Content from Perché usare un cluster?
Ultimo aggiornamento il 2026-02-26 | Modifica questa pagina
Panoramica
Domande
- Perché dovrei essere interessato al calcolo ad alte prestazioni (HPC)?
- Cosa posso aspettarmi di imparare da questo corso?
Obiettivi
- Descrivere che cos’è un sistema HPC
- Identificare i vantaggi di un sistema HPC.
Spesso i problemi di ricerca che utilizzano l’informatica possono superare le capacità del computer desktop o portatile da cui sono partiti:
- Uno studente di statistica vuole effettuare una convalida incrociata di un modello. Ciò comporta l’esecuzione del modello 1000 volte, ma ogni esecuzione richiede un’ora. L’esecuzione del modello su un computer portatile richiede più di un mese! In questo problema di ricerca, i risultati finali vengono calcolati dopo l’esecuzione di tutti i 1000 modelli, ma in genere viene eseguito solo un modello alla volta (in serie) sul portatile. Poiché ognuna delle 1000 esecuzioni è indipendente da tutte le altre, e con un numero sufficiente di computer, è teoricamente possibile eseguirle tutte insieme (in parallelo).
- Un ricercatore di genomica ha utilizzato piccoli insiemi di dati di sequenza, ma presto riceverà un nuovo tipo di dati di sequenziamento 10 volte più grandi. Aprire i set di dati su un computer è già impegnativo, analizzare questi set di dati più grandi probabilmente lo manderà in tilt. In questo problema di ricerca, i calcoli richiesti potrebbero essere impossibili da parallelizzare, ma sarebbe necessario un computer con più memoria per analizzare i futuri set di dati molto più grandi.
- Un ingegnere sta usando un pacchetto di fluidodinamica che ha un’opzione per l’esecuzione in parallelo. Finora questa opzione non è stata utilizzata su un desktop. Passando dalle simulazioni 2D a quelle 3D, il tempo di simulazione è più che triplicato. Potrebbe essere utile sfruttare questa opzione o funzione. In questo problema di ricerca, i calcoli in ogni regione della simulazione sono ampiamente indipendenti dai calcoli in altre regioni della simulazione. È possibile eseguire i calcoli di ogni regione simultaneamente (in parallelo), comunicare i risultati selezionati alle regioni adiacenti, se necessario, e ripetere i calcoli per convergere su un insieme finale di risultati. Passando da un modello 2D a uno 3D, la quantità di dati e di calcoli aumenta notevolmente, ed è teoricamente possibile distribuire i calcoli su più computer che comunicano su una rete condivisa.
In tutti questi casi, è necessario l’accesso a più computer. Questi computer dovrebbero essere utilizzabili contemporaneamente, risolvendo in parallelo i problemi di molti ricercatori.
Presentazione del gergo
Aprire HPC Jargon Buster in una
nuova scheda. Per presentare il contenuto, premere C per
aprire una clone in una finestra separata, quindi
premere P per attivare la modalità di
presentazione.
Avete mai usato un server?
Prendete un minuto e pensate a quali delle vostre interazioni quotidiane con un computer potrebbero richiedere un server remoto o addirittura un cluster per fornirvi i risultati.
- Controllo della posta elettronica: il vostro computer (magari in tasca) contatta una macchina remota, si autentica e scarica un elenco di nuovi messaggi; carica anche le modifiche allo stato dei messaggi, come ad esempio se sono stati letti, contrassegnati come spazzatura o cancellati. Poiché il vostro non è l’unico account, il server di posta è probabilmente uno dei tanti in un centro dati.
- La ricerca di una frase online comporta il confronto del termine di ricerca con un enorme database di tutti i siti conosciuti, alla ricerca di corrispondenze. Questa operazione di “interrogazione” può essere semplice, ma la costruzione del database è un compito monumentale! I server sono coinvolti in ogni fase.
- La ricerca di indicazioni stradali su un sito web di mappatura comporta il collegamento dei punti (A) di partenza e (B) di arrivo attraversando un grafo alla ricerca del percorso “più breve” in base alla distanza, al tempo, alla spesa o a un’altra metrica. Convertire una mappa nella forma corretta è relativamente semplice, ma calcolare tutti i possibili percorsi tra A e B è costoso.
Il controllo della posta elettronica potrebbe essere seriale: la macchina si connette a un server e scambia dati. Anche la ricerca, interrogando il database per il termine di ricerca (o gli endpoint), potrebbe essere seriale, in quanto una macchina riceve l’interrogazione e restituisce il risultato. Tuttavia, l’assemblaggio e la memorizzazione dell’intero database vanno ben oltre le capacità di una sola macchina. Pertanto, queste funzioni vengono svolte in parallelo da una vasta collezione di server “hyperscale” che lavorano insieme.
- Il calcolo ad alte prestazioni (HPC) comporta tipicamente la connessione a sistemi di calcolo molto grandi in altre parti del mondo.
- Questi altri sistemi possono essere utilizzati per eseguire lavori che sarebbero impossibili o molto più lenti su sistemi più piccoli.
- Le risorse HPC sono condivise da più utenti.
- Il metodo standard di interazione con questi sistemi è tramite un’interfaccia a riga di comando.
Content from Connessione a un sistema HPC remoto
Ultimo aggiornamento il 2026-02-26 | Modifica questa pagina
Panoramica
Domande
- Come si accede a un sistema HPC remoto?
Obiettivi
- Configurare l’accesso sicuro a un sistema HPC remoto.
- Connessione a un sistema HPC remoto.
Connessioni sicure
Il primo passo per utilizzare un cluster è stabilire una connessione dal nostro portatile al cluster. Quando siamo seduti davanti a un computer (o in piedi, o tenendolo in mano o al polso), ci aspettiamo una visualizzazione con icone, widget e forse alcune finestre o applicazioni: una interfaccia utente grafica, o GUI. Poiché i cluster di computer sono risorse remote a cui ci si connette tramite interfacce lente o intermittenti (soprattutto WiFi e VPN), è più pratico utilizzare una interfaccia a riga di comando, o CLI, per inviare comandi in testo semplice. Se un comando restituisce un output, anche questo viene stampato come testo normale. I comandi che eseguiamo oggi non apriranno una finestra per mostrare i risultati grafici.
Se avete mai aperto il Prompt dei comandi di Windows o il Terminale di macOS, avete visto una CLI. Se avete già seguito i corsi di The Carpentries sulla shell UNIX o sul controllo di versione, avete usato ampiamente la CLI sulla vostra macchina locale. L’unico salto da fare in questo caso è aprire una CLI su una macchina remota, prendendo alcune precauzioni in modo che gli altri utenti della rete non possano vedere (o modificare) i comandi che state eseguendo o i risultati che la macchina remota invia. Utilizzeremo il protocollo Secure SHell (o SSH) per aprire una connessione di rete crittografata tra due macchine, consentendovi di inviare e ricevere testo e dati senza dovervi preoccupare di occhi indiscreti.

I client SSH sono solitamente strumenti a riga di comando, in cui si
fornisce l’indirizzo della macchina remota come unico argomento
richiesto. Se il nome utente sul sistema remoto è diverso da quello
utilizzato localmente, è necessario fornire anche quello. Se il vostro
client SSH ha un front-end grafico, come PuTTY o MobaXterm, dovrete
impostare questi argomenti prima di fare clic su “connect” Dal
terminale, si scriverà qualcosa come ssh userName@hostname,
dove l’argomento è proprio come un indirizzo e-mail: il simbolo “@” è
usato per separare l’ID personale dall’indirizzo della macchina
remota.
Quando si accede a un computer portatile, a un tablet o a un altro dispositivo personale, di solito sono necessari un nome utente, una password o un modello per impedire l’accesso non autorizzato. In queste situazioni, la probabilità che qualcun altro intercetti la password è bassa, poiché la registrazione dei tasti premuti richiede un exploit dannoso o un accesso fisico. Per i sistemi come login1’ che eseguono un server SSH, chiunque sulla rete può accedere, o tentare di farlo. Poiché i nomi utente sono spesso pubblici o facili da indovinare, la password è spesso l’anello più debole della catena di sicurezza. Per questo motivo, molti cluster vietano il login basato su password, richiedendo invece di generare e configurare una coppia di chiavi pubbliche e private con una password molto più forte. Anche se il vostro cluster non lo richiede, la prossima sezione vi guiderà nell’uso delle chiavi SSH e di un agente SSH per rafforzare la vostra sicurezza e rendere più conveniente l’accesso ai sistemi remoti.
Migliore sicurezza con le chiavi SSH
Il Lesson Setup fornisce le istruzioni per installare un’applicazione shell con SSH. Se non l’avete già fatto, aprite l’applicazione di shell con un’interfaccia a riga di comando di tipo Unix sul vostro sistema.
Le chiavi SSH sono un metodo alternativo di autenticazione per ottenere l’accesso a sistemi informatici remoti. Possono anche essere usate per l’autenticazione durante il trasferimento di file o per accedere a sistemi di controllo di versione remoti (come GitHub). In questa sezione verrà creata una coppia di chiavi SSH:
- una chiave privata che si conserva sul proprio computer e
- una chiave pubblica che può essere inserita in qualsiasi sistema remoto a cui si accede.
Le chiavi private sono il vostro passaporto digitale sicuro
Una chiave privata visibile a chiunque tranne che a voi deve essere considerata compromessa e deve essere distrutta. Questo include avere permessi impropri sulla directory in cui è memorizzata (o una sua copia), attraversare una rete non sicura (crittografata), allegare e-mail non crittografate e persino visualizzare la chiave nella finestra del terminale.
Proteggete questa chiave come se vi aprisse la porta di casa. Per molti versi, è così.
Indipendentemente dal software o dal sistema operativo utilizzato, vi preghiamo di scegliere una password o una passphrase forte che funga da ulteriore livello di protezione per la chiave SSH privata.
Considerazioni sulle password delle chiavi SSH
Quando viene richiesto, inserire una password forte che si ricordi. Esistono due approcci comuni:
- Creare una passphrase memorabile con punteggiatura e sostituzioni di numeri con lettere, di almeno 32 caratteri. Gli indirizzi stradali funzionano bene; fate attenzione agli attacchi di social engineering o ai registri pubblici.
- Utilizzare un gestore di password e il suo generatore di password integrato con tutte le classi di caratteri, a partire da 25 caratteri. KeePass e BitWarden sono due buone opzioni.
- Nulla è meno sicuro di una chiave privata senza password. Se per sbaglio avete saltato l’inserimento della password, tornate indietro e generate una nuova coppia di chiavi con una password forte.
Chiavi SSH su Linux, Mac, MobaXterm e Windows Sottosistema per Linux
Una volta aperto il terminale, verificare la presenza di chiavi SSH e nomi di file esistenti, poiché le chiavi SSH esistenti vengono sovrascritte.
se ~/.ssh/id_ed25519 esiste già, è necessario
specificare un nome diverso per la nuova coppia di chiavi.
Generare una nuova coppia di chiavi pubbliche e private usando il
seguente comando, che produrrà una chiave più forte di quella
predefinita ssh-keygen invocando questi flag:
-
-a(il valore predefinito è 16): numero di cicli di derivazione della passphrase; aumentare per rallentare gli attacchi brute force. -
-t(l’impostazione predefinita è rsa): specifica il “tipo” o algoritmo crittografico.ed25519specifica EdDSA con una chiave a 256 bit; è più veloce di RSA con una forza comparabile. -
-f(predefinito è /home/user/.ssh/id): nome del file in cui memorizzare la chiave privata. Il nome del file della chiave pubblica sarà identico, con l’aggiunta dell’estensione.pub.
Quando viene richiesto, inserire una password forte tenendo conto delle considerazioni precedenti. Si noti che il terminale non sembra cambiare mentre si digita la password: questo è intenzionale, per la vostra sicurezza. Vi verrà richiesto di digitarla di nuovo, quindi non preoccupatevi troppo degli errori di battitura.
Guardare in ~/.ssh (usare ls ~/.ssh). Si
dovrebbero vedere due nuovi file:
- la vostra chiave privata (
~/.ssh/id_ed25519): *non condividere con nessuno! - la chiave pubblica condivisibile
(
~/.ssh/id_ed25519.pub): se un amministratore di sistema chiede una chiave, questa è quella da inviare. È anche sicura da caricare su siti web come GitHub: è destinata a essere vista.
Usa RSA per i sistemi più vecchi
Se la generazione della chiave non è riuscita perché ed25519 non è disponibile, provare a usare il più vecchio (ma ancora forte e affidabile) crittosistema RSA. Anche in questo caso, verificare prima la presenza di una chiave esistente:
Se ~/.ssh/id_rsa esiste già, è necessario specificare un
nome diverso per la nuova coppia di chiavi. Generarla come sopra, con i
seguenti flag aggiuntivi:
-
-bimposta il numero di bit della chiave. L’impostazione predefinita è 2048. EdDSA utilizza una lunghezza fissa della chiave, quindi questo flag non ha alcun effetto. -
-o(nessun valore predefinito): utilizzare il formato della chiave OpenSSH, anziché PEM.
Quando viene richiesto, inserire una password forte tenendo conto delle considerazioni di cui sopra.
Guardare in ~/.ssh (usare ls ~/.ssh). Si
dovrebbero vedere due nuovi file:
- la vostra chiave privata (
~/.ssh/id_rsa): *non condividere con nessuno! - la chiave pubblica condivisibile (
~/.ssh/id_rsa.pub): se un amministratore di sistema chiede una chiave, questa è quella da inviare. È anche sicura da caricare su siti web come GitHub: è destinata a essere vista.
Chiavi SSH su PuTTY
Se si usa PuTTY su Windows, scaricare e usare puttygen
per generare la coppia di chiavi. Vedere la documentazione
di PuTTY per i dettagli.
Selezionare
EdDSAcome tipo di chiave.Selezionare
255come dimensione o forza della chiave.Fare clic sul pulsante “Genera”.
Non è necessario inserire un commento.
Quando viene richiesto, inserire una password forte tenendo conto delle considerazioni di cui sopra.
Salvare le chiavi in una cartella che non può essere letta da altri utenti del sistema.
Guardare nella cartella specificata. Si dovrebbero vedere due nuovi file:
- la vostra chiave privata (
id_ed25519): *non condividere con nessuno! - la chiave pubblica condivisibile (
id_ed25519.pub): se un amministratore di sistema chiede una chiave, questa è quella da inviare. È anche sicura da caricare su siti web come GitHub: è destinata a essere vista.
Agente SSH per una gestione delle chiavi più semplice
Una chiave SSH è forte quanto la password usata per sbloccarla, ma d’altra parte digitare una password complessa ogni volta che ci si connette a una macchina è noioso e stufa molto velocemente. È qui che entra in gioco l’agente SSH.
Utilizzando un agente SSH, è possibile digitare una volta la password per la chiave privata e fare in modo che l’agente la ricordi per un certo numero di ore o finché non ci si disconnette. A meno che qualche malintenzionato non abbia accesso fisico al vostro computer, questo permette di mantenere la password al sicuro ed elimina la noia di doverla digitare più volte.
Ricordate la password, perché una volta scaduta nell’Agente, dovrete digitarla di nuovo.
Agenti SSH su Linux, macOS e Windows
Aprire l’applicazione terminale e verificare se è in esecuzione un agente:
-
Se si ottiene un errore come questo,
ERRORE
Error connecting to agent: No such file or directory… quindi è necessario lanciare l’agente come segue:
RichiamoCosa c’è in un
$(...)?La sintassi di questo comando dell’agente SSH è insolita, rispetto a quanto visto nella lezione sulla shell UNIX. Questo perché il comando
ssh-agentcrea una connessione a cui solo voi avete accesso e stampa una serie di comandi di shell che possono essere usati per raggiungerla, ma *non li esegue!OUTPUT
SSH_AUTH_SOCK=/tmp/ssh-Zvvga2Y8kQZN/agent.131521; export SSH_AUTH_SOCK; SSH_AGENT_PID=131522; export SSH_AGENT_PID; echo Agent pid 131522;Il comando
evalinterpreta l’output di testo come comandi e consente di accedere alla connessione dell’agente SSH appena creata.Si potrebbe eseguire da soli ogni riga dell’output di
ssh-agente ottenere lo stesso risultato. L’uso dievalrende tutto più semplice. In caso contrario, l’agente è già in esecuzione: non modificarlo.
Aggiungere la propria chiave all’agente, con scadenza della sessione dopo 8 ore:
OUTPUT
Enter passphrase for .ssh/id_ed25519:
Identity added: .ssh/id_ed25519
Lifetime set to 86400 secondsPer tutta la durata (8 ore), ogni volta che userete quella chiave, l’agente SSH fornirà la chiave per vostro conto senza che dobbiate digitare un solo tasto.
Agente SSH su PuTTY
Se si usa PuTTY su Windows, scaricare e usare pageant
come agente SSH. Vedere la documentazione
di PuTTY.
Accedere al cluster
Aprire il terminale o il client grafico SSH, quindi accedere al
cluster. Sostituire yourUsername con il proprio nome utente
o con quello fornito dagli istruttori.
potrebbe essere richiesta la password. Attenzione: i caratteri
digitati dopo la richiesta della password non vengono visualizzati sullo
schermo. L’output normale riprenderà quando si premerà
Enter.
Avrete notato che il prompt è cambiato quando vi siete collegati al
sistema remoto usando il terminale (se vi siete collegati con PuTTY
questo non vale perché non offre un terminale locale). Questo
cambiamento è importante perché può aiutare a distinguere su quale
sistema verranno eseguiti i comandi digitati quando li si passa al
terminale. Questa modifica rappresenta anche una piccola complicazione
che dovremo affrontare nel corso del workshop. L’esatta visualizzazione
del prompt (che convenzionalmente termina con $) nel
terminale quando è collegato al sistema locale e al sistema remoto sarà
in genere diversa per ogni utente. È comunque necessario indicare su
quale sistema si stanno inserendo i comandi, quindi adotteremo la
seguente convenzione:
-
[you@laptop:~]$quando il comando deve essere immesso su un terminale collegato al computer locale -
[yourUsername@login1 ~]quando il comando deve essere immesso su un terminale collegato al sistema remoto -
$quando non ha importanza a quale sistema sia collegato il terminale.
Guardando intorno alla vostra casa remota
Molto spesso, molti utenti sono tentati di pensare a un’installazione
di calcolo ad alte prestazioni come a una gigantesca macchina magica. A
volte si pensa che il computer a cui si accede sia l’intero cluster di
calcolo. Ma cosa sta succedendo davvero? A quale computer ci siamo
collegati? Il nome del computer correntemente collegato può essere
controllato con il comando hostname. (Si può anche notare
che il nome dell’host corrente fa parte del nostro prompt)
OUTPUT
login1Quindi, siamo sicuramente sul computer remoto. Quindi, scopriamo dove
ci troviamo eseguendo pwd per stampare la
cartella di lavoro d.
OUTPUT
/home/yourUsernameOttimo, sappiamo dove siamo! Vediamo cosa c’è nella nostra cartella corrente:
OUTPUT
id_ed25519.pubGli amministratori del sistema potrebbero aver configurato la vostra cartella home con alcuni file, cartelle e collegamenti (scorciatoie) utili allo spazio riservato a voi su altri filesystem. Se non l’hanno fatto, la cartella home potrebbe apparire vuota. Per ricontrollare, includere i file nascosti nell’elenco delle cartelle:
OUTPUT
. .bashrc id_ed25519.pub
.. .sshNella prima colonna, . è un riferimento alla directory
corrente e .. un riferimento alla cartella precedente
(/home). Gli altri file, o file simili, possono essere
visualizzati o meno: .bashrc è un file di configurazione
della shell, che può essere modificato con le proprie preferenze; e
.ssh è una directory che memorizza le chiavi SSH e un
registro delle connessioni autorizzate.
Installare la chiave SSH
Ci può essere un modo migliore
Le politiche e le pratiche per la gestione delle chiavi SSH variano tra i cluster HPC: seguire le indicazioni fornite dagli amministratori del cluster o la documentazione. In particolare, se esiste un portale online per la gestione delle chiavi SSH, utilizzare quello invece delle indicazioni qui riportate.
Se si è trasferita la chiave pubblica SSH con scp, si
dovrebbe vedere id_ed25519.pub nella propria home
directory. Per “installare” questa chiave, deve essere elencata in un
file chiamato authorized_keys sotto la cartella
.ssh.
Se la cartella .ssh non è stata elencata sopra, allora
non esiste ancora: bisogna crearla.
Ora, usare cat per stampare la chiave pubblica, ma
reindirizzare l’output, aggiungendolo al file
authorized_keys:
Tutto qui! Se la chiave e l’agente sono stati configurati correttamente, non dovrebbe essere richiesta la password per la chiave SSH.
- Un sistema HPC è un insieme di macchine collegate in rete.
- I sistemi HPC forniscono in genere nodi di accesso e una serie di nodi worker.
- Le risorse presenti sui nodi indipendenti (worker) possono variare per volume e tipo (quantità di RAM, architettura del processore, disponibilità di filesystem montati in rete, ecc.)
- I file salvati su un nodo sono disponibili su tutti i nodi.
Content from Lavorare su un sistema HPC remoto
Ultimo aggiornamento il 2026-02-26 | Modifica questa pagina
Panoramica
Domande
- “Che cos’è un sistema HPC?”
- “Come funziona un sistema HPC?”
- “Come si accede a un sistema HPC remoto?”
Obiettivi
- “Connettersi a un sistema HPC remoto”
- “Comprendere l’architettura generale del sistema HPC”
Cos’è un sistema HPC?
Le parole “cloud”, “cluster” e l’espressione “calcolo ad alte prestazioni” o “HPC” sono molto usate in contesti diversi e con vari significati correlati. Che cosa significano? E soprattutto, come li usiamo nel nostro lavoro?
Il cloud è un termine generico comunemente usato per riferirsi a risorse informatiche che sono a) fornite agli utenti su richiesta o in base alle necessità e b) rappresentano risorse reali o virtuali che possono essere situate ovunque sulla Terra. Ad esempio, una grande azienda con risorse informatiche in Brasile, Zimbabwe e Giappone può gestire tali risorse come un proprio cloud interno e la stessa azienda può anche utilizzare risorse cloud commerciali fornite da Amazon o Google. Le risorse cloud possono riferirsi a macchine che eseguono compiti relativamente semplici come servire siti web, fornire storage condiviso, fornire servizi web (come e-mail o piattaforme di social media), così come compiti più tradizionali ad alta intensità di calcolo come l’esecuzione di una simulazione.
Il termine sistema HPC, invece, descrive una risorsa indipendente per carichi di lavoro ad alta intensità di calcolo. In genere sono costituiti da una moltitudine di elementi integrati di elaborazione e archiviazione, progettati per gestire elevati volumi di dati e/o un gran numero di operazioni in virgola mobile (FLOPS) con le massime prestazioni possibili. Ad esempio, tutte le macchine presenti nell’elenco Top-500 sono sistemi HPC. Per supportare questi vincoli, una risorsa HPC deve esistere in una posizione specifica e fissa: i cavi di rete possono estendersi solo fino a un certo punto e i segnali elettrici e ottici possono viaggiare solo a una certa velocità.
La parola “cluster” è spesso usata per risorse HPC di scala piccola o moderata, meno impressionanti della Top-500. I cluster sono spesso gestiti in centri di calcolo che supportano diversi sistemi di questo tipo, tutti accomunati dalla condivisione di reti e storage per supportare attività comuni ad alta intensità di calcolo.
Registrazione
Il primo passo per utilizzare un cluster è stabilire una connessione dal nostro portatile al cluster. Quando siamo seduti al computer (o in piedi, o tenendolo in mano o al polso), ci aspettiamo una visualizzazione con icone, widget e forse alcune finestre o applicazioni: un’interfaccia grafica utente, o GUI. Poiché i cluster di computer sono risorse remote a cui ci colleghiamo tramite interfacce spesso lente o laggose (soprattutto WiFi e VPN), è più pratico utilizzare un’interfaccia a riga di comando (CLI), in cui i comandi e i risultati sono trasmessi solo tramite testo. Tutto ciò che non è testo (ad esempio le immagini) deve essere scritto su disco e aperto con un programma separato.
Se avete mai aperto il Prompt dei comandi di Windows o il Terminale di macOS, avete visto una CLI. Se avete già seguito i corsi di The Carpentries sulla shell UNIX o su git, avete usato la CLI sulla vostra macchina locale in modo piuttosto esteso. L’unico salto da fare in questo caso è aprire una CLI su una macchina remota, prendendo alcune precauzioni in modo che gli altri utenti della rete non possano vedere (o modificare) i comandi che state eseguendo o i risultati che la macchina remota invia. Utilizzeremo il protocollo Secure SHell (o SSH) per aprire una connessione di rete crittografata tra due macchine, consentendo di inviare e ricevere testo e dati senza doversi preoccupare di occhi indiscreti.

Assicurarsi di avere un client SSH installato sul portatile. Fare
riferimento alla sezione setup per maggiori
dettagli. I client SSH sono solitamente strumenti a riga di comando, in
cui si fornisce l’indirizzo della macchina remota come unico argomento
richiesto. Se il nome utente sul sistema remoto è diverso da quello
utilizzato localmente, è necessario fornire anche quello. Se il vostro
client SSH ha un front-end grafico, come PuTTY o MobaXterm, dovrete
impostare questi argomenti prima di fare clic su “connect” Dal
terminale, si scriverà qualcosa come ssh userName@hostname,
dove il simbolo “@” è usato per separare le due parti di un singolo
argomento.
Aprite il vostro terminale o il vostro client grafico SSH, quindi accedete al cluster usando il vostro nome utente e il computer remoto che potete raggiungere dal mondo esterno, cluster.hpc-carpentry.org.
Ricordarsi di sostituire yourUsername con il proprio
nome utente o con quello fornito dagli istruttori. Potrebbe essere
richiesta la password. Attenzione: i caratteri digitati dopo la
richiesta della password non vengono visualizzati sullo schermo.
L’output normale riprenderà quando si premerà Enter.
Dove siamo?
Molto spesso, molti utenti sono tentati di pensare a un’installazione
di calcolo ad alte prestazioni come a una gigantesca macchina magica. A
volte si pensa che il computer a cui si è acceduto sia l’intero cluster
di calcolo. Ma cosa sta succedendo davvero? A quale computer ci siamo
collegati? Il nome del computer correntemente collegato può essere
controllato con il comando hostname. (Si può anche notare
che il nome dell’host corrente fa parte del nostro prompt)
OUTPUT
login1Cosa c’è nella vostra directory principale?
Gli amministratori del sistema potrebbero aver configurato la vostra
cartella home con alcuni file, cartelle e collegamenti (scorciatoie)
utili allo spazio riservato a voi su altri filesystem. Date un’occhiata
in giro e vedete cosa riuscite a trovare. Suggerimento: I
comandi di shell pwd e ls possono essere
utili. Il contenuto della home directory varia da utente a utente.
Discutete con i vostri vicini le eventuali differenze riscontrate.
Il livello più profondo dovrebbe essere diverso:
yourUsername è unicamente vostro. Ci sono differenze nel
percorso ai livelli superiori?
se entrambi avete delle cartelle vuote, appariranno identiche. Se voi o il vostro vicino avete già usato il sistema, potrebbero esserci delle differenze. Su cosa state lavorando?
Usare pwd per stampare il percorso della
d**irettoria di lavoro:
è possibile eseguire ls per verificare il contenuto
della cartella, anche se è possibile che non venga visualizzato nulla
(se non sono stati forniti file). Per sicurezza, usare il flag
-a per mostrare anche i file nascosti.
come minimo, mostrerà la cartella corrente come . e la
cartella precedente come ...
Nodi
I singoli computer che compongono un cluster sono in genere chiamati nodi (anche se si sente parlare anche di server, computer e macchine). In un cluster, ci sono diversi tipi di nodi per diversi tipi di attività. Il nodo in cui ci si trova in questo momento è chiamato nodo principale, nodo di accesso, pista di atterraggio o nodo di invio. Un nodo di accesso serve come punto di accesso al cluster.
Come gateway, è adatto per caricare e scaricare file, configurare software ed eseguire test rapidi. In generale, il nodo di accesso non dovrebbe essere usato per attività che richiedono molto tempo o risorse. È necessario prestare attenzione a questo aspetto e verificare con i gestori del sito o con la documentazione i dettagli di ciò che è consentito o meno. In queste lezioni, eviteremo di eseguire lavori sul nodo principale.
Nodi di trasferimento dedicati
Se si desidera trasferire grandi quantità di dati da o verso il cluster, alcuni sistemi offrono nodi dedicati solo al trasferimento dei dati. La motivazione risiede nel fatto che i trasferimenti di dati più grandi non devono ostacolare il funzionamento del nodo di login per nessun altro. Verificate con la documentazione del vostro cluster o con il team di supporto se è disponibile un nodo di trasferimento di questo tipo. Come regola generale, si considerano grandi tutti i trasferimenti di un volume superiore a 500 MB e 1 GB. Ma questi numeri cambiano, ad esempio, a seconda della connessione di rete propria e del cluster o di altri fattori.
Il vero lavoro in un cluster viene svolto dai nodi di lavoro (o di calcolo*). I nodi worker sono di varie forme e dimensioni, ma in genere sono dedicati a compiti lunghi o difficili che richiedono molte risorse di calcolo.
Tutte le interazioni con i nodi worker sono gestite da un software specializzato chiamato scheduler (lo scheduler usato in questa lezione si chiama Slurm). In seguito impareremo a usare lo scheduler per inviare i lavori, ma per il momento è in grado di fornire ulteriori informazioni sui nodi worker.
Per esempio, possiamo visualizzare tutti i nodi worker eseguendo il
comando sinfo.
OUTPUT
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
cpubase_bycore_b1* up infinite 4 idle node[1-2],smnode[1-2]
node up infinite 2 idle node[1-2]
smnode up infinite 2 idle smnode[1-2]Ci sono anche macchine specializzate utilizzate per gestire lo storage del disco, l’autenticazione degli utenti e altri compiti legati all’infrastruttura. Sebbene in genere non ci si colleghi o si interagisca direttamente con queste macchine, esse consentono di svolgere una serie di funzioni chiave, come garantire che il nostro account utente e i nostri file siano disponibili in tutto il sistema HPC.
Cosa c’è in un nodo?
Tutti i nodi di un sistema HPC hanno gli stessi componenti del vostro laptop o desktop: CPU (talvolta chiamate anche processori o core), memoria (o RAM) e spazio su disco. Le CPU sono lo strumento del computer per eseguire programmi e calcoli. Le informazioni su un’attività corrente sono memorizzate nella memoria del computer. Il disco si riferisce a tutta la memoria a cui si può accedere come un file system. In genere si tratta di uno spazio di archiviazione che può contenere dati in modo permanente, vale a dire che i dati sono ancora presenti anche se il computer è stato riavviato. Anche se questa memoria può essere locale (un disco rigido installato al suo interno), è più comune che i nodi si colleghino a un fileserver condiviso e remoto o a un cluster di server.
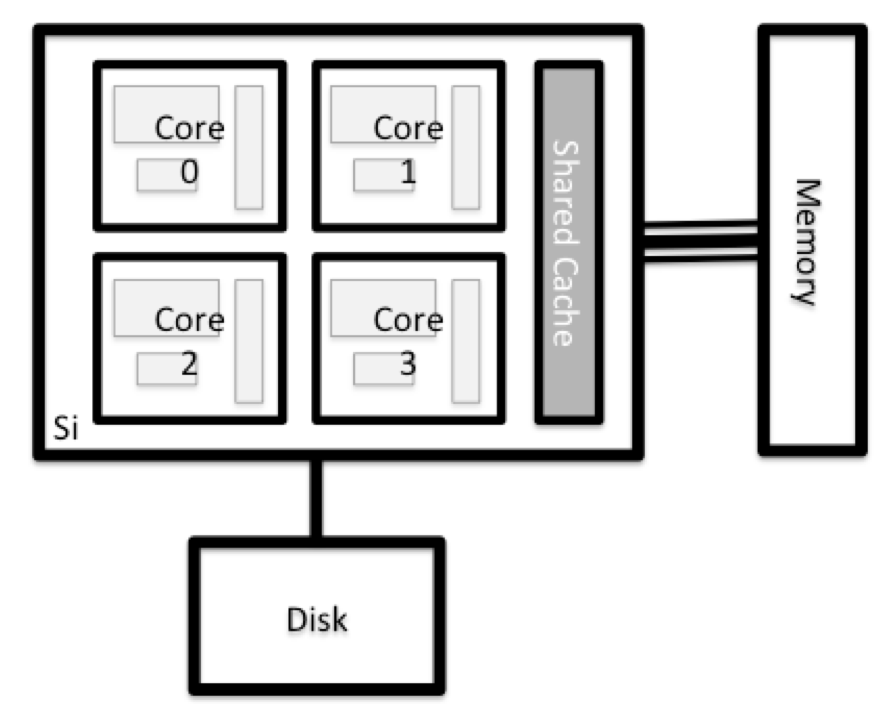
Esplora il tuo computer
Ci sono diversi modi per farlo. La maggior parte dei sistemi operativi ha un monitor grafico di sistema, come il Task Manager di Windows. A volte è possibile trovare informazioni più dettagliate alla riga di comando. Ad esempio, alcuni dei comandi utilizzati su un sistema Linux sono:
Esecuzione delle utilità di sistema
Leggere da /proc
Utilizzare un monitor di sistema
Esplora il nodo di login
Ora confrontate le risorse del vostro computer con quelle del nodo principale.
BASH
[you@laptop:~]$ ssh yourUsername@cluster.hpc-carpentry.org
[yourUsername@login1 ~] nproc --all
[yourUsername@login1 ~] free -mÈ possibile ottenere maggiori informazioni sui processori utilizzando
lscpu, e molti dettagli sulla memoria leggendo il file
/proc/meminfo:
È anche possibile esplorare i filesystem disponibili usando
df per mostrare lo spazio disk
free. Il flag -h rende le dimensioni in un
formato facile da usare, cioè GB invece di B. Il flag
type -T mostra che tipo di filesystem è
ogni risorsa.
I filesystem locali (ext, tmp, xfs, zfs) dipendono dal fatto che ci si trovi sullo stesso nodo di accesso (o nodo di calcolo, più avanti). I filesystem in rete (beegfs, cifs, gpfs, nfs, pvfs) saranno simili — ma potrebbero includere yourUsername, a seconda di come viene [montato] (https://en.wikipedia.org/wiki/Mount_(computing)).
Filesystem condivisi
Questo è un punto importante da ricordare: i file salvati su un nodo (computer) sono spesso disponibili ovunque nel cluster!
Confronta il computer, il nodo di accesso e il nodo di calcolo
Confrontate il numero di processori e di memoria del vostro portatile con i numeri che vedete sul nodo principale del cluster e sul nodo worker. Discutete le differenze con il vostro vicino.
Quali implicazioni pensi che possano avere le differenze nell’esecuzione del tuo lavoro di ricerca sui diversi sistemi e nodi?
Differenze tra i nodi
Molti cluster HPC hanno una varietà di nodi ottimizzati per particolari carichi di lavoro. Alcuni nodi possono disporre di una maggiore quantità di memoria o di risorse specializzate come le unità di elaborazione grafica (GPU).
Con tutto questo in mente, ora vedremo come parlare con lo scheduler del cluster e usarlo per iniziare a eseguire i nostri script e programmi!
- “Un sistema HPC è un insieme di macchine collegate in rete”
- “I sistemi HPC forniscono tipicamente nodi di accesso e una serie di nodi lavoratori.”
- “Le risorse presenti sui nodi indipendenti (lavoratori) possono variare in volume e tipo (quantità di RAM, architettura del processore, disponibilità di filesystem montati in rete, ecc.)
- “I file salvati su un nodo sono disponibili su tutti i nodi.”
Content from Fondamenti di scheduler
Ultimo aggiornamento il 2026-02-26 | Modifica questa pagina
Panoramica
Domande
- Cos’è uno scheduler e perché un cluster ne ha bisogno?
- Come si lancia un programma da eseguire su un nodo di calcolo del cluster?
- Come posso catturare l’output di un programma eseguito su un nodo del cluster?
Obiettivi
- Invia un semplice script al cluster.
- Monitorare l’esecuzione dei lavori utilizzando gli strumenti della riga di comando.
- Ispezionare i file di output e di errore dei lavori.
- Trovare il posto giusto per mettere grandi insiemi di dati sul cluster.
Programmatore di lavoro
Un sistema HPC può avere migliaia di nodi e migliaia di utenti. Come si decide chi riceve cosa e quando? Come facciamo a garantire che un task venga eseguito con le risorse di cui ha bisogno? Questo lavoro è gestito da uno speciale software chiamato scheduler. In un sistema HPC, lo scheduler gestisce i lavori da eseguire dove e quando.
L’illustrazione seguente paragona i compiti di uno schedulatore di lavori a quelli di un cameriere in un ristorante. Se vi è capitato di dover aspettare un po’ in coda per entrare in un ristorante famoso, allora potete capire perché a volte i vostri lavori non partono immediatamente come nel vostro portatile.

Lo scheduler utilizzato in questa lezione è Slurm. Sebbene Slurm non sia utilizzato ovunque, l’esecuzione dei lavori è abbastanza simile indipendentemente dal software utilizzato. La sintassi esatta può cambiare, ma i concetti rimangono gli stessi.
Esecuzione di un lavoro batch
L’uso più semplice dello scheduler è quello di eseguire un comando in modo non interattivo. Qualsiasi comando (o serie di comandi) che si desidera eseguire sul cluster è chiamato lavoro e il processo di utilizzo dello schedulatore per eseguire il lavoro è chiamato invio di lavori in batch.
In questo caso, il lavoro da eseguire è uno script di shell, ovvero un file di testo contenente un elenco di comandi UNIX da eseguire in modo sequenziale. Il nostro script di shell sarà composto da tre parti:
- Alla prima riga, aggiungere
#!/bin/bash. L’opzione#!(pronunciata “hash-bang” o “shebang”) indica al computer quale programma deve elaborare il contenuto di questo file. In questo caso, gli stiamo dicendo che i comandi che seguono sono scritti per la shell a riga di comando (con cui abbiamo fatto tutto finora). - in qualsiasi punto sotto la prima riga, aggiungeremo un comando
echocon un saluto amichevole. Una volta eseguito, lo script di shell stamperà nel terminale qualsiasi cosa venga dopoecho.-
echo -nstamperà tutto ciò che segue, senza terminare la riga stampando il carattere di nuova riga.
-
- Nell’ultima riga, invocheremo il comando
hostname, che stamperà il nome della macchina su cui viene eseguito lo script.
Creare il nostro lavoro di prova
Eseguire lo script. Viene eseguito sul cluster o solo sul nostro nodo di accesso?
Questo script è stato eseguito sul nodo di login, ma vogliamo
sfruttare i nodi di calcolo: abbiamo bisogno che lo scheduler metta in
coda example-job.sh per eseguirlo su un nodo di
calcolo.
Per inviare questo task allo scheduler, si usa il comando
sbatch. Questo crea un lavoro che eseguirà il
script quando verrà spedito a un nodo di calcolo che
il sistema di accodamento ha identificato come disponibile per eseguire
il lavoro.
OUTPUT
Submitted batch job 7E questo è tutto ciò che dobbiamo fare per inviare un lavoro. Il
nostro lavoro è finito: ora lo scheduler prende il sopravvento e cerca
di eseguire il lavoro per noi. Mentre il lavoro è in attesa di essere
eseguito, viene inserito in un elenco di lavori chiamato queue.
Per verificare lo stato del nostro lavoro, controlliamo la coda usando
il comando squeue -u yourUsername.
OUTPUT
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
9 cpubase_b example- user01 R 0:05 1 node1Possiamo vedere tutti i dettagli del nostro lavoro, soprattutto che è
nello stato R o RUNNING. A volte i nostri
lavori potrebbero dover aspettare in coda (PENDING) o avere
un errore (E).
Dov’è l’output?
Nel nodo di accesso, questo script stampava l’output nel terminale,
ma ora, quando squeue mostra che il lavoro è terminato, non
viene stampato nulla nel terminale.
L’output del lavoro del cluster viene solitamente reindirizzato a un
file nella directory da cui è stato lanciato. Usare ls per
trovare e cat per leggere il file.
Personalizzazione di un lavoro
Il lavoro appena eseguito ha utilizzato tutte le opzioni predefinite dello schedulatore. In uno scenario reale, probabilmente non è quello che vogliamo. Le opzioni predefinite rappresentano un minimo ragionevole. È probabile che avremo bisogno di più core, più memoria, più tempo e altre considerazioni speciali. Per avere accesso a queste risorse, dobbiamo personalizzare il nostro script di lavoro.
I commenti negli script di shell UNIX (indicati con #)
sono generalmente ignorati, ma ci sono delle eccezioni. Per esempio, il
commento speciale #! all’inizio degli script specifica
quale programma deve essere usato per eseguirli (di solito si vede
#!/usr/bin/env bash). Anche gli schedulatori, come Slurm,
hanno un commento speciale usato per indicare opzioni specifiche dello
schedulatore. Sebbene questi commenti differiscano da schedulatore a
schedulatore, il commento speciale di Slurm è #SBATCH.
Tutto ciò che segue il commento #SBATCH viene interpretato
come un’istruzione per lo schedulatore.
Illustriamo questo esempio. Per impostazione predefinita, il nome di
un lavoro è il nome dello script, ma l’opzione -J può
essere usata per cambiare il nome di un lavoro. Aggiungere un’opzione
allo script:
Inviare il lavoro e monitorarne lo stato:
OUTPUT
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
10 cpubase_b hello-wo user01 R 0:02 1 node1Fantastico, abbiamo cambiato con successo il nome del nostro lavoro!
Richieste di risorse
Che dire di cambiamenti più importanti, come il numero di core e di memoria per i nostri lavori? Una cosa assolutamente fondamentale quando si lavora su un sistema HPC è specificare le risorse necessarie per eseguire un lavoro. Questo permette allo scheduler di trovare il momento e il posto giusto per programmare il nostro lavoro. Se non si specificano i requisiti (ad esempio la quantità di tempo necessaria), è probabile che si rimanga bloccati con le risorse predefinite del sito, il che probabilmente non è ciò che si desidera.
Le seguenti sono diverse richieste di risorse chiave:
--ntasks=<ntasks>o-n <ntasks>: Di quanti core di CPU ha bisogno il vostro lavoro, in totale?--time <days-hours:minutes:seconds>o-t <days-hours:minutes:seconds>: Quanto tempo reale (walltime) impiegherà il lavoro per essere eseguito? La parte<days>può essere omessa.--mem=<megabytes>: Di quanta memoria su un nodo ha bisogno il lavoro in megabyte? Si possono anche specificare i gigabyte aggiungendo una piccola “g” dopo (esempio:--mem=5g)--nodes=<nnodes>o-N <nnodes>: Su quante macchine separate deve essere eseguito il lavoro? Si noti che se si impostantaskssu un numero superiore a quello che può offrire una sola macchina, Slurm imposterà automaticamente questo valore.
Si noti che il solo fatto di richiedere queste risorse non rende il lavoro più veloce, né significa necessariamente che si consumeranno tutte queste risorse. Significa solo che vengono messe a disposizione. Il lavoro può finire per utilizzare meno memoria, meno tempo o meno nodi di quelli richiesti, ma verrà comunque eseguito.
È meglio che le richieste riflettano accuratamente i requisiti del lavoro. In una puntata successiva di questa lezione parleremo di come assicurarsi di utilizzare le risorse in modo efficace.
Invio di richieste di risorse
Modificare il nostro script hostname in modo che venga
eseguito per un minuto, quindi inviare un lavoro per esso sul
cluster.
Le richieste di risorse sono in genere vincolanti. Se si superano, il lavoro viene eliminato. Utilizziamo il tempo di parete come esempio. Richiederemo 1 minuto di tempo di parete e cercheremo di eseguire un lavoro per due minuti.
BASH
#!/bin/bash
#SBATCH -J long_job
#SBATCH -t 00:01 # timeout in HH:MM
echo "This script is running on ... "
sleep 240 # time in seconds
hostnameInviare il lavoro e attendere che finisca. Una volta terminato, controllare il file di log.
OUTPUT
This script is running on ...
slurmstepd: error: *** JOB 12 ON node1 CANCELLED AT 2021-02-19T13:55:57
DUE TO TIME LIMIT ***Il nostro lavoro è stato annullato per aver superato la quantità di risorse richieste. Anche se questo sembra un problema, in realtà si tratta di una caratteristica. Il rispetto rigoroso delle richieste di risorse consente allo scheduler di trovare il miglior posto possibile per i lavori. Ancora più importante, garantisce che un altro utente non possa utilizzare più risorse di quelle che gli sono state assegnate. Se un altro utente sbaglia e tenta accidentalmente di usare tutti i core o la memoria di un nodo, Slurm limiterà il suo lavoro alle risorse richieste o lo ucciderà del tutto. Gli altri lavori sul nodo non ne risentiranno. Ciò significa che un utente non può rovinare l’esperienza degli altri: gli unici lavori interessati da un errore di programmazione saranno i propri.
Annullamento di un lavoro
A volte capita di commettere un errore e di dover cancellare un
lavoro. Questo può essere fatto con il comando scancel.
Inviamo un lavoro e poi annulliamolo usando il suo numero di lavoro
(ricordate di cambiare il tempo di esecuzione in modo che funzioni
abbastanza a lungo da permettervi di annullarlo prima che venga
ucciso).
OUTPUT
Submitted batch job 13
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
13 cpubase_b long_job user01 R 0:02 1 node1Ora annullate il lavoro con il suo numero (stampato nel terminale). Un ritorno pulito del prompt dei comandi indica che la richiesta di annullamento del lavoro è andata a buon fine.
BASH
[yourUsername@login1 ~] scancel 38759
# It might take a minute for the job to disappear from the queue...
[yourUsername@login1 ~] squeue -u yourUsernameOUTPUT
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)Annullamento di lavori multipli
È anche possibile cancellare tutti i lavori in una volta sola usando
l’opzione -u. In questo modo si cancellano tutti i lavori
di un utente specifico (in questo caso, l’utente stesso). Si noti che è
possibile cancellare solo i propri lavori.
Provare a inviare più lavori e poi annullarli tutti.
Altri tipi di lavoro
Finora ci siamo concentrati sull’esecuzione di lavori in modalità
batch. Slurm offre anche la possibilità di avviare una
sessione interattiva.
Molto spesso ci sono compiti che devono essere eseguiti in modo
interattivo. Creare un intero script di lavoro potrebbe essere
eccessivo, ma la quantità di risorse richieste è troppo elevata per
essere gestita da un nodo di login. Un buon esempio potrebbe essere la
creazione di un indice del genoma per l’allineamento con uno strumento
come HISAT2.
Fortunatamente, è possibile eseguire questo tipo di compiti una tantum
con srun.
srun esegue un singolo comando sul cluster e poi esce.
Dimostriamo questo eseguendo il comando hostname con
srun. (È possibile annullare un lavoro srun
con Ctrl-c)
OUTPUT
smnode1srun accetta tutte le stesse opzioni di
sbatch. Tuttavia, invece di specificarle in uno script,
queste opzioni vengono specificate sulla riga di comando quando si avvia
un lavoro. Per inviare un lavoro che utilizza 2 CPU, ad esempio, si può
usare il seguente comando:
OUTPUT
This job will use 2 CPUs.
This job will use 2 CPUs.In genere, l’ambiente di shell risultante sarà lo stesso di quello di
sbatch.
Lavori interattivi
A volte si ha bisogno di molte risorse per l’uso interattivo. Forse è
la prima volta che si esegue un’analisi o si sta cercando di eseguire il
debug di qualcosa che è andato storto con un lavoro precedente.
Fortunatamente, Slurm semplifica l’avvio di un lavoro interattivo con
srun:
Dovrebbe apparire un prompt di bash. Si noti che il prompt
probabilmente cambierà per riflettere la nuova posizione, in questo caso
il nodo di calcolo su cui si è effettuato l’accesso. Si può anche
verificare con hostname.
Creazione della grafica remota
Per vedere l’output grafico dei lavori, è necessario utilizzare
l’inoltro X11. Per connettersi con questa funzione abilitata, usare
l’opzione -Y quando si effettua il login con il comando
ssh, ad esempio,
ssh -Y yourUsername@cluster.hpc-carpentry.org.
Per dimostrare cosa succede quando si crea una finestra grafica sul
nodo remoto, usare il comando xeyes. Dovrebbe apparire un
paio di occhi relativamente adorabili (premere Ctrl-C per
fermarsi). Se si utilizza un Mac, è necessario aver installato XQuartz
(e riavviato il computer) perché questo funzioni.
Se nel cluster è installato il plugin slurm-spank-x11,
si può garantire l’inoltro X11 nei lavori interattivi usando l’opzione
--x11 per srun con il comando
srun --x11 --pty bash.
Al termine del lavoro interattivo, digitare exit per
uscire dalla sessione.
- Lo scheduler gestisce la condivisione delle risorse di calcolo tra gli utenti.
- Un lavoro è solo uno script di shell.
- Richiedere poco più risorse di quelle necessarie.
Content from Variabili d'ambiente
Ultimo aggiornamento il 2026-02-26 | Modifica questa pagina
Panoramica
Domande
- Come si impostano e come si accede alle variabili nella shell Unix?
- Come si possono usare le variabili per cambiare l’esecuzione di un programma?
Obiettivi
- Capire come vengono implementate le variabili nella shell
- Scoprire il valore di una variabile esistente
- Creare nuove variabili e cambiarne i valori
- Modificare il comportamento di un programma utilizzando una variabile d’ambiente
- Spiegare come la shell utilizza la variabile
PATHper cercare gli eseguibili
Provenienza dell’episodio
Questo episodio è derivato dall’episodio Shell Extras sulle variabili di shell e dall’episodio HPC Shell sugli script.
La shell è solo un programma e, come gli altri programmi, ha delle variabili. Queste variabili controllano la sua esecuzione, quindi cambiando i loro valori si può cambiare il comportamento della shell (e, con un po’ più di sforzo, il comportamento degli altri programmi).
Le variabili sono un ottimo modo per salvare informazioni con un nome a cui si può accedere in seguito. Nei linguaggi di programmazione come Python e R, le variabili possono memorizzare praticamente tutto ciò che si può pensare. Nella shell, di solito, memorizzano solo testo. Il modo migliore per capire come funzionano è vederle in azione.
Cominciamo con l’eseguire il comando set e osserviamo
alcune delle variabili in una tipica sessione di shell:
OUTPUT
COMPUTERNAME=TURING
HOME=/home/vlad
HOSTNAME=TURING
HOSTTYPE=i686
NUMBER_OF_PROCESSORS=4
PATH=/Users/vlad/bin:/usr/local/git/bin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin
PWD=/home/vlad
UID=1000
USERNAME=vlad
...Come si può vedere, ce ne sono parecchie, anzi quattro o cinque volte
di più di quelle mostrate qui. E sì, l’uso di set per
mostrare le cose può sembrare un po’ strano, anche per Unix, ma
se non gli si dà alcun argomento, può anche mostrare cose che si possono
impostare.
Ogni variabile ha un nome. Tutti i valori delle variabili di shell
sono stringhe, anche quelle (come UID) che sembrano numeri.
Spetta ai programmi convertire queste stringhe in altri tipi, se
necessario. Per esempio, se un programma volesse sapere quanti
processori ha il computer, convertirebbe il valore della variabile
NUMBER_OF_PROCESSORS da una stringa a un numero intero.
Mostrare il valore di una variabile
Mostriamo il valore della variabile HOME:
OUTPUT
HOMEQuesto stampa solo “HOME”, che non è quello che volevamo (anche se è quello che abbiamo effettivamente chiesto). Proviamo invece questo:
OUTPUT
/home/vladdove il segno del dollaro indica alla shell che vogliamo il
valore della variabile piuttosto che il suo nome. Questo
funziona proprio come i caratteri jolly: la shell effettua la
sostituzione prima di eseguire il programma richiesto. Grazie a
questa espansione, ciò che viene eseguito è
echo /home/vlad, che mostra la risposta che stavamo
cercando.
Creazione e modifica di variabili
Creare una variabile è facile: basta assegnare un valore a un nome
usando “=” (bisogna solo ricordare che la sintassi richiede che non ci
siano spazi intorno a =):
OUTPUT
DraculaPer cambiare il valore, basta assegnarne uno nuovo:
OUTPUT
CamillaVariabili d’ambiente
Quando abbiamo eseguito il comando set abbiamo visto che
c’erano molte variabili i cui nomi erano in maiuscolo. Questo perché,
per convenzione, le variabili che sono disponibili per l’uso da parte di
altri programmi hanno nomi maiuscoli. Tali variabili sono
chiamate variabili d’ambiente in quanto sono variabili di shell
definite per la shell corrente ed ereditate da qualsiasi shell o altro
processo.
Per creare una variabile d’ambiente è necessario export
una variabile di shell. Ad esempio, per rendere la nostra
SECRET_IDENTITY disponibile ad altri programmi che
chiamiamo dalla nostra shell, possiamo fare:
È anche possibile creare ed esportare la variabile in un unico passaggio:
Usare le variabili d’ambiente per cambiare il comportamento del programma
Impostare una variabile di shell TIME_STYLE per avere un
valore di iso e controllare questo valore con il comando
echo.
Ora, eseguite il comando ls con l’opzione
-l (che dà un formato lungo).
export la variabile e rieseguire il comando
ls -l. Notate qualche differenza?
La variabile TIME_STYLE non viene vista da
ls fino a quando non viene esportata, a quel punto viene
usata da ls per decidere quale formato di data usare quando
presenta il timestamp dei file.
È possibile vedere l’insieme completo delle variabili d’ambiente
nella sessione corrente della shell con il comando env (che
restituisce un sottoinsieme di ciò che ci ha dato il comando
set). L’insieme completo delle variabili d’ambiente
è chiamato ambiente di esecuzione e può influenzare il
comportamento dei programmi eseguiti.
Variabili d’ambiente di lavoro
Quando Slurm esegue un lavoro, imposta una serie di
variabili d’ambiente per il lavoro. Una di queste ci permette di
verificare da quale cartella è stato inviato lo script del lavoro. La
variabile SLURM_SUBMIT_DIR è impostata sulla cartella da
cui è stato inviato il lavoro. Utilizzando la variabile
SLURM_SUBMIT_DIR, modificate il vostro lavoro in modo che
stampi la posizione da cui è stato inviato il lavoro.
Per rimuovere una variabile o una variabile d’ambiente si può usare
il comando unset, ad esempio:
La variabile d’ambiente PATH
Analogamente, alcune variabili d’ambiente (come PATH)
memorizzano elenchi di valori. In questo caso, la convenzione è di usare
i due punti ‘:’ come separatore. Se un programma vuole i singoli
elementi di un tale elenco, è sua responsabilità dividere il valore
della stringa della variabile in pezzi.
Diamo un’occhiata più da vicino alla variabile PATH. Il
suo valore definisce il percorso di ricerca degli eseguibili della
shell, cioè l’elenco delle cartelle in cui la shell cerca i programmi
eseguibili quando si digita il nome di un programma senza specificare la
cartella in cui si trova.
Ad esempio, quando si digita un comando come analyze, la
shell deve decidere se eseguire ./analyze o
/bin/analyze. La regola che utilizza è semplice: la shell
controlla ogni cartella della variabile PATH a turno,
cercando un programma con il nome richiesto in quella cartella. Non
appena trova una corrispondenza, interrompe la ricerca ed esegue il
programma.
Per mostrare come funziona, ecco i componenti di PATH
elencati uno per riga:
OUTPUT
/Users/vlad/bin
/usr/local/git/bin
/usr/bin
/bin
/usr/sbin
/sbin
/usr/local/binSul nostro computer, ci sono in realtà tre programmi chiamati
analyze in tre diverse directory:
/bin/analyze, /usr/local/bin/analyze e
/users/vlad/analyze. Poiché la shell cerca le cartella
nell’ordine in cui sono elencate in PATH, trova prima
/bin/analyze e lo esegue. Si noti che non troverà mai il
programma /users/vlad/analyze a meno che non si digiti il
percorso completo del programma, poiché la cartella
/users/vlad non si trova in PATH.
Questo significa che posso avere eseguibili in molti posti diversi,
purché mi ricordi che devo aggiornare il mio PATH in modo
che la mia shell possa trovarli.
Cosa succede se si vogliono eseguire due versioni diverse dello
stesso programma? Dato che condividono lo stesso nome, se le aggiungo
entrambe alla mia PATH la prima che viene trovata avrà
sempre la meglio. Nel prossimo episodio impareremo a usare strumenti di
aiuto per gestire il nostro ambiente di runtime, in modo da renderlo
possibile senza dover fare un sacco di conti su quale sia o debba essere
il valore di PATH (e di altre importanti variabili
d’ambiente).
- Le variabili di shell sono trattate per impostazione predefinita come stringhe
- Le variabili vengono assegnate utilizzando “
=” e richiamate utilizzando il nome della variabile preceduto da “$” - Usare “
export” per rendere una variabile disponibile ad altri programmi - La variabile
PATHdefinisce il percorso di ricerca della shell
Content from Accesso al software tramite moduli
Ultimo aggiornamento il 2026-02-26 | Modifica questa pagina
Panoramica
Domande
- Come si caricano e scaricano i pacchetti software?
Obiettivi
- Caricare ed utilizza un pacchetto software.
- Spiegare come cambia l’ambiente della shell quando il meccanismo dei moduli carica o scarica i pacchetti.
In un sistema di calcolo ad alte prestazioni, raramente il software che vogliamo usare è disponibile al momento dell’accesso. È installato, ma è necessario “caricarlo” prima che possa essere eseguito.
Prima di iniziare a utilizzare i singoli pacchetti software, tuttavia, è necessario comprendere il ragionamento alla base di questo approccio. I tre fattori principali sono:
- incompatibilità software
- versioning
- dipendenze
L’incompatibilità del software è un grosso grattacapo per i
programmatori. A volte, la presenza (o l’assenza) di un pacchetto
software ne interrompe altri che dipendono da esso. Due esempi ben noti
sono le versioni dei compilatori Python e C. Python 3 fornisce un
comando python che è in conflitto con quello fornito da
Python 2. Il software compilato con una versione più recente del
compilatore C non è in grado di funzionare. Il software compilato con
una versione più recente delle librerie C e poi eseguito su una macchina
in cui sono installate librerie C più vecchie, darà luogo a uno
spiacevole errore 'GLIBCXX_3.4.20' not found.
La gestione delle versioni del software è un altro problema comune. Un gruppo di lavoro potrebbe dipendere da una certa versione di un pacchetto per il proprio progetto di ricerca; se la versione del software dovesse cambiare (per esempio, se un pacchetto venisse aggiornato), i risultati potrebbero risentirne. Avere accesso a più versioni del software permette a un gruppo di ricercatori di evitare che i problemi di versione del software influenzino i loro risultati.
Le dipendenze si riferiscono a quando un particolare pacchetto software (o anche una particolare versione) dipende dall’accesso a un altro pacchetto software (o anche a una particolare versione di un altro pacchetto software). Ad esempio, il software per la scienza dei materiali VASP può dipendere dalla disponibilità di una particolare versione della libreria software FFTW (Fastest Fourier Transform in the West) per funzionare.
Moduli d’ambiente
I moduli d’ambiente sono la soluzione a questi problemi. Un modulo è una descrizione autonoma di un pacchetto software: contiene le impostazioni necessarie per eseguire un pacchetto software e, di solito, codifica le dipendenze necessarie da altri pacchetti software.
Esistono diverse implementazioni di moduli di ambiente comunemente
utilizzate sui sistemi HPC: le due più comuni sono TCL modules
e Lmod. Entrambi utilizzano una sintassi simile e i concetti
sono gli stessi, quindi imparare a usarne uno vi permetterà di
utilizzare quello installato sul sistema che state usando. In entrambe
le implementazioni il comando module è usato per interagire
con i moduli di ambiente. Al comando viene solitamente aggiunto un
ulteriore sottocomando per specificare ciò che si vuole fare. Per un
elenco di sottocomandi si può usare module -h o
module help. Come per tutti i comandi, è possibile accedere
alla guida completa nelle pagine di man con
man module.
All’accesso si può iniziare con un set predefinito di moduli caricati o con un ambiente vuoto; ciò dipende dalla configurazione del sistema in uso.
Elenco dei moduli disponibili
Per vedere i moduli software disponibili, usare
module avail:
OUTPUT
~~~ /cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/modules/all ~~~
Bazel/3.6.0-GCCcore-x.y.z NSS/3.51-GCCcore-x.y.z
Bison/3.5.3-GCCcore-x.y.z Ninja/1.10.0-GCCcore-x.y.z
Boost/1.72.0-gompi-2020a OSU-Micro-Benchmarks/5.6.3-gompi-2020a
CGAL/4.14.3-gompi-2020a-Python-3.x.y OpenBLAS/0.3.9-GCC-x.y.z
CMake/3.16.4-GCCcore-x.y.z OpenFOAM/v2006-foss-2020a
[removed most of the output here for clarity]
Where:
L: Module is loaded
Aliases: Aliases exist: foo/1.2.3 (1.2) means that "module load foo/1.2"
will load foo/1.2.3
D: Default Module
Use "module spider" to find all possible modules and extensions.
Use "module keyword key1 key2 ..." to search for all possible modules matching
any of the "keys".Caricamento e scaricamento del software
Per caricare un modulo software, usare module load. In
questo esempio useremo Python 3.
Inizialmente, Python 3 non viene caricato. Si può verificare usando
il comando which che cerca i programmi nello stesso modo in
cui lo fa Bash, quindi possiamo usarlo per sapere dove è memorizzato un
particolare software.
Se il comando python3 non fosse disponibile, si vedrebbe
un risultato come
OUTPUT
/usr/bin/which: no python3 in (/cvmfs/pilot.eessi-hpc.org/2020.12/compat/linux/x86_64/usr/bin:/opt/software/slurm/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/puppetlabs/bin:/home/yourUsername/.local/bin:/home/yourUsername/bin)Si noti che questo blocco di testo è in realtà un elenco, con i
valori separati dal carattere :. L’output ci dice che il
comando which ha cercato python3 nelle
seguenti directory, senza successo:
OUTPUT
/cvmfs/pilot.eessi-hpc.org/2020.12/compat/linux/x86_64/usr/bin
/opt/software/slurm/bin
/usr/local/bin
/usr/bin
/usr/local/sbin
/usr/sbin
/opt/puppetlabs/bin
/home/yourUsername/.local/bin
/home/yourUsername/binTuttavia, nel nostro caso abbiamo un python3 esistente
disponibile, quindi vediamo
OUTPUT
/cvmfs/pilot.eessi-hpc.org/2020.12/compat/linux/x86_64/usr/bin/python3Comunque abbiamo bisogno di un Python diverso da quello fornito dal sistema, quindi carichiamo un modulo per accedervi.
Possiamo caricare il comando python3 con
module load:
OUTPUT
/cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/Python/3.x.y-GCCcore-x.y.z/bin/python3Allora, cosa è successo?
Per comprendere l’output, occorre innanzitutto capire la natura della
variabile d’ambiente $PATH. $PATH è una
variabile d’ambiente speciale che controlla dove un sistema UNIX cerca
il software. In particolare, $PATH è un elenco di directory
(separate da :) in cui il sistema operativo cerca un
comando prima di arrendersi e dire che non lo trova. Come per tutte le
variabili d’ambiente, è possibile stamparle usando
echo.
OUTPUT
/cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/Python/3.x.y-GCCcore-x.y.z/bin:/cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/SQLite/3.31.1-GCCcore-x.y.z/bin:/cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/Tcl/8.6.10-GCCcore-x.y.z/bin:/cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/GCCcore/x.y.z/bin:/cvmfs/pilot.eessi-hpc.org/2020.12/compat/linux/x86_64/usr/bin:/opt/software/slurm/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/puppetlabs/bin:/home/user01/.local/bin:/home/user01/binNoterete una somiglianza con l’output del comando which.
In questo caso, c’è solo una differenza: la diversa cartella all’inizio.
Quando abbiamo eseguito il comando module load, questo ha
aggiunto una cartella all’inizio del nostro $PATH.
Esaminiamo cosa c’è:
BASH
[yourUsername@login1 ~] ls /cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/software/Python/3.x.y-GCCcore-x.y.z/binOUTPUT
2to3 nosetests-3.8 python rst2s5.py
2to3-3.8 pasteurize python3 rst2xetex.py
chardetect pbr python3.8 rst2xml.py
cygdb pip python3.8-config rstpep2html.py
cython pip3 python3-config runxlrd.py
cythonize pip3.8 rst2html4.py sphinx-apidoc
easy_install pybabel rst2html5.py sphinx-autogen
easy_install-3.8 __pycache__ rst2html.py sphinx-build
futurize pydoc3 rst2latex.py sphinx-quickstart
idle3 pydoc3.8 rst2man.py tabulate
idle3.8 pygmentize rst2odt_prepstyles.py virtualenv
netaddr pytest rst2odt.py wheel
nosetests py.test rst2pseudoxml.pyPortando questo alla sua conclusione, module load
aggiungerà software al vostro $PATH e carica il software.
Una nota speciale: a seconda della versione del programma
module installata nel sito, module load
caricherà anche le dipendenze software necessarie.
Per dimostrarlo, usiamo module list che mostra tutti i
moduli software caricati.
OUTPUT
Currently Loaded Modules:
1) GCCcore/x.y.z 4) GMP/6.2.0-GCCcore-x.y.z
2) Tcl/8.6.10-GCCcore-x.y.z 5) libffi/3.3-GCCcore-x.y.z
3) SQLite/3.31.1-GCCcore-x.y.z 6) Python/3.x.y-GCCcore-x.y.zOUTPUT
Currently Loaded Modules:
1) GCCcore/x.y.z 14) libfabric/1.11.0-GCCcore-x.y.z
2) Tcl/8.6.10-GCCcore-x.y.z 15) PMIx/3.1.5-GCCcore-x.y.z
3) SQLite/3.31.1-GCCcore-x.y.z 16) OpenMPI/4.0.3-GCC-x.y.z
4) GMP/6.2.0-GCCcore-x.y.z 17) OpenBLAS/0.3.9-GCC-x.y.z
5) libffi/3.3-GCCcore-x.y.z 18) gompi/2020a
6) Python/3.x.y-GCCcore-x.y.z 19) FFTW/3.3.8-gompi-2020a
7) GCC/x.y.z 20) ScaLAPACK/2.1.0-gompi-2020a
8) numactl/2.0.13-GCCcore-x.y.z 21) foss/2020a
9) libxml2/2.9.10-GCCcore-x.y.z 22) pybind11/2.4.3-GCCcore-x.y.z-Pytho...
10) libpciaccess/0.16-GCCcore-x.y.z 23) SciPy-bundle/2020.03-foss-2020a-Py...
11) hwloc/2.2.0-GCCcore-x.y.z 24) networkx/2.4-foss-2020a-Python-3.8...
12) libevent/2.1.11-GCCcore-x.y.z 25) GROMACS/2020.1-foss-2020a-Python-3...
13) UCX/1.8.0-GCCcore-x.y.zIn questo caso, il caricamento del modulo GROMACS (un
pacchetto software bioinformatico) ha caricato anche
GMP/6.2.0-GCCcore-x.y.z e
SciPy-bundle/2020.03-foss-2020a-Python-3.x.y. Proviamo a
scaricare il pacchetto GROMACS.
OUTPUT
Currently Loaded Modules:
1) GCCcore/x.y.z 13) UCX/1.8.0-GCCcore-x.y.z
2) Tcl/8.6.10-GCCcore-x.y.z 14) libfabric/1.11.0-GCCcore-x.y.z
3) SQLite/3.31.1-GCCcore-x.y.z 15) PMIx/3.1.5-GCCcore-x.y.z
4) GMP/6.2.0-GCCcore-x.y.z 16) OpenMPI/4.0.3-GCC-x.y.z
5) libffi/3.3-GCCcore-x.y.z 17) OpenBLAS/0.3.9-GCC-x.y.z
6) Python/3.x.y-GCCcore-x.y.z 18) gompi/2020a
7) GCC/x.y.z 19) FFTW/3.3.8-gompi-2020a
8) numactl/2.0.13-GCCcore-x.y.z 20) ScaLAPACK/2.1.0-gompi-2020a
9) libxml2/2.9.10-GCCcore-x.y.z 21) foss/2020a
10) libpciaccess/0.16-GCCcore-x.y.z 22) pybind11/2.4.3-GCCcore-x.y.z-Pytho...
11) hwloc/2.2.0-GCCcore-x.y.z 23) SciPy-bundle/2020.03-foss-2020a-Py...
12) libevent/2.1.11-GCCcore-x.y.z 24) networkx/2.4-foss-2020a-Python-3.x.yL’uso di module unload “scarica” un modulo e, a seconda
di come è configurato un sito, può anche scaricare tutte le dipendenze
(nel nostro caso non lo fa). Se si volesse scaricare tutto in una volta,
si potrebbe eseguire module purge (scarica tutto).
OUTPUT
No modules loadedSi noti che module purge è informativo perché ci farà
anche sapere se un insieme predefinito di pacchetti “appiccicosi” non
può essere scaricato (e come scaricarli se lo si desidera
veramente).
Questo processo di caricamento del modulo avviene principalmente
attraverso la manipolazione di variabili d’ambiente come
$PATH. Di solito il trasferimento di dati è minimo o
nullo.
Il processo di caricamento dei moduli manipola anche altre variabili d’ambiente speciali, tra cui quelle che influenzano la ricerca delle librerie software da parte del sistema e, talvolta, quelle che indicano ai pacchetti software commerciali dove trovare i server delle licenze.
Il comando module ripristina anche queste variabili d’ambiente della shell al loro stato precedente quando un modulo viene scaricato.
Versione del software
Finora abbiamo imparato a caricare e scaricare i pacchetti software. Questo è molto utile. Tuttavia, non abbiamo ancora affrontato il problema del versionamento del software. Prima o poi ci si imbatterà in problemi in cui solo una particolare versione di un software sarà adatta. Forse la correzione di un bug fondamentale è avvenuta solo in una certa versione, oppure la versione X ha interrotto la compatibilità con un formato di file utilizzato. In entrambi questi casi, è utile essere molto precisi sul software caricato.
Esaminiamo più da vicino l’output di module avail.
OUTPUT
~~~ /cvmfs/pilot.eessi-hpc.org/2020.12/software/x86_64/amd/zen2/modules/all ~~~
Bazel/3.6.0-GCCcore-x.y.z NSS/3.51-GCCcore-x.y.z
Bison/3.5.3-GCCcore-x.y.z Ninja/1.10.0-GCCcore-x.y.z
Boost/1.72.0-gompi-2020a OSU-Micro-Benchmarks/5.6.3-gompi-2020a
CGAL/4.14.3-gompi-2020a-Python-3.x.y OpenBLAS/0.3.9-GCC-x.y.z
CMake/3.16.4-GCCcore-x.y.z OpenFOAM/v2006-foss-2020a
[removed most of the output here for clarity]
Where:
L: Module is loaded
Aliases: Aliases exist: foo/1.2.3 (1.2) means that "module load foo/1.2"
will load foo/1.2.3
D: Default Module
Use "module spider" to find all possible modules and extensions.
Use "module keyword key1 key2 ..." to search for all possible modules matching
any of the "keys".Utilizzo dei moduli software negli script
Creare un lavoro in grado di eseguire python3 --version.
Ricordate che per impostazione predefinita non viene caricato alcun
software! Eseguire un lavoro è come accedere al sistema (non si deve
dare per scontato che un modulo caricato sul nodo di login sia caricato
su un nodo di calcolo).
- Caricare il software con
module load softwareName. - Scaricare il software con
module unload - Il sistema dei moduli gestisce automaticamente le versioni del software e i conflitti tra i pacchetti.
Content from Trasferimento di file da computer remoti
Ultimo aggiornamento il 2026-02-26 | Modifica questa pagina
Panoramica
Domande
- Come si trasferiscono i file al (e dal) cluster?
Obiettivi
- Trasferimento di file da e verso un cluster di calcolo.
Eseguire il lavoro su un computer remoto non è molto utile se non si possono muovere file da o verso il cluster. Esistono diverse opzioni per trasferire i dati tra le risorse di calcolo utilizzando le utility CLI e GUI. Qui di seguito tratteremo alcune di queste opzioni.
Scaricare i file delle lezioni da Internet
Uno dei modi più semplici per scaricare i file è usare
curl o wget. Almeno uno di questi è
solitamente installato nella maggior parte delle shell di Linux, nel
terminale di Mac OS e in GitBash. Qualsiasi file che può essere
scaricato nel browser web attraverso un link diretto può essere
scaricato usando curl o wget. Si tratta di un
modo rapido per scaricare insiemi di dati o codice sorgente. La sintassi
di questi comandi è
wget [-O new_name] https://some/link/to/a/filecurl [-o new_name] https://some/link/to/a/file
provate a scaricare del materiale che useremo in seguito, da un terminale sulla vostra macchina locale, usando l’URL della base di codice corrente:
https://github.com/hpc-carpentry/amdahl/tarball/main
Scarica il “Tarball”
La parola “tarball” nell’URL di cui sopra si riferisce a un formato
di archivio compresso comunemente usato su Linux, che è il sistema
operativo su cui gira la maggior parte dei cluster HPC. Un tarball è
molto simile a un file .zip. L’estensione effettiva del
file è .tar.gz, che riflette il processo in due fasi
utilizzato per creare il file: i file o le cartelle vengono uniti in un
unico file utilizzando tar, che viene poi compresso
utilizzando gzip, quindi l’estensione del file è
“tar-dot-g-z” È una parola lunga, quindi spesso si dice “il tarball
xyz”.
si può anche vedere l’estensione .tgz, che è solo
un’abbreviazione di .tar.gz.
Per impostazione predefinita, curl e wget
scaricano i file con lo stesso nome dell’URL: in questo caso,
main. Usare uno dei comandi precedenti per salvare il
tarball come amdahl.tar.gz.
Dopo aver scaricato il file, si può usare ls per vederlo
nella propria cartella di lavoro:
Archiviazione dei file
Una delle maggiori sfide che spesso ci troviamo ad affrontare quando trasferiamo dati tra sistemi HPC remoti è quella di un gran numero di file. Il trasferimento di ogni singolo file comporta un sovraccarico e quando si trasferisce un gran numero di file questi sovraccarichi si combinano per rallentare notevolmente i trasferimenti.
La soluzione a questo problema è quella di archiviare più
file in un numero minore di file più grandi prima di trasferire i dati
per migliorare l’efficienza del trasferimento. A volte si combina
l’archiviazione con la compressione per ridurre la quantità di
dati da trasferire e quindi velocizzare il trasferimento. Il comando di
archiviazione più comune che si usa su un cluster HPC (Linux) è
tar.
tar può essere usato per combinare file e cartelle in un
unico file di archivio e, facoltativamente, comprimere il risultato.
Osserviamo il file scaricato dal sito della lezione,
amdahl.tar.gz.
La parte .gz sta per gzip, che è una libreria
di compressione. È comune (ma non necessario!) che questo tipo di file
possa essere interpretato leggendo il suo nome: sembra che qualcuno
abbia preso file e cartelle relativi a qualcosa chiamato “amdahl”, li
abbia impacchettati tutti in un singolo file con tar,
quindi abbia compresso l’archivio con gzip per risparmiare
spazio.
Vediamo se questo è il caso, senza scompattare il file.
tar stampa il “**testo del contenuto” con il flag
-t, per il file specificato con il flag -f
seguito dal nome del file. Si noti che è possibile concatenare i due
flag: scrivere -t -f è intercambiabile con scrivere
-tf insieme. Tuttavia, l’argomento che segue
-f deve essere un nome di file, quindi scrivere
-ft non funzionerà.
BASH
[you@laptop:~]$ tar -tf amdahl.tar.gz
hpc-carpentry-amdahl-46c9b4b/
hpc-carpentry-amdahl-46c9b4b/.github/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/python-publish.yml
hpc-carpentry-amdahl-46c9b4b/.gitignore
hpc-carpentry-amdahl-46c9b4b/LICENSE
hpc-carpentry-amdahl-46c9b4b/README.md
hpc-carpentry-amdahl-46c9b4b/amdahl/
hpc-carpentry-amdahl-46c9b4b/amdahl/__init__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/__main__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/amdahl.py
hpc-carpentry-amdahl-46c9b4b/requirements.txt
hpc-carpentry-amdahl-46c9b4b/setup.pyQuesto esempio di output mostra una cartella che contiene alcuni
file, dove 46c9b4b è un hash di commit di 8 caratteri git che cambierà
quando il materiale sorgente verrà aggiornato.
Ora scompattiamo l’archivio. Eseguiremo tar con alcuni
flag comuni:
-
-xper estrarre l’archivio -
-vper un output verboso -
-zper la compressione gzip -
-f «tarball»per il file da scompattare
Estrazione dell’archivio
Usando i flag di cui sopra, scompattare il tarball del codice
sorgente in una nuova directory chiamata “amdahl” usando
tar.
OUTPUT
hpc-carpentry-amdahl-46c9b4b/
hpc-carpentry-amdahl-46c9b4b/.github/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/
hpc-carpentry-amdahl-46c9b4b/.github/workflows/python-publish.yml
hpc-carpentry-amdahl-46c9b4b/.gitignore
hpc-carpentry-amdahl-46c9b4b/LICENSE
hpc-carpentry-amdahl-46c9b4b/README.md
hpc-carpentry-amdahl-46c9b4b/amdahl/
hpc-carpentry-amdahl-46c9b4b/amdahl/__init__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/__main__.py
hpc-carpentry-amdahl-46c9b4b/amdahl/amdahl.py
hpc-carpentry-amdahl-46c9b4b/requirements.txt
hpc-carpentry-amdahl-46c9b4b/setup.pyDa notare che non è stato necessario digitare
-x -v -z -f, grazie alla concatenazione dei flag, anche se
il comando funziona in modo identico in entrambi i casi, purché l’elenco
concatenato termini con f, perché la stringa successiva
deve specificare il nome del file da estrarre.
La cartella ha un nome non adatto, quindi cambiamolo con qualcosa di più comodo.
Controllare la dimensione della directory estratta e confrontarla con
la dimensione del file compresso, usando du per
“disk usage”.
BASH
[you@laptop:~]$ du -sh amdahl.tar.gz
8.0K amdahl.tar.gz
[you@laptop:~]$ du -sh amdahl
48K amdahlI file di testo (compreso il codice sorgente Python) si comprimono bene: il “tarball” è un sesto della dimensione totale dei dati grezzi!
Se si vuole invertire il processo - comprimere i dati grezzi invece
di estrarli - impostare un flag c invece di x,
impostare il nome del file di archivio e fornire una cartella da
comprimere:
OUTPUT
amdahl/
amdahl/.github/
amdahl/.github/workflows/
amdahl/.github/workflows/python-publish.yml
amdahl/.gitignore
amdahl/LICENSE
amdahl/README.md
amdahl/amdahl/
amdahl/amdahl/__init__.py
amdahl/amdahl/__main__.py
amdahl/amdahl/amdahl.py
amdahl/requirements.txt
amdahl/setup.pySe si dà amdahl.tar.gz come nome del file nel comando
precedente, tar aggiornerà il tarball esistente con
qualsiasi modifica apportata ai file. Ciò significa aggiungere la nuova
cartella amdahl alla cartella esistente
(hpc-carpentry-amdahl-46c9b4b) all’interno del tarball,
raddoppiando le dimensioni dell’archivio!
Lavorare con Windows
Quando si trasferiscono file di testo da un sistema Windows a un sistema Unix (Mac, Linux, BSD, Solaris, ecc.) si possono verificare dei problemi. Windows codifica i suoi file in modo leggermente diverso da Unix e aggiunge un carattere extra a ogni riga.
In un sistema Unix, ogni riga di un file termina con un
\n (newline). Su Windows, ogni riga di un file termina con
un \r\n (ritorno a capo + newline).
Sebbene la maggior parte dei linguaggi di programmazione e dei
software moderni gestisca questo problema correttamente, in alcuni rari
casi si può incorrere in un problema. La soluzione consiste nel
convertire un file dalla codifica Windows a quella Unix con il comando
dos2unix.
È possibile identificare se un file ha terminazioni di riga Windows
con cat -A filename. Un file con terminazioni di riga
Windows avrà ^M$ alla fine di ogni riga. Un file con
terminazioni di riga Unix avrà $ alla fine di una riga.
Per convertire il file, basta eseguire
dos2unix filename. (Viceversa, per riconvertire il formato
Windows, si può eseguire unix2dos filename)
Trasferimento di singoli file e cartelle con scp
Per copiare un singolo file da o verso il cluster, si può usare
scp (“copia sicura”). La sintassi può essere un po’
complessa per i nuovi utenti, ma la spiegheremo. Il comando
scp è un parente del comando ssh che abbiamo
usato per accedere al sistema e può usare lo stesso meccanismo di
autenticazione a chiave pubblica.
per caricare su un altro computer, il comando modello è
in cui @ e : sono separatori di campo e
remote_destination è un percorso relativo alla vostra home
directory remota, o un nuovo nome di file se desiderate cambiarlo, o sia
un percorso relativo e un nuovo nome di file. Se non si ha in
mente una cartella specifica, si può omettere la
remote_destination e il file verrà copiato nella propria
home directory sul computer remoto (con il nome originale). Se si
include un remote_destination, si noti che scp
lo interpreta nello stesso modo in cui lo interpreta cp
quando si effettuano copie locali: se esiste ed è una cartella, il file
viene copiato all’interno della cartella; se esiste ed è un file, il
file viene sovrascritto con il contenuto di local_file; se
non esiste, si presume che sia un nome di file di destinazione per
local_file.
Carica il materiale della lezione nella tua cartella home remota in questo modo:
Perché non scaricare direttamente su HPC Carpentry’s Cloud Cluster?
La maggior parte dei cluster di computer sono protetti da Internet da un firewall. Per una maggiore sicurezza, alcuni sono configurati per consentire il traffico in entrata, ma non in uscita. Ciò significa che un utente autenticato può inviare un file a un computer del cluster, ma un computer del cluster non può recuperare i file dal computer di un utente o da Internet.
Provare a scaricare direttamente il file. Si noti che potrebbe fallire, ma va bene così!
Perché non scaricare direttamente su HPC Carpentry’s Cloud Cluster? (continued)
Ha funzionato? Se no, che cosa ci dice l’output del terminale su ciò che è successo?
Trasferimento di una cartella
Per trasferire un’intera cartella, aggiungiamo il flag
-r per “recursive”: copia l’elemento
specificato, e ogni elemento sotto di esso, e ogni elemento sotto di
esso… fino a raggiungere il fondo dell’albero delle cartelle con radice
nel nome della cartella fornito.
Attenzione
Per una cartella di grandi dimensioni, sia in termini di dimensioni
che di numero di file, la copia con -r può richiedere molto
tempo.
Quando si usa scp, si può notare che un :
segue sempre il nome del computer remoto. Una stringa
dopo la : specifica la cartella remota in cui si
desidera trasferire il file o la cartella, compreso un nuovo nome se si
desidera rinominare il materiale remoto. Se si lascia questo campo
vuoto, per impostazione predefinita, scp è la propria
cartella home e il nome del materiale locale da trasferire.
Nei computer Linux, / è il separatore nei percorsi di
file o cartelle. Un percorso che inizia con un / è detto
assoluto, poiché non può esserci nulla al di sopra della radice
/. Un percorso che non inizia con / è detto
relativo, poiché non è ancorato alla radice.
Se si vuole caricare un file in una posizione all’interno della
propria cartella home, cosa che accade spesso, non è necessario un
/. Dopo il :, si può digitare il percorso di
destinazione relativo alla propria cartella home. Se questa è
la destinazione, si può lasciare il campo della destinazione vuoto,
oppure digitare ~ – l’abbreviazione della propria cartella
home – per completezza.
Con scp, una barra tracciante sulla cartella di
destinazione è opzionale e non ha alcun effetto. Il trattino sulla
cartella di origine è importante per altri comandi, come
rsync.
Nota su rsync
Man mano che si acquisisce esperienza nel trasferimento di file, il
comando scp può risultare limitante. L’utilità rsync fornisce funzioni avanzate per
il trasferimento di file ed è tipicamente più veloce sia di
scp che di sftp (vedi sotto). È
particolarmente utile per trasferire file di grandi dimensioni e/o
numerosi e per sincronizzare il contenuto delle cartelle tra
computer.
La sintassi è simile a quella di scp. Per trasferire
a un altro computer con le opzioni comunemente usate:
Le opzioni sono:
-
-a(unarchivio) per conservare i timestamp dei file, i permessi e le cartelle, tra le altre cose; implica la ricorsione -
-v(verbose) per ottenere un output verboso che aiuti a monitorare il trasferimento -
-P(parziale/progresso) per preservare i file parzialmente trasferiti in caso di interruzione e per visualizzare il progresso del trasferimento.
Per copiare ricorsivamente una cartella, si possono usare le stesse opzioni:
così come è scritto, la cartella locale e il suo contenuto si trovano sotto la propria cartella home sul sistema remoto. Se all’origine viene aggiunto un trattino, non verrà creata una nuova cartella corrispondente alla cartella trasferita e il contenuto della cartella di origine verrà copiato direttamente nella cartella di destinazione.
Per scaricare un file, basta cambiare la sorgente e la destinazione:
I trasferimenti di file che utilizzano sia scp che
rsync utilizzano SSH per crittografare i dati inviati
attraverso la rete. Quindi, se ci si può connettere tramite SSH, si
potranno trasferire i file. Per impostazione predefinita, SSH utilizza
la porta 22 della rete. Se è in uso una porta SSH personalizzata, è
necessario specificarla usando il flag appropriato, spesso
-p, -P o --port. Controllare
--help o la pagina man se non si è sicuri.
BASH
[you@laptop:~]$ man rsync
[you@laptop:~]$ rsync --help | grep port
--port=PORT specify double-colon alternate port number
See http://rsync.samba.org/ for updates, bug reports, and answers
[you@laptop:~]$ rsync --port=768 amdahl.tar.gz yourUsername@cluster.hpc-carpentry.org:(Si noti che questo comando fallirà, poiché la porta corretta in questo caso è quella predefinita: 22)
Trasferimento interattivo di file con FileZilla
FileZilla è un client multipiattaforma per scaricare e caricare file
da e verso un computer remoto. È assolutamente infallibile e funziona
sempre abbastanza bene. Utilizza il protocollo sftp. Per
saperne di più sull’uso del protocollo sftp nella riga di
comando, consultare la [discussione della lezione]
(../learning/discuss.md).
Scaricare e installare il client FileZilla da https://filezilla-project.org. Dopo l’installazione e l’apertura del programma, dovrebbe apparire una finestra con un browser di file del sistema locale sul lato sinistro dello schermo. Quando ci si connette al cluster, i file del cluster appariranno sul lato destro.
Per connettersi al cluster, è sufficiente inserire le proprie credenziali nella parte superiore dello schermo:
- Host:
sftp://cluster.hpc-carpentry.org - Utente: il nome utente del cluster
- Password: La password del cluster
- Porta: (lasciare vuoto per usare la porta predefinita)
premere “Quickconnect” per connettersi. I file remoti dovrebbero apparire sul lato destro dello schermo. È possibile trascinare i file tra il lato sinistro (locale) e quello destro (remoto) dello schermo per trasferirli.
Infine, se si devono spostare file di grandi dimensioni (tipicamente
più grandi di un gigabyte) da un computer remoto a un altro computer
remoto, si deve accedere con SSH al computer che ospita i file e usare
scp o rsync per trasferirli all’altro. Questo
sarà più efficiente rispetto all’uso di FileZilla (o di applicazioni
simili) che copierebbe dalla sorgente al computer locale e poi al
computer di destinazione.
-
wgetecurl -Oscaricano un file da Internet. -
scpersynctrasferiscono i file da e verso il computer. - È possibile utilizzare un client SFTP come FileZilla per trasferire i file attraverso un’interfaccia grafica.
Content from Esecuzione di un lavoro in parallelo
Ultimo aggiornamento il 2026-02-26 | Modifica questa pagina
Panoramica
Domande
- Come si esegue un’attività in parallelo?
- Quali vantaggi derivano dall’esecuzione in parallelo?
- Quali sono i limiti dei guadagni derivanti dall’esecuzione in parallelo?
Obiettivi
- Installare un pacchetto Python utilizzando
pip - Preparare uno script di invio del lavoro per l’esecuzione in parallelo.
- Avvio di lavori con esecuzione in parallelo.
- Registrare e riassumere i tempi e la precisione dei lavori.
- Descrivere la relazione tra parallelismo dei lavori e prestazioni.
Ora abbiamo gli strumenti necessari per eseguire un lavoro multiprocessore. Si tratta di un aspetto molto importante dei sistemi HPC, poiché il parallelismo è uno degli strumenti principali di cui disponiamo per migliorare le prestazioni delle attività di calcolo.
Se si è disconnessi, accedere nuovamente al cluster.
Installare il programma Amdahl
Con il codice sorgente di Amdahl sul cluster, possiamo installarlo,
il che ci darà accesso all’eseguibile amdahl. Spostarsi
nella cartella estratta, quindi usare il Package Installer for Python, o
pip, per installarlo nella propria cartella home
(“utente”):
Amdahl è un codice Python
Il programma Amdahl è scritto in Python e per installarlo o
utilizzarlo è necessario individuare l’eseguibile python3
sul nodo di accesso. Se non si riesce a trovarlo, provare a elencare i
moduli disponibili usando module avail, caricare quello
appropriato e riprovare il comando.
MPI per Python
Il codice Amdahl ha una sola dipendenza: mpi4py. Se
non è già stato installato sul cluster, pip cercherà di
prelevare mpi4py da Internet e di installarlo per l’utente. Se ciò
fallisce a causa di un firewall unidirezionale, è necessario recuperare
mpi4py sulla propria macchina locale e caricarlo, proprio come abbiamo
fatto per Amdahl.
Recupero e caricamento di
mpi4py
Se l’installazione di Amdahl non è riuscita perché non è stato
possibile installare mpi4py, recuperare il tarball da https://github.com/mpi4py/mpi4py/tarball/master quindi
rsync sul cluster, estrarlo e installarlo:
BASH
[you@laptop:~]$ wget -O mpi4py.tar.gz https://github.com/mpi4py/mpi4py/releases/download/3.1.4/mpi4py-3.1.4.tar.gz
[you@laptop:~]$ scp mpi4py.tar.gz yourUsername@cluster.hpc-carpentry.org:
# or
[you@laptop:~]$ rsync -avP mpi4py.tar.gz yourUsername@cluster.hpc-carpentry.org:BASH
[you@laptop:~]$ ssh yourUsername@cluster.hpc-carpentry.org
[yourUsername@login1 ~] tar -xvzf mpi4py.tar.gz # extract the archive
[yourUsername@login1 ~] mv mpi4py* mpi4py # rename the directory
[yourUsername@login1 ~] cd mpi4py
[yourUsername@login1 ~] python3 -m pip install --user .
[yourUsername@login1 ~] cd ../amdahl
[yourUsername@login1 ~] python3 -m pip install --user .Se pip solleva un avviso…
pip potrebbe avvertire che i binari del pacchetto utente
non sono presenti nel PATH.
ATTENZIONE
WARNING: The script amdahl is installed in "${HOME}/.local/bin" which is
not on PATH. Consider adding this directory to PATH or, if you prefer to
suppress this warning, use --no-warn-script-location.Per verificare se questo avviso rappresenta realmente un problema,
utilizzare which per cercare il programma
amdahl:
Se il comando non restituisce alcun risultato, visualizzando un nuovo
prompt, significa che il file amdahl non è stato trovato. È
necessario aggiornare la variabile d’ambiente denominata
PATH per includere la cartella mancante. Modificare il file
di configurazione della shell come segue, quindi disconnettersi dal
cluster e riaccenderlo in modo che abbia effetto.
OUTPUT
export PATH=${PATH}:${HOME}/.local/binDopo aver effettuato il login a cluster.hpc-carpentry.org,
which dovrebbe essere in grado di trovare
amdahl senza difficoltà. Se si è dovuto caricare un modulo
Python, caricarlo di nuovo.
Aiuto!
Molti programmi a riga di comando includono un messaggio di “aiuto”.
Provatelo con amdahl:
OUTPUT
usage: amdahl [-h] [-p [PARALLEL_PROPORTION]] [-w [WORK_SECONDS]] [-t] [-e] [-j [JITTER_PROPORTION]]
optional arguments:
-h, --help show this help message and exit
-p [PARALLEL_PROPORTION], --parallel-proportion [PARALLEL_PROPORTION]
Parallel proportion: a float between 0 and 1
-w [WORK_SECONDS], --work-seconds [WORK_SECONDS]
Total seconds of workload: an integer greater than 0
-t, --terse Format output as a machine-readable object for easier analysis
-e, --exact Exactly match requested timing by disabling random jitter
-j [JITTER_PROPORTION], --jitter-proportion [JITTER_PROPORTION]
Random jitter: a float between -1 and +1Questo messaggio non ci dice molto su ciò che il programma fa, ma ci dice i flag importanti che potremmo voler usare quando lo lanciamo.
Esecuzione del lavoro su un nodo di calcolo
Creare un file di presentazione, richiedere un task su un singolo nodo e lanciarlo.
BASH
#!/bin/bash
#SBATCH -J solo-job
#SBATCH -p cpubase_bycore_b1
#SBATCH -N 1
#SBATCH -n 1
# Caricare l'ambiente di cui abbiamo bisogno
module load Python
# Eseguirlo
amdahlCome in precedenza, utilizzare i comandi di stato Slurm per verificare se il lavoro è in esecuzione e quando termina:
Usare ls per localizzare il file di output. Il flag
-t ordina in ordine cronologico inverso: prima il più
recente. Qual era l’output?
L’output del cluster deve essere scritto in un file nella cartella da cui è stato lanciato il lavoro. Ad esempio,
OUTPUT
slurm-347087.out serial-job.sh amdahl README.md LICENSE.txtOUTPUT
Doing 30.000 seconds of 'work' on 1 processor,
which should take 30.000 seconds with 0.850 parallel proportion of the workload.
Hello, World! I am process 0 of 1 on smnode1. I will do all the serial 'work' for 4.500 seconds.
Hello, World! I am process 0 of 1 on smnode1. I will do parallel 'work' for 25.500 seconds.
Total execution time (according to rank 0): 30.033 secondsCome abbiamo visto in precedenza, due dei parametri del programma
amdahl impostano la quantità di lavoro e la proporzione di
tale lavoro che è di natura parallela. In base all’output, possiamo
vedere che il codice utilizza un valore predefinito di 30 secondi di
lavoro parallelo all’85%. Il programma ha funzionato per poco più di 30
secondi in totale e, se facciamo i conti, è vero che il 15% è stato
contrassegnato come ‘seriale’ e l’85% come ‘parallelo’.
Poiché abbiamo dato al lavoro una sola CPU, questo lavoro non è stato veramente eseguito in parallelo: lo stesso processore ha eseguito il lavoro ‘seriale’ per 4,5 secondi, poi la parte ‘parallela’ per 25,5 secondi, e non è stato risparmiato tempo. Il cluster può fare di meglio, se lo chiediamo.
Esecuzione del lavoro in parallelo
Il programma amdahl utilizza la Message Passing
Interface (MPI) per il parallelismo, uno strumento comune nei sistemi
HPC.
Cos’è MPI?
L’interfaccia per il passaggio di messaggi è un insieme di strumenti che consentono a più task in esecuzione simultanea di comunicare tra loro. In genere, un singolo eseguibile viene eseguito più volte, eventualmente su macchine diverse, e gli strumenti MPI vengono utilizzati per informare ogni istanza dell’eseguibile sui suoi processi fratelli e su quale istanza sia. MPI fornisce anche strumenti per consentire la comunicazione tra le istanze per coordinare il lavoro, scambiare informazioni su elementi dell’attività o trasferire dati. Un’istanza MPI ha tipicamente una propria copia di tutte le variabili locali.
Mentre gli eseguibili MPI-aware possono generalmente essere eseguiti
come programmi autonomi, per poter essere eseguiti in parallelo devono
utilizzare un ambiente di esecuzione MPI, che è
un’implementazione specifica dello standard MPI. Per attivare
l’ambiente MPI, il programma deve essere avviato con un comando come
mpiexec (o mpirun, o srun, ecc. a
seconda del run-time MPI da utilizzare), che garantirà l’inclusione del
supporto run-time appropriato per il parallelismo.
Argomenti di runtime MPI
Di per sé, comandi come mpiexec possono accettare molti
argomenti che specificano quante macchine parteciperanno all’esecuzione,
e potrebbero essere necessari se si desidera eseguire un programma MPI
da soli (ad esempio, sul proprio portatile). Nel contesto di un sistema
di accodamento, tuttavia, è frequente che il run-time MPI ottenga i
parametri necessari dal sistema di accodamento, esaminando le variabili
d’ambiente impostate al momento del lancio del lavoro.
Modifichiamo lo script del lavoro per richiedere più core e utilizzare il run-time MPI.
BASH
[yourUsername@login1 ~] cp serial-job.sh parallel-job.sh
[yourUsername@login1 ~] nano parallel-job.sh
[yourUsername@login1 ~] cat parallel-job.shBASH
#!/bin/bash
#SBATCH -J parallel-job
#SBATCH -p cpubase_bycore_b1
#SBATCH -N 1
#SBATCH -n 4
# Carica l'ambiente di cui abbiamo bisogno
# (mpi4py and numpy are in SciPy-bundle)
module load Python
module load SciPy-bundle
# Lo esegue
mpiexec amdahlSubito dopo inviare il lavoro. Si noti che il comando di invio non è cambiato rispetto a come abbiamo inviato il lavoro seriale: tutte le impostazioni parallele sono nel file batch anziché nella riga di comando.
Come in precedenza, utilizzare i comandi di stato per verificare l’esecuzione del lavoro.
OUTPUT
slurm-347178.out parallel-job.sh slurm-347087.out serial-job.sh amdahl README.md LICENSE.txtOUTPUT
Doing 30.000 seconds of 'work' on 4 processors,
which should take 10.875 seconds with 0.850 parallel proportion of the workload.
Hello, World! I am process 0 of 4 on smnode1. I will do all the serial 'work' for 4.500 seconds.
Hello, World! I am process 2 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Hello, World! I am process 1 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Hello, World! I am process 3 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Hello, World! I am process 0 of 4 on smnode1. I will do parallel 'work' for 6.375 seconds.
Total execution time (according to rank 0): 10.888 secondsÈ 4 volte più veloce?
Il lavoro parallelo ha ricevuto 4 volte più processori del lavoro seriale: significa che è stato completato in ¼ del tempo?
Il lavoro parallelo ha richiesto meno tempo: 11 secondi sono meglio di 30! Ma è solo un miglioramento di 2,7 volte, non di 4 volte.
Guardate l’output del lavoro:
- Mentre il “processo 0” svolgeva il lavoro seriale, i processi da 1 a 3 svolgevano il lavoro parallelo.
- Mentre il processo 0 ha recuperato il suo lavoro parallelo, gli altri non hanno fatto nulla.
Il processo 0 deve sempre terminare il suo compito seriale prima di poter iniziare il lavoro parallelo. In questo modo si stabilisce un limite inferiore alla quantità di tempo che questo lavoro richiederà, indipendentemente dal numero di core.
Questo è il principio di base della legge di Amdahl, che è un modo per prevedere miglioramenti nel tempo di esecuzione per un carico di lavoro fisso che può essere suddiviso ed eseguito in parallelo in una certa misura.
Quanto migliora le prestazioni l’esecuzione parallela?
In teoria, dividere un calcolo perfettamente parallelo tra n processi MPI dovrebbe produrre una diminuzione del tempo di esecuzione totale di un fattore n. Come abbiamo appena visto, i programmi reali hanno bisogno di un po’ di tempo per far comunicare e coordinare i processi MPI, e alcuni tipi di calcoli non possono essere suddivisi: vengono eseguiti efficacemente solo su una singola CPU.
Inoltre, se i processi MPI operano su diverse CPU fisiche del computer o su più nodi di calcolo, la comunicazione richiede ancora più tempo di quello necessario quando tutti i processi operano su una singola CPU.
In pratica, è comune valutare il parallelismo di un programma MPI mediante
- esecuzione del programma su un intervallo di CPU,
- registrazione del tempo di esecuzione per ogni esecuzione,
- confrontando ogni tempo di esecuzione con il tempo di utilizzo di una singola CPU.
Poiché “di più è meglio” - il miglioramento è più facile da interpretare dall’aumento di una certa quantità piuttosto che dalla sua diminuzione - i confronti vengono fatti usando il fattore di accelerazione S, che è calcolato come il tempo di esecuzione a singola CPU diviso per il tempo di esecuzione a più CPU. Per un programma perfettamente parallelo, un grafico dello speedup S in funzione del numero di CPU n darebbe una linea retta, S = n.
Eseguiamo un altro lavoro, per vedere quanto si avvicina a una linea
retta il nostro codice amdahl.
BASH
#!/bin/bash
#SBATCH -J parallel-job
#SBATCH -p cpubase_bycore_b1
#SBATCH -N 1
#SBATCH -n 8
# Caricare l'ambiente di cui abbiamo bisogno
# (mpi4py and numpy are in SciPy-bundle)
module load Python
module load SciPy-bundle
# Eseguirlo
mpiexec amdahlQuindi inviare il lavoro. Si noti che il comando di invio non è cambiato rispetto a come abbiamo inviato il lavoro seriale: tutte le impostazioni parallele sono nel file batch anziché nella riga di comando.
Come in precedenza, utilizzare i comandi di stato per verificare l’esecuzione del lavoro.
OUTPUT
slurm-347271.out parallel-job.sh slurm-347178.out slurm-347087.out serial-job.sh amdahl README.md LICENSE.txtOUTPUT
which should take 7.688 seconds with 0.850 parallel proportion of the workload.
Hello, World! I am process 4 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 0 of 8 on smnode1. I will do all the serial 'work' for 4.500 seconds.
Hello, World! I am process 2 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 1 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 3 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 5 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 6 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 7 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Hello, World! I am process 0 of 8 on smnode1. I will do parallel 'work' for 3.188 seconds.
Total execution time (according to rank 0): 7.697 secondsUscita non lineare
Quando abbiamo eseguito il lavoro con 4 lavoratori paralleli, il lavoro seriale ha scritto il suo output per primo, poi i processi paralleli hanno scritto il loro output, con il processo 0 che è arrivato per primo e per ultimo.
Con 8 worker, questo non è il caso: poiché i worker paralleli richiedono meno tempo del lavoro seriale, è difficile dire quale processo scriverà per primo il suo output, tranne che non sarà il processo 0!
Riassumiamo ora il tempo di esecuzione di ciascun lavoro:
| Number of CPUs | Runtime (sec) |
|---|---|
| 1 | 30.033 |
| 4 | 10.888 |
| 8 | 7.697 |
Quindi, utilizzare la prima riga per calcolare gli speedup \(S\), utilizzando Python come calcolatore a riga di comando e la formula
\[ S(t_{n}) = \frac{t_{1}}{t_{n}} \]
| Number of CPUs | Speedup | Ideal |
|---|---|---|
| 1 | 1.0 | 1 |
| 4 | 2.75 | 4 |
| 8 | 3.90 | 8 |
I file di output del lavoro ci dicono che questo programma esegue l’85% del suo lavoro in parallelo, lasciando il 15% all’esecuzione seriale. Questo dato sembra ragionevolmente alto, ma il nostro rapido studio dello speedup mostra che per ottenere uno speedup 4×, dobbiamo usare 8 o 9 processori in parallelo. Nei programmi reali, il fattore di velocizzazione è influenzato da
- Progettazione della CPU
- Rete di comunicazione tra i nodi di calcolo
- Implementazioni della libreria MPI
- Dettagli del programma MPI stesso
Utilizzando la legge di Amdahl, è possibile dimostrare che con questo programma è impossibile raggiungere una velocità di 8 volte, indipendentemente dal numero di processori disponibili. I dettagli di questa analisi, con i risultati a supporto, sono lasciati per la prossima lezione del workshop HPC Carpentry, Flussi di lavoro HPC.
In un ambiente HPC si cerca di ridurre il tempo di esecuzione di tutti i tipi di lavoro e MPI è un modo estremamente comune per combinare decine, centinaia o migliaia di CPU nella risoluzione di un singolo problema. Per saperne di più sulla parallelizzazione, vedere la lezione [lezione parallela per principianti][lezione parallela per principianti].
- La programmazione parallela consente alle applicazioni di sfruttare l’hardware parallelo.
- Il sistema di accodamento facilita l’esecuzione di compiti paralleli.
- I miglioramenti delle prestazioni derivanti dall’esecuzione parallela non hanno una scala lineare.
Content from Usare le risorse in modo efficace
Ultimo aggiornamento il 2026-02-26 | Modifica questa pagina
Panoramica
Domande
- Come posso rivedere i lavori eseguiti in passato?
- Come posso utilizzare queste conoscenze per creare uno script di invio più accurato?
Obiettivi
- Consultare le statistiche.
- Fare richieste di risorse più accurate negli script di lavoro in base ai dati che descrivono le prestazioni passate.
Abbiamo toccato tutte le competenze necessarie per interagire con un cluster HPC: accesso tramite SSH, caricamento di moduli software, invio di lavori paralleli e ricerca dell’output. Ora impariamo a stimare l’utilizzo delle risorse e perché potrebbe essere importante.
Stima delle risorse necessarie con lo scheduler
Anche se prima abbiamo affrontato la richiesta di risorse allo scheduler con il codice π, come facciamo a sapere di che tipo di risorse avrà bisogno il software e la sua richiesta per ciascuna di esse? In generale, a meno che la documentazione del software o le testimonianze degli utenti non forniscano qualche idea, non sapremo di quanta memoria o tempo di calcolo avrà bisogno un programma.
Leggi la documentazione
La maggior parte delle strutture HPC conserva la documentazione in forma di wiki, sito web o documento inviato al momento della registrazione di un account. Date un’occhiata a queste risorse e cercate il software che intendete usare: qualcuno potrebbe aver scritto una guida per ottenere il massimo da esso.
Un modo comodo per capire quali risorse sono necessarie perché un
lavoro venga eseguito con successo è quello di inviare un lavoro di
prova e poi chiedere allo scheduler il suo impatto usando
sacct -u yourUsername. Si può usare questa conoscenza per
impostare il lavoro successivo con una stima più precisa del suo carico
sul sistema. Una buona regola generale è quella di chiedere allo
schedulatore dal 20% al 30% di tempo e memoria in più rispetto a quanto
si prevede che il lavoro richieda. In questo modo si garantisce che
piccole fluttuazioni nel tempo di esecuzione o nell’uso della memoria
non comportino l’annullamento del lavoro da parte dello schedulatore.
Tenete presente che se chiedete troppo, il vostro lavoro potrebbe non
essere eseguito anche se le risorse disponibili sono sufficienti, perché
lo schedulatore aspetterà che i lavori degli altri finiscano e liberino
le risorse necessarie per soddisfare la vostra richiesta.
Statistiche
Poiché abbiamo già inviato amdahl per l’esecuzione sul
cluster, possiamo interrogare lo scheduler per vedere quanto tempo ha
impiegato il nostro lavoro e quali risorse sono state utilizzate.
Useremo sacct -u yourUsername per ottenere le statistiche
su parallel-job.sh.
OUTPUT
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
7 file.sh cpubase_b+ def-spons+ 1 COMPLETED 0:0
7.batch batch def-spons+ 1 COMPLETED 0:0
7.extern extern def-spons+ 1 COMPLETED 0:0
8 file.sh cpubase_b+ def-spons+ 1 COMPLETED 0:0
8.batch batch def-spons+ 1 COMPLETED 0:0
8.extern extern def-spons+ 1 COMPLETED 0:0
9 example-j+ cpubase_b+ def-spons+ 1 COMPLETED 0:0
9.batch batch def-spons+ 1 COMPLETED 0:0
9.extern extern def-spons+ 1 COMPLETED 0:0Questo mostra tutti i lavori eseguiti nella giornata (si noti che ci sono più voci per ogni lavoro). Per ottenere informazioni su un lavoro specifico (ad esempio, 347087), si cambia leggermente il comando.
Questo mostrerà molte informazioni; in effetti, ogni singola
informazione raccolta sul lavoro dallo schedulatore apparirà qui. Può
essere utile reindirizzare queste informazioni a less per
facilitarne la visualizzazione (usare i tasti freccia sinistra e destra
per scorrere i campi).
Discussione
Questa vista può aiutare a confrontare la quantità di tempo richiesta ed effettivamente utilizzata, la durata della permanenza nella coda prima del lancio e l’impronta di memoria sui nodi di calcolo.
Quanto sono state accurate le nostre stime?
Miglioramento delle richieste di risorse
Dalla cronologia dei lavori, vediamo che i lavori amdahl
hanno terminato l’esecuzione in pochi minuti. La stima del tempo fornita
nello script del lavoro era troppo lunga! Questo rende più difficile per
il sistema di accodamento stimare con precisione quando le risorse si
libereranno per altri lavori. In pratica, questo significa che il
sistema di accodamento aspetta a inviare il nostro lavoro
amdahl fino a quando non si apre l’intera fascia oraria
richiesta, invece di “intrufolarsi” in una finestra molto più breve in
cui il lavoro potrebbe effettivamente terminare. Specificando con
maggiore precisione il tempo di esecuzione previsto nello script di
invio, si può contribuire ad alleviare la congestione del cluster e a
far sì che il lavoro venga inviato prima.
Restringere la stima del tempo
Modificare parallel_job.sh per impostare una stima
migliore del tempo. Quanto ci si può avvicinare?
Suggerimento: usare -t.
- Dei comandi accurati aiutano il sistema di accodamento ad allocare in modo efficiente le risorse condivise.
Content from Usare le risorse condivise in modo responsabile
Ultimo aggiornamento il 2026-02-26 | Modifica questa pagina
Panoramica
Domande
- Come posso essere un utente responsabile?
- Come posso proteggere i miei dati?
- Come posso ottenere grandi quantità di dati da un sistema HPC?
Obiettivi
- Descrivere come le azioni di un singolo utente possono influenzare l’esperienza degli altri su un sistema condiviso.
- Discutere il comportamento di un utente premuroso del sistema condiviso.
- Spiegare l’importanza del backup dei dati critici.
- Descrivere le sfide legate al trasferimento di grandi quantità di dati dai sistemi HPC.
- Convertire molti file in un singolo file di archivio usando tar.
Una delle principali differenze tra l’uso di risorse HPC remote e il proprio sistema (ad esempio il portatile) è che le risorse remote sono condivise. Il numero di utenti tra i quali la risorsa è condivisa varia da sistema a sistema, ma è improbabile che siate l’unico utente connesso o che utilizzi un sistema di questo tipo.
L’uso diffuso di sistemi di schedulazione in cui gli utenti inviano lavori su risorse HPC è un risultato naturale della natura condivisa di queste risorse. Ci sono altre cose che, in quanto membri responsabili della comunità, dovete considerare.
Sii gentile con i nodi di accesso
Il nodo di login è spesso impegnato a gestire tutti gli utenti connessi, a creare e modificare file e a compilare software. Se la macchina esaurisce la memoria o la capacità di elaborazione, diventa molto lenta e inutilizzabile per tutti. Sebbene la macchina sia destinata a essere utilizzata, assicuratevi di farlo in modo responsabile, ovvero senza influire negativamente sull’esperienza degli altri utenti.
I nodi di accesso sono sempre il posto giusto per lanciare i lavori. Le politiche dei cluster variano, ma possono anche essere usati per provare i flussi di lavoro e, in alcuni casi, possono ospitare strumenti avanzati di debug o di sviluppo specifici per il cluster. Il cluster può avere moduli che devono essere caricati, magari in un certo ordine, e percorsi o versioni di librerie che differiscono dal vostro portatile; fare un test interattivo sul nodo principale è un modo rapido e affidabile per scoprire e risolvere questi problemi.
I nodi di login sono una risorsa condivisa
Ricordate che il nodo di login è condiviso con tutti gli altri utenti e le vostre azioni potrebbero causare problemi ad altre persone. Pensate bene alle potenziali implicazioni dell’emissione di comandi che possono utilizzare grandi quantità di risorse.
Non siete sicuri? Chiedete al vostro amministratore di sistema (“sysadmin”) se la cosa che state pensando di fare è adatta al nodo di login, o se c’è un altro meccanismo per farlo in modo sicuro.
È sempre possibile usare i comandi top e
ps ux per elencare i processi in esecuzione sul nodo di
accesso, insieme alla quantità di CPU e memoria che stanno utilizzando.
Se questo controllo rivela che il nodo di login è inattivo, si può
tranquillamente usarlo per le attività di elaborazione non routinarie.
Se qualcosa va storto (il processo impiega troppo tempo o non risponde),
si può usare il comando kill insieme al PID per
terminare il processo.
“Galateo” del nodo di accesso
Quale di questi comandi sarebbe un’operazione di routine da eseguire sul nodo di login?
python physics_sim.pymakecreate_directories.shmolecular_dynamics_2tar -xzf R-3.3.0.tar.gz
La creazione di software, la creazione di cartelle e il
disimballaggio di software sono compiti comuni e accettabili per il nodo
di login: le opzioni #2 (make), #3 (mkdir) e
#5 (tar) probabilmente vanno bene. Si noti che i nomi degli
script non sempre riflettono il loro contenuto: prima di lanciare il #3,
si consiglia di usare less create_directories.sh e
assicurarsi che non sia un virus o “troian horse”
L’esecuzione di applicazioni ad alta intensità di risorse è
sconsigliata. A meno che non siate sicuri che non influisca sugli altri
utenti, non eseguite lavori come il #1 (python) o il #4
(codice MD personalizzato). Se non si è sicuri, meglio chiedere
consiglio all’amministratore di sistema.
Se si riscontrano problemi di prestazioni con un nodo di login, è necessario segnalarlo all’amministratore di sistema (di solito tramite l’helpdesk) affinché indaghi.
Test prima di scalare
Ricordate che in genere l’utilizzo dei sistemi condivisi ha un costo. Un semplice errore in uno script di lavoro può finire per costare una grande quantità di budget di risorse. Immaginate uno script di lavoro con un errore che lo fa stare fermo per 24 ore su 1000 core o uno in cui avete richiesto per errore 2000 core e ne usate solo 100! Questo problema può essere aggravato quando si scrivono script che automatizzano l’invio di lavori (ad esempio, quando si esegue lo stesso calcolo o analisi su molti parametri o file diversi). Quando ciò accade, si danneggia sia l’utente (che spreca molte risorse caricate) sia gli altri utenti (che sono bloccati dall’accesso ai nodi di calcolo inattivi). Su risorse molto trafficate, potreste aspettare molti giorni in coda e il vostro lavoro potrebbe fallire entro 10 secondi dall’avvio a causa di un banale errore di battitura nello script del lavoro. Questo è estremamente frustrante!
La maggior parte dei sistemi fornisce risorse dedicate ai test con tempi di attesa brevi per evitare questo problema.
Test degli script di invio dei lavori che utilizzano grandi quantità di risorse
Prima di inviare un’ampia serie di lavori, inviarne uno come test per assicurarsi che tutto funzioni come previsto.
Prima di inviare un lavoro molto grande o molto lungo, eseguire un breve test troncato per assicurarsi che il lavoro venga avviato come previsto.
Avere sempre un backup
Sebbene molti sistemi HPC mantengano dei backup, questi non sempre coprono tutti i file system disponibili e possono servire solo per scopi di disaster recovery (cioè per ripristinare l’intero file system in caso di perdita piuttosto che un singolo file o una directory cancellati per errore). Proteggere i dati critici dalla corruzione o dall’eliminazione è una responsabilità primaria dell’utente: conservare le proprie copie di backup.
I sistemi di controllo delle versioni (come Git) hanno spesso offerte gratuite basate su cloud (ad esempio, GitHub e GitLab) che vengono generalmente utilizzate per archiviare il codice sorgente. Anche se non si scrivono programmi propri, questi sistemi possono essere molto utili per archiviare script di lavoro, script di analisi e piccoli file di input.
Se state progettando un software, potreste avere una grande quantità di codice sorgente che compilate per creare il vostro eseguibile. Poiché questi dati possono essere generalmente recuperati scaricando nuovamente il codice o eseguendo nuovamente l’operazione di checkout dal repository del codice sorgente, questi dati sono anche meno critici da proteggere.
Per le grandi quantità di dati, in particolare per i risultati
importanti delle esecuzioni, che possono essere insostituibili, è
necessario assicurarsi di disporre di un sistema robusto per prelevare
le copie dei dati dal sistema HPC, ove possibile, e trasferirle su uno
storage di backup. Strumenti come rsync possono essere
molto utili a questo scopo.
Il vostro accesso al sistema HPC condiviso sarà generalmente limitato nel tempo, quindi dovreste assicurarvi di avere un piano per trasferire i vostri dati dal sistema prima che il vostro accesso finisca. Il tempo necessario per trasferire grandi quantità di dati non deve essere sottovalutato e bisogna assicurarsi di averlo pianificato con sufficiente anticipo (idealmente, prima ancora di iniziare a usare il sistema per la propria ricerca).
In tutti questi casi, l’helpdesk del sistema in uso dovrebbe essere in grado di fornire indicazioni utili sulle opzioni di trasferimento dei dati per i volumi di dati da utilizzare.
I vostri dati sono sotto la vostra responsabilità
Assicuratevi di aver capito qual è la politica di backup sui file system del sistema che state usando e quali sono le implicazioni per il vostro lavoro se perdete i vostri dati sul sistema. Pianificate i backup dei dati critici e le modalità di trasferimento dei dati dal sistema durante il progetto.
Trasferimento dei dati
Come accennato in precedenza, molti utenti si trovano prima o poi a dover trasferire grandi quantità di dati dai sistemi HPC (è più frequente il caso di trasferimento di dati da un sistema all’altro che da un sistema all’altro, ma i consigli che seguono si applicano in entrambi i casi). La velocità di trasferimento dei dati può essere limitata da molti fattori diversi, quindi il miglior meccanismo di trasferimento dei dati da utilizzare dipende dal tipo di dati da trasferire e dalla loro destinazione.
I componenti tra la sorgente e la destinazione dei dati hanno livelli di prestazioni variabili e, in particolare, possono avere capacità diverse in termini di larghezza di banda e latenza.
La larghezza di banda è generalmente la quantità grezza di dati per unità di tempo che un dispositivo è in grado di trasmettere o ricevere. È una metrica comune e generalmente ben compresa.
La latenza è un po’ più sottile. Per i trasferimenti di dati, si può pensare che sia la quantità di tempo necessaria per far uscire i dati dalla memoria e portarli in una forma trasmissibile. I problemi di latenza sono il motivo per cui è consigliabile eseguire i trasferimenti di dati spostando un piccolo numero di file di grandi dimensioni, piuttosto che il contrario.
Alcuni dei componenti chiave e dei problemi ad essi associati sono:
- Velocità del disco: I file system dei sistemi HPC sono spesso altamente paralleli, costituiti da un numero molto elevato di unità disco ad alte prestazioni. Ciò consente loro di supportare una larghezza di banda dei dati molto elevata. A meno che il sistema remoto non abbia un file system parallelo simile, la velocità di trasferimento potrebbe essere limitata dalle prestazioni del disco.
- Prestazioni dei metadati: Le operazioni sui meta-dati, come l’apertura e la chiusura dei file o l’elenco del proprietario o delle dimensioni di un file, sono molto meno parallele delle operazioni di lettura/scrittura. Se i dati sono costituiti da un numero molto elevato di piccoli file, la velocità di trasferimento potrebbe essere limitata dalle operazioni sui meta-dati. Anche le operazioni sui meta-dati eseguite da altri utenti del sistema possono interagire fortemente con quelle eseguite dall’utente, per cui la riduzione del numero di tali operazioni (combinando più file in un unico file) può ridurre la variabilità della velocità di trasferimento e aumentarla.
- Velocità della rete: Le prestazioni di trasferimento dei dati possono essere limitate dalla velocità della rete. Soprattutto è limitata dalla sezione più lenta della rete tra la sorgente e la destinazione. Se si sta trasferendo al proprio portatile/alla propria postazione di lavoro, è probabile che si tratti della sua connessione (via LAN o WiFi).
- Velocità del firewall: La maggior parte delle reti moderne è protetta da una qualche forma di firewall che filtra il traffico dannoso. Questo filtraggio ha un certo overhead e può comportare una riduzione delle prestazioni di trasferimento dei dati. Le esigenze di una rete generica che ospita e-mail/web-server e computer desktop sono molto diverse da quelle di una rete di ricerca che deve supportare un elevato volume di trasferimenti di dati. Se si cerca di trasferire dati da o verso un host su una rete generica, è possibile che il firewall di quella rete limiti la velocità di trasferimento.
Come già detto, se si dispone di dati correlati che consistono in un
gran numero di piccoli file, si consiglia vivamente di impacchettare i
file in un file archivio più grande per l’archiviazione e il
trasferimento a lungo termine. Un singolo file di grandi dimensioni
consente di utilizzare in modo più efficiente il file system ed è più
facile da spostare, copiare e trasferire perché sono necessarie molte
meno operazioni sui metadati. I file di archivio possono essere creati
con strumenti come tar e zip. Abbiamo già
incontrato tar quando abbiamo parlato del trasferimento dei
dati.

Considerare il modo migliore per trasferire i dati
Se si trasferiscono grandi quantità di dati, è necessario pensare a cosa può influire sulle prestazioni del trasferimento. È sempre utile eseguire alcuni test da utilizzare per estrapolare il tempo necessario per trasferire i dati.
Supponiamo di avere una cartella “dati” contenente circa 10.000 file, un sano mix di dati ASCII e binari di piccole e grandi dimensioni. Quale dei seguenti è il modo migliore per trasferirli in HPC Carpentry’s Cloud Cluster?
scp -r data yourUsername@cluster.hpc-carpentry.org:~/rsync -ra data yourUsername@cluster.hpc-carpentry.org:~/rsync -raz data yourUsername@cluster.hpc-carpentry.org:~/-
tar -cvf data.tar data;rsync -raz data.tar yourUsername@cluster.hpc-carpentry.org:~/ -
tar -cvzf data.tar.gz data;rsync -ra data.tar.gz yourUsername@cluster.hpc-carpentry.org:~/
-
scpcopierà ricorsivamente la cartella. Funziona, ma senza compressione. -
rsync -rafunziona comescp -r, ma conserva le informazioni sui file, come i tempi di creazione. Questo è marginalmente migliore. -
rsync -razaggiunge la compressione, che farà risparmiare un po’ di larghezza di banda. Se si dispone di una CPU forte a entrambi i capi della linea e si è su una rete lenta, questa è una buona scelta. - Questo comando usa prima
tarper unire tutto in un unico file, poirsync -zper trasferirlo con la compressione. Con un numero così elevato di file, l’overhead dei metadati può ostacolare il trasferimento, quindi questa è una buona idea. - Questo usa
tar -zper comprimere l’archivio e poirsyncper trasferirlo. Le prestazioni sono simili a quelle del comando #4, ma nella maggior parte dei casi (per insiemi di dati di grandi dimensioni), è la migliore combinazione di alta velocità e bassa latenza (per sfruttare al meglio il tempo e la connessione di rete).
- Fare attenzione a come si usa il nodo login.
- I dati presenti sul sistema sono sotto la propria responsabilità.
- Pianificare e testare trasferimenti di dati di grandi dimensioni.
- Spesso è meglio convertire molti file in un singolo file di archivio prima di trasferirli.