Lavorare su un sistema HPC remoto
Ultimo aggiornamento il 2026-02-26 | Modifica questa pagina
Panoramica
Domande
- “Che cos’è un sistema HPC?”
- “Come funziona un sistema HPC?”
- “Come si accede a un sistema HPC remoto?”
Obiettivi
- “Connettersi a un sistema HPC remoto”
- “Comprendere l’architettura generale del sistema HPC”
Cos’è un sistema HPC?
Le parole “cloud”, “cluster” e l’espressione “calcolo ad alte prestazioni” o “HPC” sono molto usate in contesti diversi e con vari significati correlati. Che cosa significano? E soprattutto, come li usiamo nel nostro lavoro?
Il cloud è un termine generico comunemente usato per riferirsi a risorse informatiche che sono a) fornite agli utenti su richiesta o in base alle necessità e b) rappresentano risorse reali o virtuali che possono essere situate ovunque sulla Terra. Ad esempio, una grande azienda con risorse informatiche in Brasile, Zimbabwe e Giappone può gestire tali risorse come un proprio cloud interno e la stessa azienda può anche utilizzare risorse cloud commerciali fornite da Amazon o Google. Le risorse cloud possono riferirsi a macchine che eseguono compiti relativamente semplici come servire siti web, fornire storage condiviso, fornire servizi web (come e-mail o piattaforme di social media), così come compiti più tradizionali ad alta intensità di calcolo come l’esecuzione di una simulazione.
Il termine sistema HPC, invece, descrive una risorsa indipendente per carichi di lavoro ad alta intensità di calcolo. In genere sono costituiti da una moltitudine di elementi integrati di elaborazione e archiviazione, progettati per gestire elevati volumi di dati e/o un gran numero di operazioni in virgola mobile (FLOPS) con le massime prestazioni possibili. Ad esempio, tutte le macchine presenti nell’elenco Top-500 sono sistemi HPC. Per supportare questi vincoli, una risorsa HPC deve esistere in una posizione specifica e fissa: i cavi di rete possono estendersi solo fino a un certo punto e i segnali elettrici e ottici possono viaggiare solo a una certa velocità.
La parola “cluster” è spesso usata per risorse HPC di scala piccola o moderata, meno impressionanti della Top-500. I cluster sono spesso gestiti in centri di calcolo che supportano diversi sistemi di questo tipo, tutti accomunati dalla condivisione di reti e storage per supportare attività comuni ad alta intensità di calcolo.
Registrazione
Il primo passo per utilizzare un cluster è stabilire una connessione dal nostro portatile al cluster. Quando siamo seduti al computer (o in piedi, o tenendolo in mano o al polso), ci aspettiamo una visualizzazione con icone, widget e forse alcune finestre o applicazioni: un’interfaccia grafica utente, o GUI. Poiché i cluster di computer sono risorse remote a cui ci colleghiamo tramite interfacce spesso lente o laggose (soprattutto WiFi e VPN), è più pratico utilizzare un’interfaccia a riga di comando (CLI), in cui i comandi e i risultati sono trasmessi solo tramite testo. Tutto ciò che non è testo (ad esempio le immagini) deve essere scritto su disco e aperto con un programma separato.
Se avete mai aperto il Prompt dei comandi di Windows o il Terminale di macOS, avete visto una CLI. Se avete già seguito i corsi di The Carpentries sulla shell UNIX o su git, avete usato la CLI sulla vostra macchina locale in modo piuttosto esteso. L’unico salto da fare in questo caso è aprire una CLI su una macchina remota, prendendo alcune precauzioni in modo che gli altri utenti della rete non possano vedere (o modificare) i comandi che state eseguendo o i risultati che la macchina remota invia. Utilizzeremo il protocollo Secure SHell (o SSH) per aprire una connessione di rete crittografata tra due macchine, consentendo di inviare e ricevere testo e dati senza doversi preoccupare di occhi indiscreti.

Assicurarsi di avere un client SSH installato sul portatile. Fare
riferimento alla sezione setup per maggiori
dettagli. I client SSH sono solitamente strumenti a riga di comando, in
cui si fornisce l’indirizzo della macchina remota come unico argomento
richiesto. Se il nome utente sul sistema remoto è diverso da quello
utilizzato localmente, è necessario fornire anche quello. Se il vostro
client SSH ha un front-end grafico, come PuTTY o MobaXterm, dovrete
impostare questi argomenti prima di fare clic su “connect” Dal
terminale, si scriverà qualcosa come ssh userName@hostname,
dove il simbolo “@” è usato per separare le due parti di un singolo
argomento.
Aprite il vostro terminale o il vostro client grafico SSH, quindi accedete al cluster usando il vostro nome utente e il computer remoto che potete raggiungere dal mondo esterno, cluster.hpc-carpentry.org.
Ricordarsi di sostituire yourUsername con il proprio
nome utente o con quello fornito dagli istruttori. Potrebbe essere
richiesta la password. Attenzione: i caratteri digitati dopo la
richiesta della password non vengono visualizzati sullo schermo.
L’output normale riprenderà quando si premerà Enter.
Dove siamo?
Molto spesso, molti utenti sono tentati di pensare a un’installazione
di calcolo ad alte prestazioni come a una gigantesca macchina magica. A
volte si pensa che il computer a cui si è acceduto sia l’intero cluster
di calcolo. Ma cosa sta succedendo davvero? A quale computer ci siamo
collegati? Il nome del computer correntemente collegato può essere
controllato con il comando hostname. (Si può anche notare
che il nome dell’host corrente fa parte del nostro prompt)
OUTPUT
login1Cosa c’è nella vostra directory principale?
Gli amministratori del sistema potrebbero aver configurato la vostra
cartella home con alcuni file, cartelle e collegamenti (scorciatoie)
utili allo spazio riservato a voi su altri filesystem. Date un’occhiata
in giro e vedete cosa riuscite a trovare. Suggerimento: I
comandi di shell pwd e ls possono essere
utili. Il contenuto della home directory varia da utente a utente.
Discutete con i vostri vicini le eventuali differenze riscontrate.
Il livello più profondo dovrebbe essere diverso:
yourUsername è unicamente vostro. Ci sono differenze nel
percorso ai livelli superiori?
se entrambi avete delle cartelle vuote, appariranno identiche. Se voi o il vostro vicino avete già usato il sistema, potrebbero esserci delle differenze. Su cosa state lavorando?
Usare pwd per stampare il percorso della
d**irettoria di lavoro:
è possibile eseguire ls per verificare il contenuto
della cartella, anche se è possibile che non venga visualizzato nulla
(se non sono stati forniti file). Per sicurezza, usare il flag
-a per mostrare anche i file nascosti.
come minimo, mostrerà la cartella corrente come . e la
cartella precedente come ...
Nodi
I singoli computer che compongono un cluster sono in genere chiamati nodi (anche se si sente parlare anche di server, computer e macchine). In un cluster, ci sono diversi tipi di nodi per diversi tipi di attività. Il nodo in cui ci si trova in questo momento è chiamato nodo principale, nodo di accesso, pista di atterraggio o nodo di invio. Un nodo di accesso serve come punto di accesso al cluster.
Come gateway, è adatto per caricare e scaricare file, configurare software ed eseguire test rapidi. In generale, il nodo di accesso non dovrebbe essere usato per attività che richiedono molto tempo o risorse. È necessario prestare attenzione a questo aspetto e verificare con i gestori del sito o con la documentazione i dettagli di ciò che è consentito o meno. In queste lezioni, eviteremo di eseguire lavori sul nodo principale.
Nodi di trasferimento dedicati
Se si desidera trasferire grandi quantità di dati da o verso il cluster, alcuni sistemi offrono nodi dedicati solo al trasferimento dei dati. La motivazione risiede nel fatto che i trasferimenti di dati più grandi non devono ostacolare il funzionamento del nodo di login per nessun altro. Verificate con la documentazione del vostro cluster o con il team di supporto se è disponibile un nodo di trasferimento di questo tipo. Come regola generale, si considerano grandi tutti i trasferimenti di un volume superiore a 500 MB e 1 GB. Ma questi numeri cambiano, ad esempio, a seconda della connessione di rete propria e del cluster o di altri fattori.
Il vero lavoro in un cluster viene svolto dai nodi di lavoro (o di calcolo*). I nodi worker sono di varie forme e dimensioni, ma in genere sono dedicati a compiti lunghi o difficili che richiedono molte risorse di calcolo.
Tutte le interazioni con i nodi worker sono gestite da un software specializzato chiamato scheduler (lo scheduler usato in questa lezione si chiama Slurm). In seguito impareremo a usare lo scheduler per inviare i lavori, ma per il momento è in grado di fornire ulteriori informazioni sui nodi worker.
Per esempio, possiamo visualizzare tutti i nodi worker eseguendo il
comando sinfo.
OUTPUT
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
cpubase_bycore_b1* up infinite 4 idle node[1-2],smnode[1-2]
node up infinite 2 idle node[1-2]
smnode up infinite 2 idle smnode[1-2]Ci sono anche macchine specializzate utilizzate per gestire lo storage del disco, l’autenticazione degli utenti e altri compiti legati all’infrastruttura. Sebbene in genere non ci si colleghi o si interagisca direttamente con queste macchine, esse consentono di svolgere una serie di funzioni chiave, come garantire che il nostro account utente e i nostri file siano disponibili in tutto il sistema HPC.
Cosa c’è in un nodo?
Tutti i nodi di un sistema HPC hanno gli stessi componenti del vostro laptop o desktop: CPU (talvolta chiamate anche processori o core), memoria (o RAM) e spazio su disco. Le CPU sono lo strumento del computer per eseguire programmi e calcoli. Le informazioni su un’attività corrente sono memorizzate nella memoria del computer. Il disco si riferisce a tutta la memoria a cui si può accedere come un file system. In genere si tratta di uno spazio di archiviazione che può contenere dati in modo permanente, vale a dire che i dati sono ancora presenti anche se il computer è stato riavviato. Anche se questa memoria può essere locale (un disco rigido installato al suo interno), è più comune che i nodi si colleghino a un fileserver condiviso e remoto o a un cluster di server.
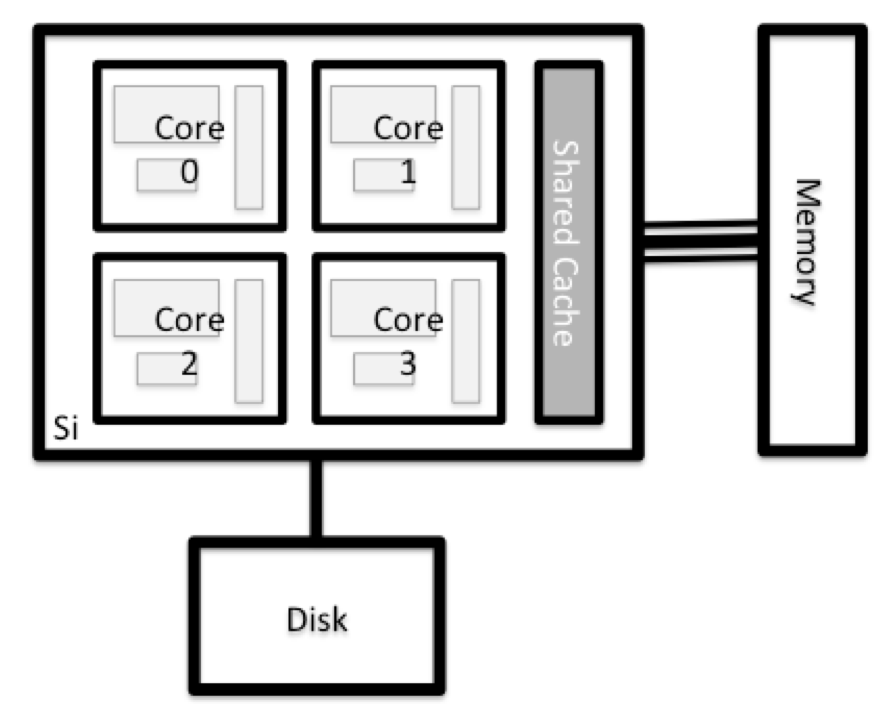
Esplora il tuo computer
Ci sono diversi modi per farlo. La maggior parte dei sistemi operativi ha un monitor grafico di sistema, come il Task Manager di Windows. A volte è possibile trovare informazioni più dettagliate alla riga di comando. Ad esempio, alcuni dei comandi utilizzati su un sistema Linux sono:
Esecuzione delle utilità di sistema
Leggere da /proc
Utilizzare un monitor di sistema
Esplora il nodo di login
Ora confrontate le risorse del vostro computer con quelle del nodo principale.
BASH
[you@laptop:~]$ ssh yourUsername@cluster.hpc-carpentry.org
[yourUsername@login1 ~] nproc --all
[yourUsername@login1 ~] free -mÈ possibile ottenere maggiori informazioni sui processori utilizzando
lscpu, e molti dettagli sulla memoria leggendo il file
/proc/meminfo:
È anche possibile esplorare i filesystem disponibili usando
df per mostrare lo spazio disk
free. Il flag -h rende le dimensioni in un
formato facile da usare, cioè GB invece di B. Il flag
type -T mostra che tipo di filesystem è
ogni risorsa.
I filesystem locali (ext, tmp, xfs, zfs) dipendono dal fatto che ci si trovi sullo stesso nodo di accesso (o nodo di calcolo, più avanti). I filesystem in rete (beegfs, cifs, gpfs, nfs, pvfs) saranno simili — ma potrebbero includere yourUsername, a seconda di come viene [montato] (https://en.wikipedia.org/wiki/Mount_(computing)).
Filesystem condivisi
Questo è un punto importante da ricordare: i file salvati su un nodo (computer) sono spesso disponibili ovunque nel cluster!
Confronta il computer, il nodo di accesso e il nodo di calcolo
Confrontate il numero di processori e di memoria del vostro portatile con i numeri che vedete sul nodo principale del cluster e sul nodo worker. Discutete le differenze con il vostro vicino.
Quali implicazioni pensi che possano avere le differenze nell’esecuzione del tuo lavoro di ricerca sui diversi sistemi e nodi?
Differenze tra i nodi
Molti cluster HPC hanno una varietà di nodi ottimizzati per particolari carichi di lavoro. Alcuni nodi possono disporre di una maggiore quantità di memoria o di risorse specializzate come le unità di elaborazione grafica (GPU).
Con tutto questo in mente, ora vedremo come parlare con lo scheduler del cluster e usarlo per iniziare a eseguire i nostri script e programmi!
- “Un sistema HPC è un insieme di macchine collegate in rete”
- “I sistemi HPC forniscono tipicamente nodi di accesso e una serie di nodi lavoratori.”
- “Le risorse presenti sui nodi indipendenti (lavoratori) possono variare in volume e tipo (quantità di RAM, architettura del processore, disponibilità di filesystem montati in rete, ecc.)
- “I file salvati su un nodo sono disponibili su tutti i nodi.”