpc-carpentry-amdahl-46c9b4b/LICENSE
hpc-carpentry-amdahl-46c9b4b/README.md
hpc-carpentry-amdahl-46c9b4b/amdahl/
hpc-carpentry-amdahl-46c9b4b/amdahl/__init__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/__main__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/amdahl.py
hpc-carpentry-amdahl-46c9b4b/requirements.txt
hpc-carpentry-amdahl-46c9b4b/setup.pyDiese Beispielausgabe zeigt einen Ordner, der einige Dateien enthält,
wobei 46c9b4b ein 8-stelliger git Commit-Hash
ist, der sich ändert, wenn das Quellmaterial aktualisiert wird.
Nun wollen wir das Archiv entpacken. Wir werden tar mit
ein paar üblichen Flags ausführen:
-
-xum das Archiv zu extrahieren -
-vfür eine verböse Ausgabe -
-zfür gzip Kompression -
-f «tarball»für die zu entpackende Datei
Entpacken Sie das Archiv
Entpacken Sie den Quellcode-Tarball mit den obigen Flags in ein neues
Verzeichnis mit dem Namen “amdahl” unter Verwendung von
tar.
AUSGABE
hpc-carpentry-amdahl-46c9b4b/
hpc-carpentry-amdahl-46c9b4b/.github/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/python-publish.yml
hpc-carpentry-amdahl-46c9b4b/.gitignore
hpc-carpentry-amdahl-46c9b4b/LICENSE
hpc-carpentry-amdahl-46c9b4b/README.md
hpc-carpentry-amdahl-46c9b4b/amdahl/
hpc-carpentry-amdahl-46c9b4b/amdahl/__init__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/__main__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/amdahl.py
hpc-carpentry-amdahl-46c9b4b/requirements.txt
hpc-carpentry-amdahl-46c9b4b/setup.pyBeachten Sie, dass wir dank der Flaggenkonkatenation
-x -v -z -f nicht eingeben mussten, obwohl der Befehl in
beiden Fällen identisch funktioniert – solange die konkatenierte Liste
mit f endet, denn die nächste Zeichenkette muss den Namen
der zu extrahierenden Datei angeben.
Der Ordner hat einen unglücklichen Namen, also ändern wir ihn in etwas Passenderes.
Überprüfen Sie die Größe des extrahierten Verzeichnisses und
vergleichen Sie sie mit der Größe der komprimierten Datei, indem Sie
du für “disk usage” (also
Festplattennutzung) verwenden.
BASH
[you@laptop:~]$ du -sh amdahl.tar.gz
8.0K amdahl.tar.gz
[you@laptop:~]$ du -sh amdahl
48K amdahlTextdateien (einschließlich Python-Quellcode) lassen sich gut komprimieren: der “Tarball” ist nur ein Sechstel so groß wie die Rohdaten!
Wenn Sie den Prozess umkehren wollen - Rohdaten komprimieren statt
extrahieren - setzen Sie ein c-Flag anstelle von
x, setzen Sie den Dateinamen des Archivs und geben Sie dann
ein Verzeichnis zum Komprimieren an:
AUSGABE
amdahl/
amdahl/.github/
amdahl/.github/workflows/
amdahl/.github/workflows/python-publish.yml
amdahl/.gitignore
amdahl/LICENSE
amdahl/README.md
amdahl/amdahl/
amdahl/amdahl/__init__.py
amdahl/amdahl/__main__.py
amdahl/amdahl/amdahl.py
amdahl/requirements.txt
amdahl/setup.pyWenn Sie im obigen Befehl amdahl.tar.gz als Dateinamen
angeben, wird tar den bestehenden Tarball mit allen
Änderungen, die Sie an den Dateien vorgenommen haben, aktualisieren. Das
würde bedeuten, dass der neue Ordner amdahl zu dem
vorhandenen Ordner (hpc-carpentry-amdahl-46c9b4b)
innerhalb des Tarballs hinzugefügt wird, was die Größe des Archivs
verdoppelt!
Arbeiten mit Windows
Wenn Sie Textdateien von einem Windows-System auf ein Unix-System (Mac, Linux, BSD, Solaris, etc.) übertragen, kann dies zu Problemen führen. Windows kodiert seine Dateien etwas anders als Unix und fügt in jeder Zeile ein zusätzliches Zeichen ein.
Auf einem Unix-System endet jede Zeile in einer Datei mit einem
\n (Zeilenumbruch). Unter Windows endet jede Zeile in einer
Datei mit einem \r\n (Wagenrücklauf + Zeilenumbruch). Dies
verursacht manchmal Probleme.
Obwohl die meisten modernen Programmiersprachen und Software dies
korrekt handhaben, kann es in einigen seltenen Fällen zu Problemen
kommen. Die Lösung besteht darin, eine Datei mit dem Befehl
dos2unix von der Windows- in die Unix-Kodierung zu
konvertieren.
Sie können mit cat -A filename erkennen, ob eine Datei
Windows-Zeilenenden hat. Eine Datei mit Windows-Zeilenendungen hat
^M$ am Ende jeder Zeile. Eine Datei mit Unix-Zeilenendungen
hat $ am Ende einer Zeile.
Um die Datei zu konvertieren, führen Sie einfach
dos2unix filename aus. (Umgekehrt können Sie
unix2dos filename ausführen, um die Datei wieder in das
Windows-Format zu konvertieren)
Übertragen von einzelnen Dateien und Ordnern mit
scp
Um eine einzelne Datei in oder aus dem Cluster zu kopieren, können
wir scp (“secure copy”) verwenden. Die Syntax kann für neue
Benutzer ein wenig kompliziert sein, aber wir werden sie aufschlüsseln.
Der scp-Befehl ist ein Verwandter des
ssh-Befehls, den wir für den Zugriff auf das System
verwendet haben, und kann denselben
Public-Key-Authentifizierungsmechanismus verwenden.
Um eine Datei auf einen anderen Computer hochzuladen, lautet der Vorlagenbefehl
an, wobei @ und : Feldtrennzeichen sind und
remote_destination ein Pfad relativ zu Ihrem remote
Heimatverzeichnis oder ein neuer Dateiname ist, wenn Sie ihn ändern
möchten, oder sowohl ein relativer Pfad als auch ein neuer
Dateiname. Wenn Sie keinen bestimmten Ordner im Sinn haben, können Sie
das remote_destination weglassen und die Datei wird in Ihr
Heimatverzeichnis auf dem remote Computer kopiert (mit ihrem
ursprünglichen Namen). Wenn Sie ein remote_destination
einschließen, beachten Sie, dass scp dies genauso
interpretiert wie cp beim Erstellen von lokalen Kopien:
wenn es existiert und ein Ordner ist, wird die Datei in den Ordner
kopiert; wenn es existiert und eine Datei ist, wird die Datei mit dem
Inhalt von local_file überschrieben; wenn es nicht
existiert, wird angenommen, dass es ein Zieldateiname für
local_file ist.
So laden Sie das Unterrichtsmaterial in Ihr entferntes Heimatverzeichnis hoch:
Warum nicht direkt auf HPC Carpentry’s Cloud Cluster herunterladen?
Die meisten Computer-Cluster sind durch eine Firewall vor dem offenen Internet geschützt. Um die Sicherheit zu erhöhen, sind einige so konfiguriert, dass sie Datenverkehr eingehend, aber nicht ausgehend zulassen. Das bedeutet, dass ein authentifizierter Benutzer eine Datei an einen Cluster-Rechner senden kann, aber ein Cluster-Rechner kann keine Dateien vom Rechner eines Benutzers oder dem offenen Internet abrufen.
Versuchen Sie, die Datei direkt herunterzuladen. Beachten Sie, dass dies fehlschlagen kann, und das ist OK!
Warum nicht direkt auf HPC Carpentry’s Cloud Cluster herunterladen? (continued)
Hat es funktioniert? Wenn nicht, was sagt die Terminalausgabe über den Vorgang aus?
Übertragen eines Verzeichnisses
Um ein ganzes Verzeichnis zu übertragen, fügen wir das Flag
-r für “recursive” hinzu: Kopieren Sie das
angegebene Element, und jedes Element darunter, und jedes Element
darunter… bis Sie das untere Ende des Verzeichnisbaums erreichen, dessen
Wurzel der von Ihnen angegebene Ordnername ist.
Vorsicht
Bei einem großen Verzeichnis – entweder in der Größe oder in der
Anzahl der Dateien – kann das Kopieren mit -r sehr lange
dauern, bis es abgeschlossen ist.
Bei der Verwendung von scp ist Ihnen vielleicht
aufgefallen, dass ein : immer dem Namen des remote
Computers folgt. Eine Zeichenkette nach dem : gibt
das entfernte Verzeichnis an, in das Sie die Datei oder den Ordner
übertragen wollen, einschließlich eines neuen Namens, wenn Sie das
entfernte Material umbenennen wollen. Wenn Sie dieses Feld leer lassen,
ist scp standardmäßig Ihr Heimatverzeichnis und der Name
des zu übertragenden lokalen Materials.
Auf Linux-Computern ist / das Trennzeichen in Datei-
oder Verzeichnispfaden. Ein Pfad, der mit / beginnt, wird
absolut genannt, da es nichts oberhalb der Wurzel
/ geben kann. Ein Pfad, der nicht mit /
beginnt, wird relativ genannt, da er nicht an der Wurzel
verankert ist.
Wenn Sie eine Datei an einen Ort innerhalb Ihres Heimatverzeichnisses
hochladen wollen - was oft der Fall ist -, dann brauchen Sie kein
führendes /. Nach dem : können Sie
den Zielpfad relativ zu Ihrem Heimatverzeichnis angeben. Wenn Ihr
Heimatverzeichnis das Ziel ist, können Sie das Zielfeld leer
lassen oder der Vollständigkeit halber ~ - die Abkürzung
für Ihr Heimatverzeichnis - eingeben.
Mit scp ist ein abschließender Schrägstrich im
Zielverzeichnis optional und hat keine Auswirkungen. Ein nachgestellter
Schrägstrich im Quellverzeichnis ist wichtig für andere Befehle, wie
rsync.
Eine Anmerkung zu rsync
Wenn Sie Erfahrung mit der Übertragung von Dateien haben, werden Sie
den Befehl scp vielleicht als einschränkend empfinden. Das
rsync Dienstprogramm bietet
erweiterte Funktionen für die Dateiübertragung und ist in der Regel
schneller als scp und sftp (siehe unten). Es
ist besonders nützlich für die Übertragung von großen und/oder vielen
Dateien und für die Synchronisierung von Ordnerinhalten zwischen
Computern.
Die Syntax ist ähnlich wie bei scp. Zum Übertragen
auf einen anderen Computer mit häufig verwendeten Optionen:
Die Optionen sind:
-
-a(ein Archiv), um u.a. Datei-Zeitstempel, Berechtigungen und Ordner zu erhalten; impliziert Rekursion -
-v(verbose), um eine ausführliche Ausgabe zu erhalten, die Ihnen hilft, die Übertragung zu überwachen -
-P(partial/progress), um teilweise übertragene Dateien im Falle einer Unterbrechung aufzubewahren und auch den Fortschritt der Übertragung anzuzeigen.
Um ein Verzeichnis rekursiv zu kopieren, können wir die gleichen Optionen verwenden:
Wie geschrieben, wird das lokale Verzeichnis und sein Inhalt unter Ihrem Heimatverzeichnis auf dem remote System abgelegt. Wenn ein abschließender Schrägstrich an die Quelle angehängt wird, wird kein neues Verzeichnis erstellt, das dem übertragenen Verzeichnis entspricht, und der Inhalt des Quellverzeichnisses wird direkt in das Zielverzeichnis kopiert.
Um eine Datei herunterzuladen, ändern wir einfach die Quelle und das Ziel:
Dateiübertragungen, die sowohl scp als auch
rsync benutzen, verwenden SSH, um die über das Netzwerk
gesendeten Daten zu verschlüsseln. Wenn Sie also eine Verbindung über
SSH herstellen können, werden Sie in der Lage sein, Dateien zu
übertragen. SSH verwendet standardmäßig den Netzwerkanschluss 22. Wenn
ein benutzerdefinierter SSH-Port verwendet wird, müssen Sie ihn mit dem
entsprechenden Flag angeben, oft -p, -P oder
--port. Prüfen Sie --help oder die
man Seite, wenn Sie sich unsicher sind.
BASH
[you@laptop:~]$ man rsync
[you@laptop:~]$ rsync --help | grep port
--port=PORT specify double-colon alternate port number
See http://rsync.samba.org/ for updates, bug reports, and answers
[you@laptop:~]$ rsync --port=768 amdahl.tar.gz yourUsername@cluster.hpc-carpentry.org:(Beachten Sie, dass dieser Befehl fehlschlägt, da der korrekte Port in diesem Fall der Standardwert ist: 22.)
Interaktives Übertragen von Dateien mit FileZilla
FileZilla ist ein plattformübergreifender Client für das
Herunterladen und Hochladen von Dateien auf und von einem remote
Computer. Er ist absolut narrensicher und funktioniert immer gut. Er
verwendet das sftp-Protokoll. Sie können mehr über die
Verwendung des sftp-Protokolls in der Kommandozeile in der
Lektionsdiskussion lesen.
Laden Sie den FileZilla-Client von https://filezilla-project.org herunter und installieren Sie ihn. Nach der Installation und dem Öffnen des Programms sollten Sie auf der linken Seite des Bildschirms ein Fenster mit einem Dateibrowser Ihres lokalen Systems sehen. Wenn Sie sich mit dem Cluster verbinden, werden Ihre Clusterdateien auf der rechten Seite angezeigt.
Um sich mit dem Cluster zu verbinden, müssen wir nur unsere Anmeldedaten oben auf dem Bildschirm eingeben:
- Host:
sftp://cluster.hpc-carpentry.org - Benutzer: Ihr Clusternutzername
- Passwort: Ihr Clusterkennwort
- Port: (leer lassen, um den Standardport zu verwenden)
Drücken Sie “Quickconnect”, um eine Verbindung herzustellen. Ihre remote Dateien sollten auf der rechten Seite des Bildschirms angezeigt werden. Sie können Dateien per Drag-and-Drop zwischen der linken (lokalen) und der rechten (remote) Seite des Bildschirms verschieben, um Dateien zu übertragen.
Wenn Sie große Dateien (in der Regel größer als ein Gigabyte) von
einem remote Computer auf einen anderen übertragen müssen, melden Sie
sich per SSH auf dem Computer an, auf dem sich die Dateien befinden, und
verwenden Sie scp oder rsync, um die Dateien
auf den anderen Computer zu übertragen. Dies ist effizienter als die
Verwendung von FileZilla (oder ähnlichen Anwendungen), die von der
Quelle auf Ihren lokalen Rechner und dann auf den Zielrechner kopieren
würden.
-
wgetundcurl -Oladen eine Datei aus dem Internet herunter. -
scpundrsyncübertragen Dateien zu und von Ihrem Computer. - Sie können einen SFTP-Client wie FileZilla verwenden, um Dateien über eine grafische Benutzeroberfläche zu übertragen.
Content from Ausführen eines parallelen Auftrags
Zuletzt aktualisiert am 2026-02-26 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann man eine Aufgabe parallel ausführen?
- Welche Vorteile ergeben sich aus der parallelen Ausführung?
- Wo liegen die Grenzen des Gewinns bei paralleler Ausführung?
Ziele
- Installieren Sie ein Python-Paket mit
pip - Bereiten Sie ein Auftragsskript für das parallele Programm vor.
- Starten Sie Aufträge mit paralleler Ausführung.
- Aufzeichnung und Zusammenfassung des Zeitplans und der Genauigkeit von Aufträgen.
- Beschreiben Sie die Beziehung zwischen Job-Parallelität und Leistung.
Wir haben jetzt die Werkzeuge, die wir brauchen, um einen Multiprozessor-Job auszuführen. Dies ist ein sehr wichtiger Aspekt von HPC-Systemen, da die Parallelität eines der wichtigsten Werkzeuge ist, um die Leistung von Berechnungsaufgaben zu verbessern.
Wenn Sie die Verbindung getrennt haben, melden Sie sich wieder am Cluster an.
Installieren Sie das Amdahl-Programm
Nachdem wir den Amdahl-Quellcode auf dem Cluster haben, können wir
ihn installieren, was den Zugriff auf die ausführbare Datei
amdahl ermöglicht. Wechseln Sie in das extrahierte
Verzeichnis und verwenden Sie dann den Package Installer für Python oder
pip, um es in Ihrem (“user”) Home-Verzeichnis zu
installieren:
Amdahl ist Python Code
Das Amdahl-Programm ist in Python geschrieben, und um es zu
installieren oder zu benutzen, muss die ausführbare Datei
python3 auf dem Anmeldeknoten gefunden werden. Wenn es
nicht gefunden werden kann, versuchen Sie, die verfügbaren Module mit
module avail aufzulisten, laden Sie das entsprechende Modul
und versuchen Sie den Befehl erneut.
MPI für Python
Der Amdahl-Code ist von einem Prozess abhängig:
mpi4py. Wenn es nicht bereits auf dem Cluster
installiert ist, wird pip versuchen, mpi4py aus dem
Internet zu laden und für Sie zu installieren. Wenn dies aufgrund einer
Einweg-Firewall fehlschlägt, müssen Sie mpi4py auf Ihrem lokalen Rechner
abrufen und hochladen, so wie wir es für Amdahl getan haben.
Abrufen und Hochladen von
mpi4py
Wenn die Installation von Amdahl fehlgeschlagen ist, weil mpi4py
nicht installiert werden konnte, rufen Sie das Tarball von https://github.com/mpi4py/mpi4py/tarball/master ab,
synchronisieren Sie es anschließend per rsync mit dem
Cluster, extrahieren Sie es und installieren Sie es:
BASH
[you@laptop:~]$ wget -O mpi4py.tar.gz https://github.com/mpi4py/mpi4py/releases/download/3.1.4/mpi4py-3.1.4.tar.gz
[you@laptop:~]$ scp mpi4py.tar.gz yourUsername@cluster.hpc-carpentry.org:
# or
[you@laptop:~]$ rsync -avP mpi4py.tar.gz yourUsername@cluster.hpc-carpentry.org:BASH
[you@laptop:~]$ ssh yourUsername@cluster.hpc-carpentry.org
[yourUsername@login1 ~] tar -xvzf mpi4py.tar.gz # extract the archive
[yourUsername@login1 ~] mv mpi4py* mpi4py # rename the directory
[yourUsername@login1 ~] cd mpi4py
[yourUsername@login1 ~] python3 -m pip install --user .
[yourUsername@login1 ~] cd ../amdahl
[yourUsername@login1 ~] python3 -m pip install --user .Wenn pip eine Warnung
auslöst…
pip kann eine Warnung ausgeben, dass die Binärdateien
Ihres Benutzerpakets nicht in Ihrem PATH sind.
WARNUNG
WARNING: The script amdahl is installed in "${HOME}/.local/bin" which is
not on PATH. Consider adding this directory to PATH or, if you prefer to
suppress this warning, use --no-warn-script-location.Um zu überprüfen, ob diese Warnung ein Problem darstellt, verwenden
Sie which, um nach dem Programm amdahl zu
suchen:
Wenn der Befehl keine Ausgabe liefert und eine neue
Eingabeaufforderung anzeigt, bedeutet dies, dass die Datei
amdahl nicht gefunden wurde. Sie müssen die
Umgebungsvariable mit dem Namen PATH aktualisieren, um den
fehlenden Ordner aufzunehmen. Bearbeiten Sie Ihre
Shell-Konfigurationsdatei wie folgt, melden Sie sich dann vom Cluster ab
und wieder an, damit die Änderung wirksam wird.
AUSGABE
export PATH=${PATH}:${HOME}/.local/binNachdem Sie sich wieder bei cluster.hpc-carpentry.org angemeldet
haben, sollte which in der Lage sein, amdahl
ohne Schwierigkeiten zu finden. Wenn Sie ein Python-Modul laden mussten,
laden Sie es erneut.
Hilfe!
Viele Befehlszeilenprogramme enthalten eine “Hilfe”-Meldung.
Probieren Sie es mit amdahl:
AUSGABE
usage: amdahl [-h] [-p [PARALLEL_PROPORTION]] [-w [WORK_SECONDS]] [-t] [-e] [-j [JITTER_PROPORTION]]
optional arguments:
-h, --help show this help message and exit
-p [PARALLEL_PROPORTION], --parallel-proportion [PARALLEL_PROPORTION]
Parallel proportion: a float between 0 and 1
-w [WORK_SECONDS], --work-seconds [WORK_SECONDS]
Total seconds of workload: an integer greater than 0
-t, --terse Format output as a machine-readable object for easier analysis
-e, --exact Exactly match requested timing by disabling random jitter
-j [JITTER_PROPORTION], --jitter-proportion [JITTER_PROPORTION]
Random jitter: a float between -1 and +1Diese Nachricht sagt nicht viel darüber aus, was das Programm tut, aber sie teilt uns die wichtigen Flags mit, die wir beim Start des Programms verwenden sollten.
Ausführen des Jobs auf einem Rechenknoten
Erstellen Sie eine Einreichungsdatei, die eine Aufgabe auf einem einzigen Knoten anfordert, und starten Sie sie.
BASH
#!/bin/bash
#SBATCH -J solo-job
#SBATCH -p cpubase_bycore_b1
#SBATCH -N 1
#SBATCH -n 1
# Load the computing environment we need
module load Python
# Execute the task
amdahlVerwenden Sie wie bisher die Statusbefehle Slurm, um zu überprüfen, ob Ihr Auftrag läuft und wann er endet:
Verwenden Sie ls, um die Ausgabedatei zu finden. Das
Flag -t sortiert in umgekehrter chronologischer
Reihenfolge: das Neueste zuerst. Wie lautete die Ausgabe?
Die Cluster-Ausgabe sollte in eine Datei in dem Ordner geschrieben werden, aus dem Sie den Job gestartet haben. Zum Beispiel,
AUSGABE
slurm-347087.out serial-job.sh amdahl README.md LICENSE.txtAUSGABE
Doing 30.000 seconds of 'work' on 1 processor,
which should take 30.000 seconds with 0.850 parallel proportion of the workload.
Hello, World! I am process 0 of 1 on smnode1. I will do all the serial 'work' for 4.500 seconds.
Hello, World! I am process 0 of 1 on smnode1. I will do parallel 'work' for 25.500 seconds.
Total execution time (according to rank 0): 30.033 secondsWie wir bereits gesehen haben, legen zwei der
amdahl-Programmflags die Menge der Arbeit und den Anteil
der parallelen Arbeit fest. Anhand der Ausgabe können wir sehen, dass
der Code eine Vorgabe von 30 Sekunden Arbeit verwendet, die zu 85 %
parallel ist. Das Programm lief insgesamt etwas über 30 Sekunden, und
wenn wir die Zahlen durchgehen, stimmt es, dass 15 % davon als “seriell”
und 85 % als “parallel” gekennzeichnet waren.
Da wir dem Job nur eine CPU zugewiesen haben, war dieser Job nicht wirklich parallel: derselbe Prozessor führte die “serielle” Arbeit 4,5 Sekunden lang aus, dann den “parallelen” Teil 25,5 Sekunden lang, und es wurde keine Zeit gespart. Der Cluster kann es besser, wenn wir ihn fragen.
Ausführen des parallelen Jobs
Das Programm amdahl verwendet das Message Passing
Interface (MPI) für die Parallelität - ein gängiges Werkzeug auf
HPC-Systemen.
Was ist MPI?
Das Message Passing Interface ist eine Reihe von Werkzeugen, die es mehreren gleichzeitig laufenden Aufgaben ermöglichen, miteinander zu kommunizieren. Typischerweise wird eine einzelne ausführbare Datei mehrfach ausgeführt, möglicherweise auf verschiedenen Rechnern, und die MPI-Werkzeuge werden verwendet, um jede Instanz der ausführbaren Datei über ihre Geschwisterprozesse und die jeweilige Instanz zu informieren. MPI bietet auch Werkzeuge für die Kommunikation zwischen Instanzen, um die Arbeit zu koordinieren, Informationen über Elemente der Aufgabe auszutauschen oder Daten zu übertragen. Eine MPI-Instanz hat normalerweise ihre eigene Kopie aller lokalen Variablen.
Während MPI-fähige ausführbare Programme im Allgemeinen als
eigenständige Programme ausgeführt werden können, müssen sie, um
parallel ausgeführt werden zu können, eine MPI Laufzeitumgebung
verwenden, bei der es sich um eine spezielle Implementierung des MPI
Standards handelt. Um die MPI-Umgebung zu aktivieren, sollte
das Programm mit einem Befehl wie mpiexec (oder
mpirun, oder srun, usw., je nach der zu
verwendenden MPI-Laufzeitumgebung) gestartet werden, wodurch
sichergestellt wird, dass die entsprechende Laufzeitunterstützung für
Parallelität enthalten ist.
MPI Laufzeitargumente
Befehle wie mpiexec können viele Argumente annehmen, die
angeben, wie viele Maschinen an der Ausführung teilnehmen sollen, und
Sie benötigen diese Argumente, wenn Sie ein MPI-Programm alleine
ausführen möchten (z. B. auf Ihrem Laptop). Im Zusammenhang mit einem
Warteschlangensystem ist es jedoch häufig der Fall, dass die
MPI-Laufzeit die notwendigen Parameter vom Warteschlangensystem erhält,
indem sie die Umgebungsvariablen untersucht, die beim Start des Auftrags
gesetzt wurden.
Ändern wir das Jobskript, um mehr Kerne anzufordern und die MPI-Laufzeit zu nutzen.
BASH
[yourUsername@login1 ~] cp serial-job.sh parallel-job.sh
[yourUsername@login1 ~] nano parallel-job.sh
[yourUsername@login1 ~] cat parallel-job.shBASH
#!/bin/bash
#SBATCH -J parallel-job
#SBATCH -p cpubase_bycore_b1
#SBATCH -N 1
#SBATCH -n 4
# Load the computing environment we need
# (mpi4py and numpy are in SciPy-bundle)
module load Python
module load SciPy-bundle
# Execute the task
mpiexec amdahlSenden Sie dann Ihren Auftrag ab. Beachten Sie, dass sich der Übermittlungsbefehl im Vergleich zur Übermittlung des seriellen Auftrags nicht wirklich geändert hat: Alle parallelen Einstellungen befinden sich in der Batch-Datei und nicht in der Befehlszeile.
Verwenden Sie wie bisher die Statusbefehle, um zu überprüfen, wann Ihr Auftrag läuft.
AUSGABE
slurm-347178.out parallel-job.sh slurm-347087.out serial-job.sh amdahl README.md LICENSE.txtAUSGABE
Doing 30.000 seconds of 'work' on 4 processors,
which should take 10.875 seconds with 0.850 parallel proportion of the workload.
Hello, World! I am process 0 of 4 on smnode1. I will do all the serial 'work' for 4.500 seconds.
Hello, World! I am process 2 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Hello, World! I am process 1 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Hello, World! I am process 3 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Hello, World! I am process 0 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Total execution time (according to rank 0): 10.888 secondsIst es 4× schneller?
Der parallele Auftrag erhielt 4× mehr Prozessoren als der serielle Auftrag: Bedeutet das, dass er in ¼ der Zeit fertig wurde?
Der parallele Auftrag hat weniger Zeit benötigt: 11 Sekunden sind besser als 30! Aber es ist nur eine 2,7-fache Verbesserung, nicht eine 4-fache.
Sehen Sie sich die Ausgabe des Jobs an:
- Während “Prozess 0” serielle Arbeit verrichtete, erledigten die Prozesse 1 bis 3 ihre parallele Arbeit.
- Während Prozess 0 seine parallele Arbeit nachholte, tat der Rest gar nichts.
Prozess 0 muss immer erst seine serielle Aufgabe beenden, bevor er mit der parallelen Arbeit beginnen kann. Damit wird eine untere Grenze für die Zeit gesetzt, die diese Aufgabe benötigt, egal wie viele Kerne man ihr zuordnet.
Dies ist das Grundprinzip des Amdahl’schen Gesetzes, das eine Möglichkeit ist, Verbesserungen der Ausführungszeit für eine feste Arbeitslast vorherzusagen, die bis zu einem gewissen Grad unterteilt und parallel ausgeführt werden kann.
Wie stark verbessert die parallele Ausführung die Leistung?
Theoretisch sollte die Aufteilung einer perfekt parallelen Berechnung auf n MPI-Prozesse zu einer Verringerung der Gesamtlaufzeit um den Faktor n führen. Wie wir soeben gesehen haben, benötigen reale Programme eine gewisse Zeit, damit die MPI-Prozesse kommunizieren und sich koordinieren können, und einige Arten von Berechnungen können nicht aufgeteilt werden: Sie laufen effektiv nur auf einer einzigen CPU.
Wenn die MPI-Prozesse auf verschiedenen physischen CPUs im Computer oder auf mehreren Rechenknoten arbeiten, wird sogar mehr Zeit für die Kommunikation benötigt, als wenn alle Prozesse auf einer einzigen CPU arbeiten.
In der Praxis ist es üblich, die Parallelität eines MPI-Programms wie folgt zu bewerten
- das Programm über einen Bereich von CPU-Zahlen laufen,
- Aufzeichnung der Ausführungszeit bei jedem Durchlauf,
- Vergleich der jeweiligen Ausführungszeit mit der Zeit bei Verwendung einer einzigen CPU.
Da “mehr besser ist” - eine Verbesserung ist leichter zu interpretieren, wenn eine bestimmte Größe zunimmt, als wenn sie abnimmt - werden Vergleiche mit dem Beschleunigungsfaktor S durchgeführt, der als die Ausführungszeit auf einer CPU geteilt durch die Ausführungszeit auf mehreren CPUs berechnet wird. Für ein perfekt paralleles Programm würde ein Diagramm des Beschleunigungsfaktors S gegen die Anzahl der CPUs n eine gerade Linie ergeben, S = n.
Lassen wir einen weiteren Job laufen, damit wir sehen können, wie
nahe unser amdahl-Code einer geraden Linie kommt.
BASH
#!/bin/bash
#SBATCH -J parallel-job
#SBATCH -p cpubase_bycore_b1
#SBATCH -N 1
#SBATCH -n 8
# Load the computing environment we need
# (mpi4py and numpy are in SciPy-bundle)
module load Python
module load SciPy-bundle
# Execute the task
mpiexec amdahlSenden Sie dann Ihren Auftrag ab. Beachten Sie, dass sich der Übermittlungsbefehl im Vergleich zur Übermittlung des seriellen Auftrags nicht wirklich geändert hat: Alle parallelen Einstellungen befinden sich in der Batch-Datei und nicht in der Befehlszeile.
Verwenden Sie wie bisher die Statusbefehle, um zu überprüfen, wann Ihr Auftrag läuft.
AUSGABE
slurm-347271.out parallel-job.sh slurm-347178.out slurm-347087.out serial-job.sh amdahl README.md LICENSE.txtAUSGABE
which should take 7.688 seconds with 0.850 parallel proportion of the workload.
Hello, World! I am process 4 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 0 of 8 on smnode1. I will do all the serial 'work' for 4.500 seconds.
Hello, World! I am process 2 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 1 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 3 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 5 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 6 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 7 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 0 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Total execution time (according to rank 0): 7.697 secondsNicht-lineare Ausgabe
Wenn wir den Job mit 4 parallelen Workern ausgeführt haben, hat der serielle Job zuerst seine Ausgabe geschrieben, dann haben die parallelen Prozesse ihre Ausgabe geschrieben, wobei Prozess 0 zuerst und zuletzt kam.
Bei 8 Workern ist dies nicht der Fall: Da die parallelen Worker weniger Zeit benötigen als die seriellen, ist es schwer zu sagen, welcher Prozess seine Ausgabe zuerst schreiben wird, außer dass es nicht Prozess 0 sein wird!
Fassen wir nun die Zeit zusammen, die jeder Job für seine Ausführung benötigt hat:
| Number of CPUs | Runtime (sec) |
|---|---|
| 1 | 30.033 |
| 4 | 10.888 |
| 8 | 7.697 |
Dann verwenden Sie die erste Zeile, um die Geschwindigkeitssteigerung \(S\) zu berechnen, indem Sie Python als Befehlszeilenrechner und die Formel
\[ S(t_{n}) = \frac{t_{1}}{t_{n}} \]
| Number of CPUs | Speedup | Ideal |
|---|---|---|
| 1 | 1.0 | 1 |
| 4 | 2.75 | 4 |
| 8 | 3.90 | 8 |
Aus den Job-Ausgabedateien geht hervor, dass dieses Programm 85 % seiner Arbeit parallel ausführt und 15 % seriell abläuft. Dies scheint recht hoch zu sein, aber unsere schnelle Untersuchung der Beschleunigung zeigt, dass wir 8 oder 9 Prozessoren parallel verwenden müssen, um eine 4fache Beschleunigung zu erreichen. In realen Programmen wird der Beschleunigungsfaktor beeinflusst durch
- CPU-Design
- Kommunikationsnetz zwischen Rechenknoten
- Implementierungen der MPI-Bibliothek
- Einzelheiten zum MPI-Programm selbst
Mit Hilfe des Amdahlschen Gesetzes können Sie beweisen, dass es unmöglich ist, mit diesem Programm eine 8-fache Beschleunigung zu erreichen, egal wie viele Prozessoren Sie zur Verfügung haben. Die Einzelheiten dieser Analyse mit den entsprechenden Ergebnissen werden in der nächsten Klasse des HPC Carpentry Workshops HPC Workflows behandelt.
In einer HPC-Umgebung versuchen wir, die Ausführungszeit für alle Arten von Aufträgen zu reduzieren, und MPI ist eine sehr gängige Methode, um Dutzende, Hunderte oder Tausende von CPUs zur Lösung eines einzigen Problems zu kombinieren. Um mehr über Parallelisierung zu erfahren, lesen Sie die Lektion parallel-novice.
- Parallele Programmierung ermöglicht es Anwendungen, die Vorteile paralleler Hardware zu nutzen.
- Das Warteschlangensystem erleichtert die Ausführung von parallelen Aufgaben.
- Leistungssteigerungen durch parallele Ausführung skalieren nicht linear.
Content from Effektive Nutzung von Ressourcen
Zuletzt aktualisiert am 2026-02-26 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich vergangene Aufträge überprüfen?
- Wie kann ich dieses Wissen nutzen, um ein genaueres Einreichungsskript zu erstellen?
Ziele
- Job-Statistiken nachschlagen.
- Stellen Sie genauere Ressourcenanforderungen in Jobskripten auf der Grundlage von Daten, die die vergangene Leistung beschreiben.
Wir haben alle Fertigkeiten behandelt, die Sie für die Interaktion mit einem HPC-Cluster benötigen: Anmeldung über SSH, Laden von Softwaremodulen, Übermittlung paralleler Aufträge und Auffinden der Ausgabe. Jetzt geht es darum, die Ressourcennutzung abzuschätzen und zu verstehen, warum das wichtig sein kann.
Schätzung der benötigten Ressourcen durch den Scheduler
Auch wenn wir die Anforderung von Ressourcen beim Scheduler bereits mit dem π-Code behandelt haben, woher wissen wir, welche Art von Ressourcen die Software überhaupt benötigt und welchen Bedarf sie jeweils hat? Im Allgemeinen wissen wir nicht, wie viel Arbeitsspeicher oder Rechenzeit ein Programm benötigen wird, es sei denn, die Software-Dokumentation oder Benutzerberichte geben uns eine Vorstellung davon.
Lesen Sie die Dokumentation
Die meisten HPC-Einrichtungen verfügen über eine Dokumentation in Form eines Wikis, einer Website oder eines Dokuments, das Ihnen bei der Registrierung für ein Konto zugeschickt wird. Werfen Sie einen Blick auf diese Ressourcen und suchen Sie nach der Software, die Sie verwenden möchten: Vielleicht hat jemand eine Anleitung geschrieben, wie Sie das Beste daraus machen können.
Eine bequeme Methode, um herauszufinden, welche Ressourcen für die
erfolgreiche Ausführung eines Jobs benötigt werden, besteht darin, einen
Testjob abzuschicken und dann den Scheduler mit
sacct -u yourUsername nach dessen Auswirkungen zu fragen.
Sie können dieses Wissen nutzen, um den nächsten Job mit einer genaueren
Abschätzung seiner Belastung des Systems einzurichten. Eine gute
allgemeine Regel ist es, den Scheduler um 20 bis 30 % mehr Zeit und
Speicher zu bitten, als Sie erwarten, daß der Job benötigt. Dadurch wird
sichergestellt, dass geringfügige Schwankungen in der Laufzeit oder im
Speicherbedarf nicht dazu führen, dass Ihr Auftrag vom Scheduler
abgebrochen wird. Wenn Sie zu viel verlangen, kann es sein, dass Ihr
Auftrag nicht ausgeführt werden kann, obwohl genügend Ressourcen zur
Verfügung stehen, weil der Scheduler darauf wartet, dass andere Aufträge
beendet werden und die Ressourcen freigeben, die für die von Ihnen
verlangte Menge benötigt werden.
Statistiken
Da wir amdahl bereits zur Ausführung im Cluster
eingereicht haben, können wir den Scheduler abfragen, um zu sehen, wie
lange unser Job gedauert hat und welche Ressourcen verwendet wurden. Wir
werden sacct -u yourUsername verwenden, um Statistiken über
parallel-job.sh zu erhalten.
AUSGABE
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
7 file.sh cpubase_b+ def-spons+ 1 COMPLETED 0:0
7.batch batch def-spons+ 1 COMPLETED 0:0
7.extern extern def-spons+ 1 COMPLETED 0:0
8 file.sh cpubase_b+ def-spons+ 1 COMPLETED 0:0
8.batch batch def-spons+ 1 COMPLETED 0:0
8.extern extern def-spons+ 1 COMPLETED 0:0
9 example-j+ cpubase_b+ def-spons+ 1 COMPLETED 0:0
9.batch batch def-spons+ 1 COMPLETED 0:0
9.extern extern def-spons+ 1 COMPLETED 0:0Hier werden alle Aufträge (oder Jobs) angezeigt, die heute ausgeführt wurden (beachten Sie, dass es mehrere Einträge pro Auftrag gibt). Um Informationen über einen bestimmten Auftrag zu erhalten (z. B. 347087), ändern wir den Befehl leicht ab.
Hier werden viele Informationen angezeigt, und zwar jede einzelne
Information, die der Scheduler über Ihren Job sammelt. Es kann sinnvoll
sein, diese Informationen nach less umzuleiten, um sie
leichter einsehen zu können (verwenden Sie die Pfeiltasten links und
rechts, um durch die Felder zu blättern).
Diskussion
Diese Ansicht hilft beim Vergleich der angeforderten und tatsächlich genutzten Zeit, der Verweildauer in der Warteschlange vor dem Start und des Speicherbedarfs auf dem/den Rechenknoten.
Wie genau waren unsere Schätzungen?
Verbesserung der Ressourcenanfragen
Aus der Job-Historie geht hervor, dass die Ausführung von
amdahl Jobs in höchstens ein paar Minuten abgeschlossen
war, sobald sie versandt wurden. Die von uns im Auftragsskript
angegebene Zeit war viel zu lang! Dadurch wird es für das
Warteschlangensystem schwieriger, genau abzuschätzen, wann Ressourcen
für andere Aufträge frei werden. In der Praxis bedeutet dies, dass das
Warteschlangensystem mit der Abfertigung unseres Auftrags
amdahl wartet, bis das gesamte angeforderte Zeitfenster
geöffnet wird, anstatt ihn in ein viel kürzeres Zeitfenster zu
“schieben”, in dem der Auftrag tatsächlich beendet werden könnte. Wenn
Sie die erwartete Laufzeit im Einreichungsskript genauer angeben, können
Sie die Überlastung des Clusters verringern und Ihren Auftrag
möglicherweise früher abfertigen lassen.
Eingrenzung der Zeitabschätzung
Bearbeiten Sie parallel_job.sh, um eine bessere
Zeitschätzung zu erhalten. Wie nah können Sie herankommen?
Hinweis: Verwenden Sie -t.
- Präzise Jobskripte helfen dem Warteschlangensystem bei der effizienten Zuweisung gemeinsamer Ressourcen.
Content from Gemeinsame Ressourcen verantwortungsvoll nutzen
Zuletzt aktualisiert am 2026-02-26 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich ein verantwortlicher Nutzer sein?
- Wie kann ich meine Daten schützen?
- Wie kann ich am besten große Datenmengen von einem HPC-System abrufen?
Ziele
- Beschreiben Sie, wie sich die Aktionen eines einzelnen Nutzers auf die Erfahrungen anderer Nutzer in einem gemeinsam genutzten System auswirken können.
- Diskutieren Sie das Verhalten eines rücksichtsvollen gemeinsamen Systembürgers.
- Erklären Sie, wie wichtig es ist, kritische Daten zu sichern.
- Beschreiben Sie die Herausforderungen bei der Übertragung großer Datenmengen von HPC-Systemen.
- Konvertiert viele Dateien in eine einzige Archivdatei mit tar.
Einer der Hauptunterschiede zwischen der Nutzung entfernter HPC-Ressourcen und Ihrem eigenen System (z.B. Ihrem Laptop) ist, dass entfernte Ressourcen gemeinsam genutzt werden. Wie viele Nutzer sich die Ressourcen gleichzeitig teilen, ist von System zu System unterschiedlich, aber es ist unwahrscheinlich, dass Sie jemals der einzige Nutzer sind, der an einem solchen System angemeldet ist oder es benutzt.
Der weit verbreitete Einsatz von Scheduling-Systemen, bei denen Nutzer Jobs auf HPC-Ressourcen einreichen, ist ein natürliches Ergebnis der gemeinsamen Nutzung dieser Ressourcen. Es gibt noch andere Dinge, die Sie als aufrechtes Mitglied der Gemeinschaft beachten müssen.
Sei nett zu den Login-Knoten
Der Login-Knoten ist oft damit beschäftigt, alle angemeldeten Nutzer zu verwalten, Dateien zu erstellen und zu bearbeiten und Software zu kompilieren. Wenn dem Rechner der Speicher oder die Verarbeitungskapazität ausgeht, wird er sehr langsam und für alle unbrauchbar. Der Rechner soll zwar genutzt werden, aber bitte nur so, dass die anderen Nutzer nicht beeinträchtigt werden.
Anmeldeknoten sind immer der richtige Ort, um Aufträge zu starten. Cluster-Richtlinien variieren, aber sie können auch zum Testen von Arbeitsabläufen verwendet werden, und in einigen Fällen können sie erweiterte clusterspezifische Debugging- oder Entwicklungstools hosten. Im Cluster gibt es möglicherweise Module, die geladen werden müssen, möglicherweise in einer bestimmten Reihenfolge, und Pfade oder Bibliotheksversionen, die sich von Ihrem Laptop unterscheiden. Ein interaktiver Testlauf auf dem Hauptknoten ist eine schnelle und zuverlässige Methode, um diese Probleme zu entdecken und zu beheben.
Anmeldeknoten sind eine gemeinsam genutzte Ressource
Denken Sie daran, dass der Login-Knoten mit allen anderen Nutzern geteilt wird und dass Ihre Aktionen Probleme für andere Personen verursachen könnten. Denken Sie daher sorgfältig über die möglichen Auswirkungen von Befehlen nach, die große Mengen an Ressourcen verbrauchen können.
Sie sind sich nicht sicher? Fragen Sie Ihren freundlichen Systemadministrator (“sysadmin”), ob das, was Sie vorhaben, für den Login-Knoten geeignet ist, oder ob es einen anderen Mechanismus gibt, um es sicher zu erledigen.
Sie können immer die Befehle top und ps ux
verwenden, um die Prozesse aufzulisten, die auf dem Login-Knoten laufen,
zusammen mit der Menge an CPU und Speicher, die sie verwenden. Wenn
diese Überprüfung ergibt, dass der Login-Knoten einigermaßen untätig
ist, können Sie ihn gefahrlos für Ihre nicht-routinemäßige
Verarbeitungsaufgabe verwenden. Wenn etwas schief geht - der Prozess
braucht zu lange oder antwortet nicht - können Sie den Befehl
kill zusammen mit der PID verwenden, um den
Prozess zu beenden.
Login-Knoten-Knigge
Welcher dieser Befehle wäre eine Routineaufgabe, die auf dem Anmeldeknoten ausgeführt werden sollte?
python physics_sim.pymakecreate_directories.shmolecular_dynamics_2tar -xzf R-3.3.0.tar.gz
Das Erstellen von Software, das Anlegen von Verzeichnissen und das
Entpacken von Software sind übliche und akzeptable > Aufgaben für den
Login-Knoten: Die Optionen #2 (make), #3
(mkdir) und #5 (tar) sind wahrscheinlich OK.
Beachten Sie, dass Skriptnamen nicht immer ihren Inhalt widerspiegeln:
bevor Sie #3 starten, prüfen Sie bitte
less create_directories.sh und stellen Sie sicher, dass es
sich nicht um ein trojanisches Pferd handelt.
Das Ausführen ressourcenintensiver Anwendungen ist verpönt. Wenn Sie
nicht sicher sind, dass andere Nutzer nicht beeinträchtigt werden,
sollten Sie Aufträge wie #1 (python) oder #4
(Nutzerdefinierter MD-Code) nicht ausführen. Wenn Sie unsicher sind,
fragen Sie Ihren freundlichen Systemadministrator um Rat.
Wenn Sie Leistungsprobleme mit einem Anmeldeknoten haben, sollten Sie dies dem Systempersonal melden (normalerweise über den Helpdesk), damit sie es untersuchen können.
Test vor der Skalierung
Denken Sie daran, dass die Nutzung von gemeinsam genutzten Systemen in der Regel kostenpflichtig ist. Ein einfacher Fehler in einem Jobskript kann am Ende einen großen Teil des Ressourcenbudgets verschlingen. Stellen Sie sich vor, ein Jobskript mit einem Fehler, der dazu führt, dass es 24 Stunden lang auf 1000 Kernen nichts tut, oder eines, bei dem Sie versehentlich 2000 Kerne angefordert haben und nur 100 davon nutzen! Dieses Problem kann sich noch verschärfen, wenn Skripte geschrieben werden, die die Auftragsübermittlung automatisieren (z. B. wenn dieselbe Berechnung oder Analyse mit vielen verschiedenen Parametern oder Dateien ausgeführt wird). Dies schadet sowohl Ihnen (da Sie viele gebührenpflichtige Ressourcen verschwenden) als auch anderen Nutzern (denen der Zugriff auf die ungenutzten Rechenknoten verwehrt wird). Bei stark ausgelasteten Ressourcen kann es vorkommen, dass Sie tagelang in einer Warteschlange warten, bis Ihr Auftrag innerhalb von 10 Sekunden nach dem Start wegen eines trivialen Tippfehlers im Auftragsskript fehlschlägt. Das ist extrem frustrierend!
Die meisten Systeme bieten spezielle Ressourcen zum Testen an, die kurze Wartezeiten haben, damit Sie dieses Problem vermeiden können.
Testen Sie Skripte für die Übermittlung von Aufträgen, die große Mengen an Ressourcen verwenden
Bevor Sie eine große Anzahl von Aufträgen übermitteln, sollten Sie zunächst einen Testlauf durchführen, um sicherzustellen, dass alles wie erwartet funktioniert.
Bevor Sie einen sehr großen oder sehr langen Auftrag übermitteln, führen Sie einen kurzen, verkürzten Test durch, um sicherzustellen, dass der Auftrag wie erwartet startet.
Have a Backup Plan
Obwohl viele HPC-Systeme Backups aufbewahren, decken diese nicht immer alle verfügbaren Dateisysteme ab und sind möglicherweise nur für Disaster Recovery-Zwecke gedacht (d.h. für die Wiederherstellung des gesamten Dateisystems im Falle eines Verlustes und nicht für eine einzelne Datei oder ein Verzeichnis, das Sie versehentlich gelöscht haben). Der Schutz kritischer Daten vor Beschädigung oder Löschung liegt in erster Linie in Ihrer Verantwortung: Erstellen Sie eigene Sicherungskopien.
Versionskontrollsysteme (wie Git) haben oft kostenlose, Cloud-basierte Angebote (z. B. GitHub und GitLab), die im Allgemeinen zum Speichern von Quellcode verwendet werden. Auch wenn Sie keine eigenen Programme schreiben, können diese sehr nützlich sein, um Jobskripte, Analyseskripte und kleine Eingabedateien zu speichern.
Wenn Sie Software erstellen, haben Sie möglicherweise eine große Menge an Quellcode, den Sie kompilieren, um Ihre ausführbare Datei zu erstellen. Da diese Daten im Allgemeinen durch erneutes Herunterladen des Codes oder durch erneutes Auschecken aus dem Quellcode-Repository wiederhergestellt werden können, sind diese Daten auch weniger kritisch zu schützen.
Bei größeren Datenmengen, insbesondere bei wichtigen Ergebnissen
Ihrer Läufe, die möglicherweise unersetzlich sind, sollten Sie
sicherstellen, dass Sie über ein robustes System verfügen, mit dem Sie
Kopien der Daten vom HPC-System nach Möglichkeit auf einen gesicherten
Speicherplatz übertragen. Werkzeuge wie rsync können dabei
sehr nützlich sein.
Ihr Zugriff auf das gemeinsam genutzte HPC-System ist in der Regel zeitlich begrenzt, daher sollten Sie sicherstellen, dass Sie einen Plan für die Übertragung Ihrer Daten vom System haben, bevor Ihr Zugriff endet. Die Zeit, die für die Übertragung großer Datenmengen benötigt wird, sollte nicht unterschätzt werden, und Sie sollten sicherstellen, dass Sie dies früh genug geplant haben (idealerweise, bevor Sie das System überhaupt für Ihre Forschung nutzen).
In all diesen Fällen sollte der Helpdesk des von Ihnen verwendeten Systems in der Lage sein, Ihnen nützliche Hinweise zu den Möglichkeiten der Datenübertragung für die von Ihnen verwendeten Datenmengen zu geben.
Ihre Daten sind Ihre Verantwortung
Vergewissern Sie sich, dass Sie die Sicherungsrichtlinien für die Dateisysteme auf dem von Ihnen verwendeten System kennen und wissen, welche Auswirkungen dies auf Ihre Arbeit hat, wenn Sie Ihre Daten auf dem System verlieren. Planen Sie die Sicherung kritischer Daten und die Art und Weise, wie Sie die Daten während des Projekts aus dem System transferieren werden.
Übertragen von Daten
Wie bereits erwähnt, stehen viele Nutzer irgendwann vor der Herausforderung, große Datenmengen von HPC-Systemen zu übertragen (dies geschieht häufiger bei der Übertragung von Daten von als auf Systeme, aber die folgenden Ratschläge gelten in beiden Fällen). Die Geschwindigkeit der Datenübertragung kann durch viele verschiedene Faktoren begrenzt werden, so dass der am besten geeignete Datenübertragungsmechanismus von der Art der zu übertragenden Daten und dem Zielort der Daten abhängt.
Die Komponenten zwischen der Quelle und dem Ziel Ihrer Daten haben unterschiedliche Leistungsniveaus und können insbesondere unterschiedliche Fähigkeiten in Bezug auf Bandbreite und Latenz haben.
Bandbreite ist im Allgemeinen die Rohdatenmenge pro Zeiteinheit, die ein Gerät senden oder empfangen kann. Es ist eine übliche und allgemein gut verstandene Metrik.
Latenz ist ein wenig subtiler. Bei Datenübertragungen kann man sie sich als die Zeit vorstellen, die benötigt wird, um Daten aus dem Speicher in eine übertragbare Form zu bringen. Latenzprobleme sind der Grund dafür, dass es ratsam ist, Datenübertragungen durch das Verschieben einer kleinen Anzahl großer Dateien durchzuführen und nicht umgekehrt.
Einige der Schlüsselkomponenten und die damit verbundenen Probleme sind:
- Festplattengeschwindigkeit: Dateisysteme auf HPC-Systemen sind oft hochgradig parallel und bestehen aus einer sehr großen Anzahl von Hochleistungslaufwerken. Dadurch können sie eine sehr hohe Datenbandbreite unterstützen. Wenn das entfernte System nicht über ein ähnlich paralleles Dateisystem verfügt, kann die Übertragungsgeschwindigkeit durch die dortige Festplattenleistung begrenzt sein.
- Metadaten-Leistung: Metadaten-Operationen wie das Öffnen und Schließen von Dateien oder das Auflisten des Besitzers oder der Größe einer Datei sind viel weniger parallel als Lese-/Schreiboperationen. Wenn Ihre Daten aus einer sehr großen Anzahl kleiner Dateien bestehen, kann es sein, dass Ihre Übertragungsgeschwindigkeit durch Metadatenoperationen begrenzt wird. Metadaten-Operationen, die von anderen Nutzern des Systems durchgeführt werden, können auch stark mit den von Ihnen durchgeführten Operationen interagieren, so dass eine Verringerung der Anzahl solcher Operationen (durch Zusammenfassen mehrerer Dateien zu einer einzigen Datei) die Variabilität Ihrer Übertragungsraten verringern und die Übertragungsgeschwindigkeit erhöhen kann.
- Netzwerkgeschwindigkeit: Die Leistung der Datenübertragung kann durch die Netzwerkgeschwindigkeit begrenzt werden. Noch wichtiger ist, dass sie durch den langsamsten Abschnitt des Netzwerks zwischen Quelle und Ziel begrenzt wird. Wenn Sie die Daten auf Ihren Laptop/Arbeitsplatz übertragen, ist dies wahrscheinlich seine Verbindung (entweder über LAN oder WiFi).
- Firewall-Geschwindigkeit: Die meisten modernen Netzwerke sind durch eine Art Firewall geschützt, die bösartigen Datenverkehr herausfiltert. Diese Filterung ist mit einem gewissen Overhead verbunden und kann zu einer Verringerung der Datenübertragungsleistung führen. Die Anforderungen eines Allzwecknetzes, das E-Mail-/Web-Server und Desktop-Rechner beherbergt, unterscheiden sich deutlich von denen eines Forschungsnetzes, das große Datenmengen übertragen muss. Wenn Sie versuchen, Daten zu oder von einem Host in einem Netzwerk für allgemeine Zwecke zu übertragen, werden Sie feststellen, dass die Firewall dieses Netzwerks die erreichbare Übertragungsrate begrenzt.
Wie bereits erwähnt, wird bei zusammenhängenden Daten, die aus einer
großen Anzahl kleiner Dateien bestehen, dringend empfohlen, die Dateien
zur langfristigen Speicherung und Übertragung in eine größere
Archiv-Datei zu packen. Eine einzelne große Datei nutzt das
Dateisystem effizienter und ist einfacher zu verschieben, zu kopieren
und zu übertragen, da deutlich weniger Metadatenoperationen erforderlich
sind. Archivdateien können mit Werkzeugen wie tar und
zip erstellt werden. Wir haben tar bereits
kennengelernt, als wir früher über die Datenübertragung gesprochen
haben.

Überlegen Sie, wie Sie die Daten am besten übertragen
Wenn Sie große Datenmengen übertragen, müssen Sie sich Gedanken darüber machen, was Ihre Übertragungsleistung beeinträchtigen könnte. Es ist immer sinnvoll, einige Tests durchzuführen, anhand derer Sie hochrechnen können, wie lange die Übertragung Ihrer Daten dauern wird.
Angenommen, Sie haben einen Ordner “data”, der etwa 10.000 Dateien enthält, eine gesunde Mischung aus kleinen und großen ASCII- und Binärdaten. Welche der folgenden Möglichkeiten wäre die beste, um sie nach HPC Carpentry’s Cloud Cluster zu übertragen?
scp -r data yourUsername@cluster.hpc-carpentry.org:~/rsync -ra data yourUsername@cluster.hpc-carpentry.org:~/rsync -raz data yourUsername@cluster.hpc-carpentry.org:~/-
tar -cvf data.tar data;rsync -raz data.tar yourUsername@cluster.hpc-carpentry.org:~/ -
tar -cvzf data.tar.gz data;rsync -ra data.tar.gz yourUsername@cluster.hpc-carpentry.org:~/
-
scpwird das Verzeichnis rekursiv kopieren. Dies funktioniert, aber ohne Kompression. -
rsync -rafunktioniert wiescp -r, behält aber Dateiinformationen wie Erstellungszeiten bei. Dies ist geringfügig besser. -
rsync -razfügt eine Komprimierung hinzu, die etwas Bandbreite spart. Wenn Sie eine starke CPU an beiden Enden der Leitung haben und sich in einem langsamen Netzwerk befinden, ist dies eine gute Wahl. - Dieser Befehl verwendet zunächst
tar, um alles in einer einzigen Datei zusammenzufassen, und dannrsync -z, um es mit Kompression zu übertragen. Bei einer so großen Anzahl von Dateien kann der Overhead an Metadaten die Übertragung behindern, daher ist dies eine gute Idee. - Dieser Befehl verwendet
tar -z, um das Archiv zu komprimieren, und dannrsync, um es zu übertragen. Dies kann ähnlich funktionieren wie #4, aber in den meisten Fällen (bei großen Datenmengen) ist es die beste Kombination aus hohem Durchsatz und niedriger Latenz (um das Beste aus Ihrer Zeit und Ihrer Netzwerkverbindung zu machen).
- Seien Sie vorsichtig, wie Sie den Login-Knoten verwenden.
- Für Ihre Daten auf dem System sind Sie selbst verantwortlich.
- Planen und Testen großer Datenübertragungen.
- Es ist oft am besten, viele Dateien vor der Übertragung in eine einzige Archivdatei zu konvertieren.