Content from Laufen und Beenden
Zuletzt aktualisiert am 2025-10-30 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich Python-Programme ausführen?
Ziele
- Starten Sie den JupyterLab-Server.
- Erstellen Sie ein neues Python-Skript.
- Erstellen Sie ein Jupyter-Notizbuch.
- Fahren Sie den JupyterLab-Server herunter.
- Verstehen Sie den Unterschied zwischen einem Python-Skript und einem Jupyter-Notizbuch.
- Erstellen von Markdown-Zellen in einem Notizbuch.
- Erstellen und Ausführen von Python-Zellen in einem Notizbuch.
Um Python auszuführen, werden wir für den Rest dieses Workshops Jupyter Notebooks über JupyterLab verwenden. Jupyter Notebooks sind in den Bereichen Datenwissenschaft und Visualisierung weit verbreitet und dienen als praktischer gemeinsamer Nenner für die interaktive Ausführung von Python-Code, in dem wir die Ergebnisse unseres Python-Codes leicht ansehen und mit anderen teilen können.
Es gibt andere Möglichkeiten, Code zu bearbeiten, zu verwalten und auszuführen. Softwareentwickler verwenden häufig eine integrierte Entwicklungsumgebung (IDE) wie [PyCharm] (https://www.jetbrains.com/pycharm/) oder [Visual Studio Code] (https://code.visualstudio.com/) oder Texteditoren wie Vim oder Emacs, um ihre Python-Programme zu erstellen und zu bearbeiten. Nachdem Sie Ihre Python-Programme bearbeitet und gespeichert haben, können Sie diese Programme in der IDE selbst oder direkt auf der Kommandozeile ausführen. Im Gegensatz dazu können wir mit Jupyter-Notizbüchern die Ergebnisse unseres Python-Codes direkt im Notizbuch ausführen und betrachten.
JupyterLab hat mehrere andere praktische Funktionen:
- Sie können problemlos Codeblöcke eingeben, bearbeiten, kopieren und einfügen.
- Mit der Tab-Vervollständigung können Sie ganz einfach auf die Namen der von Ihnen verwendeten Elemente zugreifen und mehr darüber erfahren.
- Damit können Sie Ihren Code mit Links, Text in verschiedenen Größen, Aufzählungszeichen usw. versehen, um ihn für Sie und Ihre Mitarbeiter leichter zugänglich zu machen.
- Damit können Sie Zahlen neben dem Code, der sie erzeugt, anzeigen, um eine vollständige Geschichte der Analyse zu erzählen.
Jedes Notizbuch enthält eine oder mehrere Zellen, die Code, Text oder Bilder enthalten.
Erste Schritte mit JupyterLab
JupyterLab ist ein Anwendungsserver mit einer Web-Benutzeroberfläche von Projekt Jupyter, der es ermöglicht, mit Dokumenten und Aktivitäten wie Jupyter-Notizbüchern, Texteditoren, Terminals und sogar benutzerdefinierten Komponenten auf flexible, integrierte und erweiterbare Weise zu arbeiten. JupyterLab erfordert einen einigermaßen aktuellen Browser (idealerweise eine aktuelle Version von Chrome, Safari oder Firefox); Internet Explorer Versionen 9 und niedriger werden nicht unterstützt.
JupyterLab ist Teil der Anaconda Python Distribution. Wenn Sie die Anaconda-Python-Distribution noch nicht installiert haben, finden Sie in der Setup-Anleitung eine Installationsanleitung.
In dieser Lektion werden wir JupyterLab lokal auf unseren eigenen Rechnern laufen lassen, so dass außer der anfänglichen Verbindung zum Herunterladen und Installieren von Anaconda und JupyterLab keine Internetverbindung erforderlich ist
- Starten Sie den JupyterLab-Server auf Ihrem Rechner
- Verwenden Sie einen Webbrowser, um eine spezielle localhost URL zu öffnen, die eine Verbindung zu Ihrem JupyterLab Server herstellt
- Der JupyterLab-Server erledigt die Arbeit und der Webbrowser stellt das Ergebnis dar
- Geben Sie Code in den Browser ein und sehen Sie sich die Ergebnisse an, nachdem Ihr JupyterLab-Server die Ausführung Ihres Codes beendet hat
JupyterLab? Was ist mit Jupyter-Notebooks?
JupyterLab ist die nächste Entwicklungsstufe des Jupyter-Notebooks. Wenn Sie bereits Erfahrung mit Jupyter-Notizbüchern haben, dann haben Sie eine gute Vorstellung davon, was Sie von JupyterLab erwarten können.
Erfahrene Benutzer von Jupyter-Notizbüchern, die an einer ausführlicheren Diskussion der Ähnlichkeiten und Unterschiede zwischen den Benutzeroberflächen von JupyterLab und Jupyter-Notizbüchern interessiert sind, finden weitere Informationen in der JupyterLab user interface documentation.
Start von JupyterLab
Sie können den JupyterLab-Server über die Befehlszeile oder über eine
Anwendung namens Anaconda Navigator starten. Anaconda
Navigator ist Teil der Anaconda Python Distribution.
macOS - Befehlszeile
Um den JupyterLab-Server zu starten, müssen Sie über das Terminal auf die Befehlszeile zugreifen. Es gibt zwei Möglichkeiten, Terminal auf dem Mac zu öffnen.
- Öffnen Sie in Ihrem Anwendungsordner die Dienstprogramme und doppelklicken Sie auf Terminal
- Drücken Sie Befehl + Leertaste, um Spotlight
zu starten. Geben Sie
Terminalein und doppelklicken Sie dann auf das Suchergebnis oder drücken Sie Eingabe
Nachdem Sie Terminal gestartet haben, geben Sie den Befehl ein, um den JupyterLab-Server zu starten.
Windows-Benutzer - Befehlszeile
Um den JupyterLab-Server zu starten, müssen Sie auf die Anaconda-Eingabeaufforderung zugreifen.
Drücken Sie Windows Logo Key und suchen Sie nach
Anaconda Prompt, klicken Sie auf das Ergebnis oder drücken
Sie Enter.
Nachdem Sie die Anaconda-Eingabeaufforderung gestartet haben, geben Sie den Befehl ein:
Anaconda Navigator
Um einen JupyterLab-Server von Anaconda Navigator aus zu starten,
müssen Sie zuerst Anaconda
Navigator starten (klicken Sie hier für detaillierte Anweisungen für
macOS, Windows und Linux). Sie können Anaconda Navigator über
Spotlight auf macOS (Befehl + Leertaste), die
Windows-Suchfunktion (Windows-Logo-Taste) oder das Öffnen
einer Terminal-Shell und das Ausführen von
anaconda-navigator über die Kommandozeile suchen.
Nachdem Sie Anaconda Navigator gestartet haben, klicken Sie auf die
Schaltfläche Launch unter JupyterLab. Möglicherweise müssen
Sie nach unten scrollen, um sie zu finden.
Hier ist ein Screenshot einer Anaconda-Navigator-Seite, die der Seite ähnelt, die sich unter macOS oder Windows öffnen sollte.

Und hier ist ein Screenshot einer JupyterLab-Landingpage, die der Seite ähneln sollte, die sich in Ihrem Standard-Webbrowser öffnet, nachdem Sie den JupyterLab-Server unter macOS oder Windows gestartet haben.
Die JupyterLab-Schnittstelle
JupyterLab verfügt über viele Funktionen, die in traditionellen integrierten Entwicklungsumgebungen (IDEs) zu finden sind, konzentriert sich aber auf die Bereitstellung flexibler Bausteine für interaktives, forschendes Computing.
Die JupyterLab-Oberfläche besteht aus der Menüleiste, einer ausklappbaren linken Seitenleiste und dem Hauptarbeitsbereich, der Registerkarten mit Dokumenten und Aktivitäten enthält.
Menüleiste
Die Menüleiste am oberen Rand von JupyterLab enthält die Menüs der obersten Ebene, in denen verschiedene in JupyterLab verfügbare Aktionen zusammen mit den entsprechenden Tastenkombinationen (sofern zutreffend) angezeigt werden. Die folgenden Menüs sind standardmäßig enthalten.
- Datei: Aktionen im Zusammenhang mit Dateien und Verzeichnissen wie Neu, Öffnen, Schließen, Speichern, usw. Das Menü Datei enthält auch die Aktion Abschalten, mit der Sie den JupyterLab-Server herunterfahren können.
- Bearbeiten: Aktionen im Zusammenhang mit der Bearbeitung von Dokumenten und anderen Aktivitäten wie Rückgängig, Ausschneiden, Kopieren, Einfügen, usw.
- Ansicht: Aktionen, die das Aussehen von JupyterLab verändern.
- Ausführen: Aktionen zum Ausführen von Code in verschiedenen Aktivitäten wie Notizbüchern und Code-Konsolen (siehe unten).
- Kernel: Aktionen zur Verwaltung von Kerneln. Kernel in Jupyter werden weiter unten ausführlicher erklärt.
- Tabs: Eine Liste der geöffneten Dokumente und Aktivitäten im Hauptarbeitsbereich.
- Einstellungen: Allgemeine JupyterLab-Einstellungen können über dieses Menü konfiguriert werden. Es gibt auch eine Option Erweiterter Einstellungseditor im Dropdown-Menü, die eine feinere Steuerung der JupyterLab-Einstellungen und Konfigurationsoptionen ermöglicht.
- Hilfe: Eine Liste von JupyterLab- und Kernel-Hilfe-Links.
Kernel
Die JupyterLab [docs] (https://jupyterlab.readthedocs.io/en/stable/user/documents_kernels.html) definieren Kernel als “separate Prozesse, die vom Server gestartet werden und Ihren Code in verschiedenen Programmiersprachen und Umgebungen ausführen.” Wenn wir ein Jupyter Notebook öffnen, wird ein Kernel - ein Prozess - gestartet, der den Code ausführt. In dieser Lektion werden wir den Jupyter ipython-Kernel verwenden, mit dem wir Python 3-Code interaktiv ausführen können.
Die Verwendung anderer Jupyter-[Kernel für andere Programmiersprachen] (https://github.com/jupyter/jupyter/wiki/Jupyter-kernels) würde es uns ermöglichen, Code in anderen Programmiersprachen in derselben JupyterLab-Schnittstelle zu schreiben und auszuführen, wie R, Java, Julia, Ruby, JavaScript, Fortran, usw.
Ein Screenshot der Standard-Menüleiste finden Sie unten.

Linke Seitenleiste
Die linke Seitenleiste enthält eine Reihe von häufig verwendeten Registerkarten, wie z.B. einen Dateibrowser (der den Inhalt des Verzeichnisses anzeigt, in dem der JupyterLab-Server gestartet wurde), eine Liste der laufenden Kernel und Terminals, die Befehlspalette und eine Liste der geöffneten Registerkarten im Hauptarbeitsbereich. Nachfolgend finden Sie einen Screenshot der standardmäßigen linken Seitenleiste.
Die linke Seitenleiste kann durch Auswahl von “Linke Seitenleiste anzeigen” im Menü “Ansicht” oder durch Klicken auf die aktive Registerkarte der Seitenleiste ein- oder ausgeklappt werden.
Hauptarbeitsbereich
Der Hauptarbeitsbereich in JupyterLab ermöglicht es Ihnen, Dokumente (Notizbücher, Textdateien usw.) und andere Aktivitäten (Terminals, Codekonsolen usw.) in Tafeln mit Registerkarten anzuordnen, die in der Größe verändert oder unterteilt werden können. Nachstehend finden Sie einen Screenshot des standardmäßigen Hauptarbeitsbereichs.
Wenn Sie die Registerkarte “Launcher” nicht sehen, klicken Sie auf das blaue Pluszeichen unter den Menüs “Datei” und “Bearbeiten”, damit sie erscheint.
Ziehen Sie eine Registerkarte in die Mitte eines Registerkartenfeldes, um die Registerkarte in das Feld zu verschieben. Unterteilen Sie ein Registerkartenfeld, indem Sie eine Registerkarte nach links, rechts, oben oder unten in das Feld ziehen. Der Arbeitsbereich hat eine einzige aktuelle Aktivität. Die Registerkarte für die aktuelle Aktivität ist durch einen farbigen oberen Rand gekennzeichnet (standardmäßig blau).
Erstellen eines Python-Skripts
- Um mit dem Schreiben eines neuen Python-Programms zu beginnen,
klicken Sie auf das Textdatei-Symbol unter der Überschrift
Sonstiges auf der Registerkarte “Startprogramm” des
Hauptarbeitsbereichs.
- Sie können auch eine neue einfache Textdatei erstellen, indem Sie Neu -> Textdatei aus dem Menü Datei in der Menüleiste auswählen.
- Um diese einfache Textdatei in ein Python-Programm umzuwandeln,
wählen Sie die Aktion Datei speichern unter aus dem Menü
Datei in der Menüleiste und geben Sie Ihrer neuen Textdatei
einen Namen, der mit der Erweiterung
.pyendet.- Die Erweiterung
.pyzeigt jedem (auch dem Betriebssystem), dass diese Textdatei ein Python-Programm ist. - Dies ist eine Konvention, keine Vorschrift.
- Die Erweiterung
Erstellen eines Jupyter-Notebooks
Um ein neues Notebook zu öffnen, klicken Sie auf das Python 3-Symbol unter der Überschrift Notebook in der Registerkarte Launcher im Hauptarbeitsbereich. Sie können auch ein neues Notizbuch erstellen, indem Sie Neu -> Notizbuch aus dem Menü Datei in der Menüleiste wählen.
Zusätzliche Hinweise zu Jupyter-Notizbüchern.
- Notebookdateien haben die Erweiterung
.ipynb, um sie von reinen Python-Programmen zu unterscheiden. - Notizbücher können als Python-Skripte exportiert werden, die über die Befehlszeile ausgeführt werden können.
Nachfolgend sehen Sie einen Screenshot eines Jupyter-Notizbuchs, das in JupyterLab läuft. Wenn Sie an weiteren Details interessiert sind, dann schauen Sie in die offizielle Notebook-Dokumentation.
Wie wird es gespeichert?
- Die Notizbuchdatei ist in einem Format namens JSON gespeichert.
- Genau wie eine Webseite sieht das, was gespeichert wird, anders aus als das, was Sie in Ihrem Browser sehen.
- Aber dieses Format erlaubt es Jupyter, Quellcode, Text und Bilder in einer Datei zu mischen.
Anordnen von Dokumenten in Registerkartenfeldern
Im JupyterLab-Hauptarbeitsbereich können Sie Dokumente in Panels mit Registerkarten anordnen. Hier ist ein Beispiel aus der offiziellen Dokumentation.
Erstellen Sie zunächst eine Textdatei, eine Python-Konsole und ein Terminalfenster und ordnen Sie diese in drei Panels im Hauptarbeitsbereich an. Erstellen Sie als Nächstes ein Notizbuch, ein Terminalfenster und eine Textdatei und ordnen Sie diese in drei Bereichen im Hauptarbeitsbereich an. Erstellen Sie schließlich Ihre eigene Kombination von Bereichen und Registerkarten. Welche Kombination von Bereichen und Registerkarten ist Ihrer Meinung nach für Ihren Arbeitsablauf am nützlichsten?
Nachdem Sie die erforderlichen Registerkarten erstellt haben, können Sie eine der Registerkarten in die Mitte eines Bereichs ziehen, um die Registerkarte in den Bereich zu verschieben; anschließend können Sie einen Registerkartenbereich unterteilen, indem Sie eine Registerkarte nach links, rechts, oben oder unten in den Bereich ziehen.
Code vs. Text
Jupyter mischt Code und Text in verschiedenen Arten von Blöcken, den sogenannten Zellen. Wir verwenden den Begriff “Code” oft für “den Quellcode von Software, die in einer Sprache wie Python geschrieben wurde”. Eine “Codezelle” in einem Notizbuch ist eine Zelle, die Software enthält; eine “Textzelle” ist eine Zelle, die normale, für Menschen geschriebene Prosa enthält.
Das Notebook hat einen Befehls- und einen Bearbeitungsmodus.
- Wenn Sie abwechselnd Esc und Return drücken, ändert sich der äußere Rand Ihrer Codezelle von grau zu blau.
- Dies sind die Modi Befehl (grau) und Bearbeiten (blau) Ihres Notizbuchs.
- Im Befehlsmodus können Sie Funktionen auf Notizbuchebene bearbeiten, im Bearbeitungsmodus ändern Sie den Inhalt der Zellen.
- Im Befehlsmodus (esc/gray),
- Mit der Taste b wird eine neue Zelle unter der aktuell ausgewählten Zelle erstellt.
- Mit der Taste a können Sie die obige Kombination erstellen.
- Mit der Taste x wird die aktuelle Zelle gelöscht.
- Mit der Taste z können Sie die letzte Operation in einer Zelle rückgängig machen (z. B. Löschen, Erstellen usw.).
- Alle Aktionen können über die Menüs ausgeführt werden, aber es gibt viele Tastenkombinationen, um die Arbeit zu beschleunigen.
Befehl vs. Bearbeiten
Befinden Sie sich auf der Seite des Jupyter-Notizbuchs gerade im
Befehls- oder im Bearbeitungsmodus?
Wechseln Sie zwischen den beiden Modi. Verwenden Sie die
Tastenkombinationen, um eine neue Zelle zu erstellen. Verwenden Sie die
Tastenkombinationen, um eine Zelle zu löschen. Verwenden Sie die
Tastenkombinationen, um die zuletzt durchgeführte Zellenoperation
rückgängig zu machen.
Der Befehlsmodus hat einen grauen Rahmen und der Bearbeitungsmodus einen blauen Rahmen. Verwenden Sie Esc und Return, um zwischen den Modi zu wechseln. Sie müssen sich im Befehlsmodus befinden (drücken Sie Esc, wenn Ihre Zelle blau ist). Tippen Sie b oder a. Sie müssen sich im Befehlsmodus befinden (drücken Sie Esc, wenn Ihre Zelle blau ist). Tippen Sie x. Du musst dich im Befehlsmodus befinden (drücke Esc, wenn deine Zelle blau ist). Tippe z.
Verwenden Sie die Tastatur und die Maus, um Zellen auszuwählen und zu bearbeiten.
- Wenn Sie die Return-Taste drücken, wird der Rahmen blau und der Bearbeitungsmodus wird aktiviert, so dass Sie innerhalb der Zelle schreiben können.
- Da wir in der Lage sein wollen, viele Codezeilen in einer einzigen Zelle zu schreiben, bewegt das Drücken der Return-Taste im Bearbeitungsmodus (blau) den Cursor zur nächsten Zeile in der Zelle, wie in einem Texteditor.
- Wir brauchen einen anderen Weg, um dem Notebook mitzuteilen, dass wir das, was in der Zelle steht, ausführen wollen.
- Durch gleichzeitiges Drücken von Shift+Return wird der Inhalt der Zelle ausgeführt.
- Beachten Sie, dass die Tasten Return und Shift auf der rechten Seite der Tastatur direkt nebeneinander liegen.
Das Notebook verwandelt Markdown in eine hübsch gedruckte Dokumentation.
- Notebooks können auch Markdown wiedergeben.
- Ein einfaches Klartextformat zum Schreiben von Listen, Links und anderen Dingen, die auf eine Webseite gehören könnten.
- Entspricht einer Teilmenge von HTML, die so aussieht, wie man sie in einer altmodischen E-Mail verschicken würde.
- Verwandeln Sie die aktuelle Zelle in eine Markdown-Zelle, indem Sie den Befehlsmodus (Esc/grau) aufrufen und die Taste M drücken.
-
In [ ]:wird verschwinden, um zu zeigen, dass es sich nicht mehr um eine Codezelle handelt und Sie in Markdown schreiben können. - Verwandeln Sie die aktuelle Zelle in eine Codezelle, indem Sie den Befehlsmodus (Esc/grau) aufrufen und die Taste y drücken.
Markdown macht das meiste von dem, was HTML macht.
Tabelle: Zeigt eine Markdown-Syntax und ihre gerenderte Ausgabe.
+—————————————+————————————————+ | Markdown-Code | Gerenderte Ausgabe |
+=======================================+================================================+
+—————————————+————————————————+ |
| <p></p> | | * Verwende Sternchen | - Verwende Sternchen | | * um | - um | | * Aufzählungslisten zu erstellen. | - Aufzählungslisten zu erstellen. | |
| | +—————————————+————————————————+ +—————————————+————————————————+ |
| <p></p> | | 1. Verwende Zahlen | 1. Verwende Zahlen | | 1. um | 2. um | | 1. nummerierte Listen zu erstellen. | 3. nummerierte Listen zu erstellen. | |
| | +—————————————+————————————————+ +—————————————+————————————————+ |
| <p></p> | | * Du kannst Einrückungen verwenden | - Du kannst Einrückungen verwenden | | * Um Unterlisten zu erstellen | - Um Unterlisten zu erstellen | | * desselben Typs | - desselben Typs | | * Oder Unterlisten | - Oder Unterlisten | | 1. eines anderen | 1. eines anderen | | 1. Typs | 2. Typs | |
| | +—————————————+————————————————+ +—————————————+————————————————+ |
| <p></p> | | # Eine Überschrift der Ebene 1 | ## Eine Überschrift der Ebene 1 | |
| | +—————————————+————————————————+ +—————————————+————————————————+ |
| <p></p> | | ## Eine Überschrift der Ebene 2 (usw.)| ### Eine Überschrift der Ebene 2 (usw.) | |
| | +—————————————+————————————————+ +—————————————+————————————————+ |
| <p></p> | | Zeilenumbrüche | Zeilenumbrüche | | spielen keine Rolle. | spielen keine Rolle. | | | | | Aber Leerzeilen | Aber Leerzeilen | | erzeugen neue Absätze. | erzeugen neue Absätze. | |
| | +—————————————+————————————————+ +—————————————+————————————————+ |
| <p></p> | | [Links](http://software-carpentry.org)| [Links](https://software-carpentry.org) | | werden mit `[...](...)` erstellt. | werden mit `[...](...)` erstellt. | | Oder verwende [benannte Links][data-carp]. | Oder verwende [benannte Links][data_carpentry]. | | | | | [data-carp]: http://datacarpentry.org | | |
| | +—————————————+————————————————+
Erstellen von Listen in Markdown
Erstellen Sie eine verschachtelte Liste in einer Markdown-Zelle in einem Notizbuch, die wie folgt aussieht:
- Finanzierung erhalten.
- Arbeiten Sie.
- Entwurfsexperiment.
- Daten sammeln.
- Analysieren.
- Schreiben Sie.
- Veröffentlichen.
Diese Aufgabe integriert sowohl die nummerierte Liste als auch die Aufzählungsliste. Beachten Sie, dass die Aufzählungsliste um 2 Leerzeichen eingerückt ist, so dass sie mit den Elementen der nummerierten Liste übereinstimmt.
1. Get funding.
2. Do work.
* Design experiment.
* Collect data.
* Analyze.
3. Write up.
4. Publish.Vorhandene Zelle von Code in Markdown ändern
Was passiert, wenn Sie etwas Python in eine Codezelle schreiben und dann in eine Markdown-Zelle wechseln? Geben Sie zum Beispiel Folgendes in eine Code-Zelle ein:
Und dann führen Sie es mit Shift+Return aus, um sicherzustellen, dass es als Codezelle funktioniert. Gehen Sie nun zurück zu der Zelle und verwenden Sie Esc und dann m, um die Zelle in Markdown umzuwandeln und sie mit Shift+Return “auszuführen”. Was ist passiert und wie könnte dies nützlich sein?
Gleichungen
Standard Markdown (wie wir es für diese Notizen verwenden) kann keine Gleichungen darstellen, aber das Notebook schon. Erstellen Sie eine neue Markdown-Zelle und geben Sie Folgendes ein:
$\sum_{i=1}^{N} 2^{-i} \approx 1$(Es ist wahrscheinlich einfacher, zu kopieren und einzufügen.) Was
wird dort angezeigt? Was denken Sie, was der Unterstrich,
_, der Zirkumflex, ^, und das Dollarzeichen,
$, bedeuten?
Das Notizbuch zeigt die Gleichung so, wie sie in der
LaTeX-Gleichungssyntax dargestellt werden würde. Das Dollarzeichen,
$, wird verwendet, um Markdown mitzuteilen, dass der Text
dazwischen eine LaTeX-Gleichung ist. Wenn Sie mit LaTeX nicht vertraut
sind, wird der Unterstrich, _, für tiefgestellte Zeichen
und der Zirkumflex, ^, für hochgestellte Zeichen verwendet.
Ein Paar geschweifter Klammern, { und }, wird
verwendet, um Text zusammenzufassen, so dass die Anweisung
i=1 zum tiefgestellten und N zum
hochgestellten Zeichen wird. In ähnlicher Weise steht -i in
geschweiften Klammern, um die gesamte Anweisung zum hochgestellten
Zeichen für 2 zu machen.\sum und
\approx sind LaTeX-Befehle für “Summe über” und
“Näherungswert” Symbole.
Schließen von JupyterLab
- Wählen Sie in der Menüleiste das Menü “Datei” und wählen Sie dann unten im Dropdown-Menü “Herunterfahren”. Sie werden aufgefordert, zu bestätigen, dass Sie den JupyterLab-Server herunterfahren möchten (vergessen Sie nicht, Ihre Arbeit zu speichern!). Klicken Sie auf “Herunterfahren”, um den JupyterLab-Server herunterzufahren.
- Um den JupyterLab-Server neu zu starten, müssen Sie den folgenden Befehl von einer Shell aus erneut ausführen.
$ jupyter labSchließen von JupyterLab
Üben Sie das Schließen und Neustarten des JupyterLab-Servers.
- Python-Skripte sind reine Textdateien.
- Verwenden Sie das Jupyter-Notebook für die Bearbeitung und Ausführung von Python.
- Das Notebook hat einen Befehls- und einen Bearbeitungsmodus.
- Verwenden Sie die Tastatur und die Maus, um Zellen auszuwählen und zu bearbeiten.
- Das Notebook verwandelt Markdown in eine hübsch gedruckte Dokumentation.
- Markdown macht das meiste von dem, was HTML macht.
Content from Variablen und Zuweisungen
Zuletzt aktualisiert am 2025-03-02 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich Daten in Programmen speichern?
Ziele
- Schreibe Programme, die Variablen skalare Werte zuweisen und mit diesen Werten Berechnungen durchführen.
- Korrektes Verfolgen von Wertänderungen in Programmen, die skalare Zuweisungen verwenden.
Verwenden Sie Variablen, um Werte zu speichern.
Variablen sind Namen für Werte.
-
Variablennamen
- kann nur Buchstaben, Ziffern und den Unterstrich
_enthalten (typischerweise verwendet, um Wörter in langen Variablennamen zu trennen) - darf nicht mit einer Ziffer beginnen
- sind groß-klein-klein (Alter, Alter und AGE sind drei verschiedene Variablen)
- kann nur Buchstaben, Ziffern und den Unterstrich
Der Name sollte auch aussagekräftig sein, damit Sie oder ein anderer Programmierer wissen, worum es sich handelt
Variablennamen, die mit Unterstrichen beginnen, wie z.B.
__alistairs_real_age, haben eine besondere Bedeutung, also werden wir das nicht tun, bis wir die Konvention verstanden haben.In Python ordnet das Symbol
=den Wert auf der rechten Seite dem Namen auf der linken Seite zu.Die Variable wird erstellt, wenn ihr ein Wert zugewiesen wird.
-
Hier ordnet Python der Variablen
ageein Alter und der Variablenfirst_nameeinen Namen in Anführungszeichen zu.
Verwenden Sie print, um Werte anzuzeigen.
- Python hat eine eingebaute Funktion namens
print, die Dinge als Text ausgibt. - Rufen Sie die Funktion auf (d.h. sagen Sie Python, dass es sie ausführen soll), indem Sie ihren Namen verwenden.
- Übergeben Sie der Funktion Werte (d.h. die zu druckenden Dinge) in Klammern.
- Um eine Zeichenkette zum Ausdruck hinzuzufügen, schließen Sie die Zeichenkette in einfache oder doppelte Anführungszeichen ein.
- Die Werte, die an die Funktion übergeben werden, heißen arguments
AUSGABE
Ahmed is 42 years old-
printsetzt automatisch ein einzelnes Leerzeichen zwischen die Elemente, um sie zu trennen. - Und bricht am Ende in eine neue Zeile um.
Variablen müssen erstellt werden, bevor sie verwendet werden.
- Wenn eine Variable noch nicht existiert, oder wenn der Name falsch geschrieben wurde, meldet Python einen Fehler. (Im Gegensatz zu einigen Sprachen, die einen Standardwert “erraten”.)
FEHLER
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-1-c1fbb4e96102> in <module>()
----> 1 print(last_name)
NameError: name 'last_name' is not defined- Die letzte Zeile einer Fehlermeldung ist normalerweise die informativste.
- Wir werden uns Fehlermeldungen im Detail [später] ansehen (17-scope.md#reading-error-messages).
Variablen bleiben zwischen Zellen bestehen
Beachten Sie, dass die Reihenfolge der Ausführung von Zellen in einem Jupyter-Notizbuch wichtig ist, nicht die Reihenfolge, in der sie erscheinen. Python merkt sich den gesamten Code, der zuvor ausgeführt wurde, einschließlich aller Variablen, die Sie definiert haben, unabhängig von der Reihenfolge im Notizbuch. Wenn Sie also Variablen weiter unten im Notizbuch definieren und dann Zellen weiter oben (erneut) ausführen, sind die weiter unten definierten Variablen weiterhin vorhanden. Erstellen Sie zum Beispiel zwei Zellen mit dem folgenden Inhalt in dieser Reihenfolge:
Wenn Sie dies der Reihe nach ausführen, wird die erste Zelle einen
Fehler ergeben. Wenn Sie jedoch die erste Zelle nach der
zweiten Zelle ausführen, wird sie 1 ausgeben. Um Verwirrung
zu vermeiden, kann es hilfreich sein, die Option Kernel
-> Restart & Run All zu verwenden, die den
Interpreter löscht und alles von oben nach unten durchführt.
Variablen können in Berechnungen verwendet werden.
- Wir können Variablen in Berechnungen so verwenden, als wären sie
Werte.
- Erinnern Sie sich daran, dass wir vor ein paar Zeilen den Wert
42anagezugewiesen haben.
- Erinnern Sie sich daran, dass wir vor ein paar Zeilen den Wert
AUSGABE
Age in three years: 45Verwenden Sie einen Index, um ein einzelnes Zeichen aus einer Zeichenkette zu erhalten.
- Die Zeichen (einzelne Buchstaben, Zahlen und so weiter) in einer
Zeichenkette sind geordnet. Zum Beispiel ist die Zeichenkette
'AB'nicht dasselbe wie'BA'. Aufgrund dieser Ordnung können wir die Zeichenfolge als eine Liste von Zeichen behandeln. - Jede Position in der Zeichenkette (erste, zweite usw.) erhält eine Nummer. Diese Zahl wird als Index oder manchmal auch als tiefgestellt bezeichnet.
- Indizes sind nummeriert von 0.
- Verwenden Sie den Index der Position in eckigen Klammern, um das Zeichen an dieser Position zu erhalten.

AUSGABE
hVerwenden Sie ein Slice, um eine Teilzeichenkette zu erhalten.
- Ein Teil einer Zeichenkette wird Substring genannt. Ein Teilstring kann so kurz wie ein einzelnes Zeichen sein.
- Ein Element in einer Liste wird Element genannt. Wenn wir eine Zeichenkette wie eine Liste behandeln, sind die Elemente der Zeichenkette ihre einzelnen Zeichen.
- Ein Slice ist ein Teil einer Zeichenkette (oder, allgemeiner, ein Teil einer beliebigen listähnlichen Sache).
- Wir nehmen ein Slice mit der Notation
[start:stop], wobeistartder ganzzahlige Index des ersten Elements ist, das wir wollen, undstopder ganzzahlige Index des Elements gerade nach dem letzten Element ist, das wir wollen. - Der Unterschied zwischen
stopundstartist die Länge des Slice. - Die Entnahme eines Slice verändert nicht den Inhalt der ursprünglichen Zeichenkette. Stattdessen wird eine Kopie eines Teils der ursprünglichen Zeichenkette zurückgegeben.
AUSGABE
sodVerwenden Sie die eingebaute Funktion len, um die Länge
einer Zeichenkette zu ermitteln.
AUSGABE
6- Verschachtelte Funktionen werden von innen nach außen ausgewertet, wie in der Mathematik.
Python unterscheidet Groß- und Kleinschreibung.
- Python denkt, dass Groß- und Kleinbuchstaben unterschiedlich sind,
also sind
Nameundnameunterschiedliche Variablen. - Es gibt Konventionen für die Verwendung von Großbuchstaben am Anfang von Variablennamen, daher werden wir für den Moment Kleinbuchstaben verwenden.
Verwenden Sie aussagekräftige Variablennamen.
- Python kümmert sich nicht darum, wie Sie Variablen nennen, solange sie die Regeln befolgen (alphanumerische Zeichen und der Unterstrich).
- Verwende aussagekräftige Variablennamen, damit andere Leute verstehen, was das Programm macht.
- Die wichtigste “andere Person” ist dein zukünftiges Ich.
AUSGABE
# Command # Value of x # Value of y # Value of swap #
x = 1.0 # 1.0 # not defined # not defined #
y = 3.0 # 1.0 # 3.0 # not defined #
swap = x # 1.0 # 3.0 # 1.0 #
x = y # 3.0 # 3.0 # 1.0 #
y = swap # 3.0 # 1.0 # 1.0 #Diese drei Zeilen tauschen die Werte in x und
y aus, indem sie die Variable swap zur
temporären Speicherung verwenden. Dies ist eine ziemlich übliche
Programmiersprache.
AUSGABE
leftDer Variablen initial wird der Wert 'left'
zugewiesen. In der zweiten Zeile erhält die Variable
position ebenfalls den Stringwert 'left'. In
der dritten Zeile erhält die Variable initial den Wert
'right', aber die Variable position behält
ihren String-Wert 'left'.
Herausforderung
Wenn Sie a = 123 zuweisen, was passiert, wenn Sie
versuchen, die zweite Ziffer von a über a[1]
zu erhalten?
Zahlen sind keine Zeichenketten oder Sequenzen und Python gibt einen
Fehler aus, wenn Sie versuchen, eine Index-Operation mit einer Zahl
durchzuführen. In der nächsten
Lektion über Typen und Typkonvertierung werden wir mehr über Typen
lernen und wie man zwischen verschiedenen Typen konvertiert. Wenn man
die N-te Stelle einer Zahl sucht, kann man sie mit der eingebauten
Funktion str in eine Zeichenkette umwandeln und dann eine
Indexoperation mit dieser Zeichenkette durchführen.
FEHLER
TypeError: 'int' object is not subscriptableAUSGABE
2Auswahl eines Namens
Welcher ist ein besserer Variablenname, m,
min oder minutes? Tipp: Überlegen Sie, welchen
Code Sie lieber von jemandem erben würden, der das Labor verlässt:
ts = m * 60 + stot_sec = min * 60 + sectotal_seconds = minutes * 60 + seconds
minutes ist besser, weil min so etwas wie
“Minimum” bedeuten könnte (und eigentlich eine eingebaute Funktion in
Python ist, die wir später behandeln werden).
AUSGABE
atom_name[1:3] is: arSlicing-Konzepte
Gegeben sei die folgende Zeichenkette:
Was würden diese Ausdrücke zurückgeben?
species_name[2:8]-
species_name[11:](ohne einen Wert nach dem Doppelpunkt) -
species_name[:4](ohne einen Wert vor dem Doppelpunkt) -
species_name[:](nur ein Doppelpunkt) species_name[11:-3]species_name[-5:-3]- Was passiert, wenn man einen
stopWert wählt, der außerhalb des Bereichs liegt? (d.h., versuchen Siespecies_name[0:20]oderspecies_name[:103])
-
species_name[2:8]gibt die Teilzeichenkette'acia b'zurück -
species_name[11:]gibt die Teilzeichenkette'folia'zurück, von Position 11 bis zum Ende -
species_name[:4]gibt die Teilzeichenkette'Acac'zurück, vom Anfang bis zur Position 4, aber ohne diese -
species_name[:]gibt die gesamte Zeichenkette'Acacia buxifolia'zurück -
species_name[11:-3]gibt die Teilzeichenkette'fo'zurück, von der 11. bis zur drittletzten Position -
species_name[-5:-3]gibt auch die Teilzeichenkette'fo'zurück, von der fünftletzten bis zur drittletzten Position - Wenn ein Teil des Slice außerhalb des Bereichs liegt, schlägt die
Operation nicht fehl.
species_name[0:20]liefert das gleiche Ergebnis wiespecies_name[0:], undspecies_name[:103]liefert das gleiche Ergebnis wiespecies_name[:]
- Verwende Variablen, um Werte zu speichern.
- Verwenden Sie
print, um Werte anzuzeigen. - Variablen bleiben zwischen Zellen bestehen.
- Variablen müssen erstellt werden, bevor sie verwendet werden.
- Variablen können in Berechnungen verwendet werden.
- Verwenden Sie einen Index, um ein einzelnes Zeichen aus einer Zeichenkette zu erhalten.
- Verwenden Sie ein Slice, um eine Teilzeichenkette zu erhalten.
- Verwenden Sie die eingebaute Funktion
len, um die Länge einer Zeichenkette zu ermitteln. - Python unterscheidet Groß- und Kleinschreibung.
- Verwenden Sie aussagekräftige Variablennamen.
Content from Datentypen und Typkonvertierung
Zuletzt aktualisiert am 2025-10-30 | Diese Seite bearbeiten
Übersicht
Fragen
- Welche Arten von Daten werden in Programmen gespeichert?
- Wie kann ich einen Typ in einen anderen umwandeln?
Ziele
- Erläutern Sie die wichtigsten Unterschiede zwischen Ganzzahlen und Fließkommazahlen.
- Erläutern Sie die wichtigsten Unterschiede zwischen Zahlen und Zeichenketten.
- Verwenden Sie eingebaute Funktionen, um zwischen Ganzzahlen, Fließkommazahlen und Zeichenketten zu konvertieren.
Jeder Wert hat einen Typ.
- Jeder Wert in einem Programm hat einen bestimmten Typ.
- Integer (
int): repräsentiert positive oder negative ganze Zahlen wie 3 oder -512. - Fließkommazahl (
float): repräsentiert reelle Zahlen wie 3.14159 oder -2.5. - Zeichenkette (gewöhnlich “string” genannt,
str): text.- Wird entweder in einfachen oder in doppelten Anführungszeichen geschrieben (solange sie übereinstimmen).
- Die Anführungszeichen werden nicht gedruckt, wenn die Zeichenkette angezeigt wird.
Verwenden Sie die eingebaute Funktion type, um den Typ
eines Wertes zu ermitteln.
- Verwenden Sie die eingebaute Funktion
type, um herauszufinden, welchen Typ ein Wert hat. - Funktioniert auch mit Variablen.
- Aber denken Sie daran: der Wert hat den Typ — die Variable ist nur eine Bezeichnung.
AUSGABE
<class 'int'>AUSGABE
<class 'str'>Typen steuern, welche Operationen (oder Methoden) mit einem bestimmten Wert durchgeführt werden können.
- Der Typ eines Wertes bestimmt, was das Programm mit ihm machen kann.
AUSGABE
2FEHLER
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-2-67f5626a1e07> in <module>()
----> 1 print('hello' - 'h')
TypeError: unsupported operand type(s) for -: 'str' and 'str'Sie können die Operatoren “+” und “*” auf Zeichenketten anwenden.
- “Hinzufügen” von Zeichenketten verkettet diese.
AUSGABE
Ahmed Walsh- Die Multiplikation einer Zeichenkette mit einer ganzen Zahl
N erzeugt eine neue Zeichenkette, die aus dieser Zeichenkette
besteht, die N Mal wiederholt wird.
- Da die Multiplikation eine wiederholte Addition ist.
AUSGABE
==========Strings haben eine Länge (aber Zahlen nicht).
- Die eingebaute Funktion
lenzählt die Anzahl der Zeichen in einer Zeichenkette.
AUSGABE
11- Aber Zahlen haben keine Länge (nicht einmal Null).
FEHLER
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-3-f769e8e8097d> in <module>()
----> 1 print(len(52))
TypeError: object of type 'int' has no len()Bei der Verarbeitung von Zahlen müssen diese in Zeichenfolgen umgewandelt werden oder umgekehrt.
- Kann keine Zahlen und Strings addieren.
FEHLER
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-fe4f54a023c6> in <module>()
----> 1 print(1 + '2')
TypeError: unsupported operand type(s) for +: 'int' and 'str'- Nicht erlaubt, weil mehrdeutig: sollte
1 + '2'3oder'12'sein? - Einige Typen können in andere Typen konvertiert werden, indem der Typname als Funktion verwendet wird.
AUSGABE
3
12Kann Ganzzahlen und Fließkommazahlen in Operationen frei mischen.
- Ganzzahlen und Fließkommazahlen können in der Arithmetik gemischt
werden.
- Python 3 wandelt ganze Zahlen bei Bedarf automatisch in Fließkommazahlen um.
AUSGABE
half is 0.5
three squared is 9.0Variablen ändern ihren Wert nur, wenn ihnen etwas zugewiesen wird.
- Wenn wir eine Zelle in einem Arbeitsblatt von einer anderen abhängig machen und letztere aktualisieren, wird die erstere automatisch aktualisiert.
- Dies geschieht nicht in Programmiersprachen.
PYTHON
variable_one = 1
variable_two = 5 * variable_one
variable_one = 2
print('first is', variable_one, 'and second is', variable_two)AUSGABE
first is 2 and second is 5- Der Computer liest den Wert von
variable_one, wenn er die Multiplikation durchführt, erzeugt einen neuen Wert und weist ihnvariable_twozu. - Danach wird der Wert von
variable_twoauf den neuen Wert gesetzt und nicht abhängig vonvariable_one, so dass sich sein Wert nicht automatisch ändert, wenn sichvariable_oneändert.
Brüche
Was für ein Wert ist 3,4? Wie kann man das herausfinden?
Automatische Typkonvertierung
Was für ein Wert ist 3,25 + 4?
Wählen Sie einen Typ
Welche Art von Wert (Ganzzahl, Fließkommazahl oder Zeichenkette) würden Sie verwenden, um jede der folgenden Angaben darzustellen? Versuchen Sie, mehr als eine gute Antwort für jedes Problem zu finden. Wann wäre zum Beispiel in Frage 1 das Zählen von Tagen mit einer Fließkommazahl sinnvoller als mit einer ganzen Zahl?
- Anzahl der Tage seit Beginn des Jahres.
- Zeit, die vom Jahresanfang bis jetzt verstrichen ist, in Tagen.
- Seriennummer eines Laborgerätes.
- Das Alter einer Laborprobe
- Aktuelle Einwohnerzahl einer Stadt.
- Durchschnittliche Einwohnerzahl einer Stadt über die Zeit.
Die Antworten auf die Fragen lauten:
- Ganzzahl, da die Anzahl der Tage zwischen 1 und 365 liegen würde.
- Fließkomma, da gebrochene Tage benötigt werden
- Zeichenkette, wenn die Seriennummer Buchstaben und Zahlen enthält, andernfalls Ganzzahl, wenn die Seriennummer nur aus Ziffern besteht
- Dies wird variieren! Wie definiert man das Alter einer Probe? ganze Tage seit der Entnahme (Integer)? Datum und Uhrzeit (String)?
- Wählen Sie Fließkommazahlen, um die Bevölkerung als große Aggregate (z.B. Millionen) darzustellen, oder Ganzzahlen, um die Bevölkerung in Einheiten von Individuen darzustellen.
- Fließkommazahl, da ein Durchschnitt wahrscheinlich einen Bruchteil hat.
Divisionstypen
In Python 3 führt der //-Operator Ganzzahldivisionen
durch, der /-Operator führt Fließkommadivisionen durch, und
der %-Operator (oder modulo) berechnet den Rest
einer Ganzzahldivision und gibt ihn zurück:
AUSGABE
5 // 3: 1
5 / 3: 1.6666666666666667
5 % 3: 2Wenn num_subjects die Anzahl der Probanden ist, die an
einer Studie teilnehmen, und num_per_survey die Anzahl, die
an einer einzigen Umfrage teilnehmen kann, schreibe einen Ausdruck, der
die Anzahl der Umfragen berechnet, die nötig sind, um alle einmal zu
erreichen.
Wir wollen die minimale Anzahl von Umfragen, die jeden einmal
erreicht, was der aufgerundete Wert von
num_subjects/ num_per_survey ist. Dies ist gleichbedeutend
mit der Durchführung einer Bodenteilung durch // und der
Addition von 1. Vor der Division müssen wir 1 von der Anzahl der
Probanden subtrahieren, um den Fall zu behandeln, dass
num_subjects durch num_per_survey gleichmäßig
teilbar ist.
PYTHON
num_subjects = 600
num_per_survey = 42
num_surveys = (num_subjects - 1) // num_per_survey + 1
print(num_subjects, 'subjects,', num_per_survey, 'per survey:', num_surveys)AUSGABE
600 subjects, 42 per survey: 15Zeichenketten in Zahlen umwandeln
Wo es sinnvoll ist, konvertiert float() einen String in
eine Fließkommazahl und int() konvertiert eine
Fließkommazahl in eine Ganzzahl:
AUSGABE
string to float: 3.4
float to int: 3Wenn die Konvertierung jedoch keinen Sinn ergibt, wird eine Fehlermeldung ausgegeben.
FEHLER
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-5-df3b790bf0a2> in <module>
----> 1 print("string to float:", float("Hello world!"))
ValueError: could not convert string to float: 'Hello world!'Was erwarten Sie angesichts dieser Informationen von dem folgenden Programm?
Was macht sie eigentlich?
Warum glauben Sie, dass es das tut?
Was erwarten Sie von diesem Programm zu tun? Es wäre gar nicht so
abwegig zu erwarten, dass der Python 3 int-Befehl die
Zeichenkette “3.4” in 3.4 und eine zusätzliche Typkonvertierung in 3
umwandelt. Schließlich kann Python 3 noch eine Menge anderer Zaubereien
- ist das nicht Teil seines Charmes?
AUSGABE
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-2-ec6729dfccdc> in <module>
----> 1 int("3.4")
ValueError: invalid literal for int() with base 10: '3.4'Python 3 gibt jedoch einen Fehler aus. Warum eigentlich? Um konsistent zu sein, möglicherweise. Wenn Sie Python auffordern, zwei aufeinanderfolgende Typecasts durchzuführen, müssen Sie es explizit im Code umwandeln.
AUSGABE
3Arithmetik mit verschiedenen Typen
Welche der folgenden Möglichkeiten gibt die Fließkommazahl
2.0 zurück? Hinweis: Es kann mehr als eine richtige Antwort
geben.
first + float(second)float(second) + float(third)first + int(third)first + int(float(third))int(first) + int(float(third))2.0 * second
Antwort: 1 und 4
Komplexe Zahlen
Python bietet komplexe Zahlen, die als 1.0+2.0j
geschrieben werden. Wenn val eine komplexe Zahl ist, können
ihre realen und imaginären Teile mit der Punktnotation als
val.real und val.imag angesprochen werden.
AUSGABE
6.0
2.0- Warum, glaubst du, verwendet Python
jstattifür den Imaginärteil? - Was soll
1 + 2j + 3ergeben? - Was erwarten Sie von
4j? Was ist mit4 joder4 + j?
- In der Standardmathematik wird üblicherweise
izur Bezeichnung einer imaginären Zahl verwendet. Medienberichten zufolge handelt es sich dabei jedoch um eine frühe Konvention aus der Elektrotechnik, deren Änderung nun einen technisch aufwendigen Bereich darstellt. Stack Overflow bietet zusätzliche Erklärungen und Diskussionen (4+2j)-
4jundSyntax Error: invalid syntax. In den letztgenannten Fällen wirdjals Variable betrachtet und die Aussage hängt davon ab, objdefiniert ist und wenn ja, welcher Wert ihm zugewiesen wurde.
- Jeder Wert hat einen Typ.
- Verwenden Sie die eingebaute Funktion
type, um den Typ eines Wertes zu ermitteln. - Typen steuern, welche Operationen mit Werten durchgeführt werden können.
- Strings können addiert und multipliziert werden.
- Zeichenketten haben eine Länge (Zahlen jedoch nicht).
- Muss Zahlen in Zeichenketten umwandeln oder umgekehrt, wenn er mit ihnen operiert.
- Kann Ganzzahlen und Fließkommazahlen in Operationen frei mischen.
- Variablen ändern ihren Wert nur, wenn ihnen etwas zugewiesen wird.
Content from Eingebaute Funktionen und Hilfe
Zuletzt aktualisiert am 2025-10-30 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich eingebaute Funktionen verwenden?
- Wie kann ich herausfinden, was sie tun?
- Welche Arten von Fehlern können in Programmen auftreten?
Ziele
- Erläutern Sie den Zweck von Funktionen.
- Rufen Sie eingebaute Python-Funktionen korrekt auf.
- Richtiges Verschachteln von Aufrufen zu eingebauten Funktionen.
- Verwenden Sie die Hilfe, um die Dokumentation für eingebaute Funktionen anzuzeigen.
- Situationen, in denen SyntaxError und NameError auftreten, korrekt beschreiben.
Verwenden Sie Kommentare, um die Dokumentation von Programmen zu ergänzen.
Eine Funktion kann null oder mehr Argumente annehmen.
- Wir haben schon einige Funktionen gesehen — jetzt wollen wir sie uns genauer ansehen.
- Ein Argument ist ein Wert, der an eine Funktion übergeben wird.
-
lennimmt genau einen. -
int,strundfloaterzeugen einen neuen Wert aus einem bestehenden. -
printnimmt null oder mehr. -
printohne Argumente gibt eine leere Zeile aus.- Muss immer Klammern verwenden, auch wenn sie leer sind, damit Python weiß, dass eine Funktion aufgerufen wird.
AUSGABE
before
afterJede Funktion gibt etwas zurück.
- Jeder Funktionsaufruf erzeugt ein Ergebnis.
- Wenn die Funktion kein brauchbares Ergebnis zurückgeben kann, gibt
sie normalerweise den speziellen Wert
Nonezurück.Noneist ein Python-Objekt, das immer dann einspringt, wenn es keinen Wert gibt.
AUSGABE
example
result of print is NoneHäufig genutzte eingebaute Funktionen sind max,
min und round.
- Verwenden Sie
max, um den größten Wert von einem oder mehreren Werten zu finden. - Verwenden Sie
min, um die kleinste Zahl zu finden. - Beide funktionieren sowohl mit Zeichenketten als auch mit Zahlen.
- “Größer” und “kleiner” verwenden (0-9, A-Z, a-z), um Buchstaben zu vergleichen.
AUSGABE
3
0Funktionen können nur für bestimmte (Kombinationen von) Argumenten funktionieren.
-
maxundminmüssen mit mindestens einem Argument versehen werden.- “Größte der leeren Menge” ist eine sinnlose Frage.
- Und ihnen müssen Dinge gegeben werden, die sinnvoll verglichen werden können.
FEHLER
TypeError Traceback (most recent call last)
<ipython-input-52-3f049acf3762> in <module>
----> 1 print(max(1, 'a'))
TypeError: '>' not supported between instances of 'str' and 'int'Funktionen können Standardwerte für einige Argumente haben.
-
roundrundet eine Fließkommazahl ab. - Rundet standardmäßig auf null Dezimalstellen.
AUSGABE
4- Wir können die Anzahl der gewünschten Dezimalstellen angeben.
AUSGABE
3.7Funktionen, die an Objekte angehängt sind, werden Methoden genannt
- Funktionen nehmen eine andere Form an, die in den Pandas-Episoden üblich sein wird.
- Methoden haben Klammern wie Funktionen, stehen aber hinter der Variablen.
- Einige Methoden werden für interne Python-Operationen verwendet und sind durch doppelte Unterstriche gekennzeichnet.
PYTHON
my_string = 'Hello world!' # Erstellung eines String-Objekts
print(len(my_string)) # Die Funktion len nimmt eine Zeichenkette als Argument und gibt die Länge der Zeichenkette zurück
print(my_string.swapcase()) # Aufruf der swapcase-Methode für das Objekt my_string
print(my_string.__len__()) # Aufruf der internen Methode __len__ für das Objekt my_string, verwendet von len(my_string)AUSGABE
12
hELLO WORLD!
12- Man kann sie sogar aneinandergereiht sehen. Sie arbeiten von links nach rechts.
PYTHON
print(my_string.isupper()) # Nicht alle Buchstaben sind Großbuchstaben
print(my_string.upper()) # Dadurch werden alle Buchstaben großgeschrieben
print(my_string.upper().isupper()) # Jetzt sind alle Buchstaben groß geschriebenAUSGABE
False
HELLO WORLD
TrueVerwenden Sie die eingebaute Funktion help, um Hilfe
für eine Funktion zu erhalten.
- Jede eingebaute Funktion hat eine Online-Dokumentation.
AUSGABE
Help on built-in function round in module builtins:
round(number, ndigits=None)
Round a number to a given precision in decimal digits.
The return value is an integer if ndigits is omitted or None. Otherwise
the return value has the same type as the number. ndigits may be negative.Das Jupyter Notebook bietet zwei Möglichkeiten, Hilfe zu erhalten.
- Option 1: Platzieren Sie den Cursor in der Nähe der Stelle, an der
die Funktion in einer Zelle aufgerufen wird (d.h. der Funktionsname oder
ihre Parameter),
- Halten Sie Shift gedrückt und drücken Sie Tab.
- Führen Sie dies mehrmals durch, um die zurückgegebenen Informationen zu erweitern.
- Option 2: Geben Sie den Funktionsnamen in eine Zelle ein, hinter der ein Fragezeichen steht. Führen Sie dann die Zelle aus.
Python meldet einen Syntaxfehler, wenn es den Quelltext eines Programms nicht verstehen kann.
- Versucht erst gar nicht, das Programm auszuführen, wenn es nicht geparst werden kann.
FEHLER
File "<ipython-input-56-f42768451d55>", line 2
name = 'Feng
^
SyntaxError: EOL while scanning string literalFEHLER
File "<ipython-input-57-ccc3df3cf902>", line 2
age = = 52
^
SyntaxError: invalid syntax- Sehen Sie sich die Fehlermeldung genauer an:
FEHLER
File "<ipython-input-6-d1cc229bf815>", line 1
print ("hello world"
^
SyntaxError: unexpected EOF while parsing- Die Meldung weist auf ein Problem in der ersten Zeile der Eingabe
(“Zeile 1”) hin.
- In diesem Fall sagt uns der Abschnitt “ipython-input” des Dateinamens, dass wir mit Eingaben in IPython arbeiten, dem Python-Interpreter, der vom Jupyter Notebook verwendet wird.
- Der Teil
-6-des Dateinamens zeigt an, dass der Fehler in Zelle 6 unseres Notebooks aufgetreten ist. - Es folgt die problematische Codezeile, die auf das Problem mit einem
^-Zeiger hinweist.
Python meldet einen Laufzeitfehler, wenn bei der Ausführung eines Programms etwas schief läuft.
FEHLER
NameError Traceback (most recent call last)
<ipython-input-59-1214fb6c55fc> in <module>
1 age = 53
----> 2 remaining = 100 - aege # mis-spelled 'age'
NameError: name 'aege' is not defined- Beheben Sie Syntaxfehler durch Lesen des Quellcodes und Laufzeitfehler durch Verfolgen der Ausführung.
Was passiert, wenn
- Reihenfolge der Operationen:
1.1 * radiance = 1.11.1 - 0.5 = 0.6min(radiance, 0.6) = 0.62.0 + 0.6 = 2.6max(2.1, 2.6) = 2.6- Am Ende,
radiance = 2.6
Erkenne den Unterschied
- Sagen Sie voraus, was jede der
print-Anweisungen im folgenden Programm ausgeben wird. - Läuft
max(len(rich), poor)oder gibt es eine Fehlermeldung? Wenn es ausgeführt wird, ergibt das Ergebnis einen Sinn?
AUSGABE
cAUSGABE
tinAUSGABE
4max(len(rich), poor) wirft einen TypeError. Daraus wird
max(4, 'tin'), und wie wir bereits besprochen haben, können
eine Zeichenkette und eine ganze Zahl nicht sinnvoll verglichen
werden.
FEHLER
TypeError Traceback (most recent call last)
<ipython-input-65-bc82ad05177a> in <module>
----> 1 max(len(rich), poor)
TypeError: '>' not supported between instances of 'str' and 'int'Warum nicht?
Warum geben max und min nicht
None zurück, wenn sie ohne Argumente aufgerufen werden?
max und min geben in diesem Fall TypeErrors
zurück, weil nicht die richtige Anzahl von Parametern übergeben wurde.
Wenn nur None zurückgegeben würde, wäre der Fehler viel
schwieriger zu verfolgen, da er wahrscheinlich in einer Variablen
gespeichert und später im Programm verwendet würde, nur um dann
wahrscheinlich einen Laufzeitfehler auszulösen.
Letztes Zeichen einer Zeichenkette
Wenn Python bei Null anfängt zu zählen und len die
Anzahl der Zeichen in einer Zeichenkette liefert, welcher Indexausdruck
liefert dann das letzte Zeichen in der Zeichenkette name?
(Hinweis: Wir werden in einer späteren Folge einen einfacheren Weg
sehen, dies zu tun.)
name[len(name) - 1]
Erforschen Sie die Python-Dokumente!
Die offizielle Python-Dokumentation ist wohl die vollständigste Informationsquelle über die Sprache. Sie ist in verschiedenen Sprachen verfügbar und enthält eine Menge nützlicher Ressourcen. Die Seite Built-in Functions enthält einen Katalog all dieser Funktionen, einschließlich derer, die wir in dieser Lektion behandelt haben. Einige dieser Funktionen sind fortgeschrittener und im Moment unnötig, aber andere sind sehr einfach und nützlich.
- Verwenden Sie Kommentare, um Programme zu dokumentieren.
- Eine Funktion kann null oder mehr Argumente annehmen.
- Zu den häufig verwendeten eingebauten Funktionen gehören
max,minundround. - Funktionen können nur für bestimmte (Kombinationen von) Argumenten funktionieren.
- Funktionen können Standardwerte für einige Argumente haben.
- Benutzen Sie die eingebaute Funktion
help, um Hilfe für eine Funktion zu erhalten. - Das Jupyter Notebook bietet zwei Möglichkeiten, Hilfe zu erhalten.
- Jede Funktion gibt etwas zurück.
- Python meldet einen Syntaxfehler, wenn es den Quelltext eines Programms nicht verstehen kann.
- Python meldet einen Laufzeitfehler, wenn bei der Ausführung eines Programms etwas schief läuft.
- Beheben Sie Syntaxfehler, indem Sie den Quellcode lesen, und Laufzeitfehler, indem Sie die Ausführung des Programms verfolgen.
Content from Morgenkaffee
Zuletzt aktualisiert am 2025-03-02 | Diese Seite bearbeiten
Reflexionsübung
Denken Sie beim Kaffee über Folgendes nach und diskutieren Sie es:
- Welche verschiedenen Arten von Fehlern meldet Python?
- Hat der Code immer die erwarteten Ergebnisse geliefert? Wenn nicht, warum?
- Gibt es etwas, das wir tun können, um Fehler beim Schreiben von Code zu vermeiden?
Content from Bibliotheken
Zuletzt aktualisiert am 2025-10-30 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich Software benutzen, die andere Leute geschrieben haben?
- Wie kann ich herausfinden, was diese Software macht?
Ziele
- Erklären, was Softwarebibliotheken sind und warum Programmierer sie erstellen und benutzen.
- Schreibe Programme, die Module aus der Python-Standardbibliothek importieren und verwenden.
- Suchen und lesen Sie die Dokumentation der Standardbibliothek interaktiv (im Interpreter) und online.
Der größte Teil der Macht einer Programmiersprache liegt in ihren Bibliotheken.
- Eine Bibliothek ist eine Sammlung von Dateien
(Module genannt), die Funktionen zur Verwendung durch andere
Programme enthält.
- Kann auch Datenwerte (z.B. numerische Konstanten) und andere Dinge enthalten.
- Der Inhalt einer Bibliothek sollte zusammengehören, aber es gibt keine Möglichkeit, das zu erzwingen.
- Die Python-Standardbibliothek ist eine umfangreiche Sammlung von Modulen, die mit Python selbst geliefert wird.
- Viele zusätzliche Bibliotheken sind über PyPI (den Python Package Index) erhältlich.
- Wir werden später sehen, wie man neue Bibliotheken schreibt.
Bibliotheken und Module
Eine Bibliothek ist eine Sammlung von Modulen, aber die Begriffe werden oft austauschbar verwendet, vor allem, da viele Bibliotheken nur aus einem einzigen Modul bestehen, also mach dir keine Sorgen, wenn du sie vermischt.
Ein Programm muss ein Bibliotheksmodul importieren, bevor es es verwenden kann.
- Benutze
import, um ein Bibliotheksmodul in den Speicher eines Programms zu laden. - Dann verweise auf Dinge aus dem Modul als
module_name.thing_name.- Python verwendet
.als Bezeichnung für “Teil von”.
- Python verwendet
- Verwendung von
math, einem der Module der Standardbibliothek:
AUSGABE
pi is 3.141592653589793
cos(pi) is -1.0- Auf jedes Element muss mit dem Namen des Moduls verwiesen werden.
-
math.cos(pi)wird nicht funktionieren: der Verweis aufpi“erbt” nicht irgendwie den Verweis der Funktion aufmath.
-
Benutzen Sie help, um etwas über den Inhalt eines
Bibliotheksmoduls zu erfahren.
- Funktioniert genau wie die Hilfe für eine Funktion.
AUSGABE
Help on module math:
NAME
math
MODULE REFERENCE
http://docs.python.org/3/library/math
The following documentation is automatically generated from the Python
source files. It may be incomplete, incorrect or include features that
are considered implementation detail and may vary between Python
implementations. When in doubt, consult the module reference at the
location listed above.
DESCRIPTION
This module is always available. It provides access to the
mathematical functions defined by the C standard.
FUNCTIONS
acos(x, /)
Return the arc cosine (measured in radians) of x.
⋮ ⋮ ⋮Importieren Sie bestimmte Elemente aus einem Bibliotheksmodul, um Programme zu verkürzen.
- Verwenden Sie
from ... import ..., um nur bestimmte Elemente aus einem Bibliotheksmodul zu laden. - Dann verweisen Sie direkt auf sie ohne den Bibliotheksnamen als Präfix.
AUSGABE
cos(pi) is -1.0Erstellen Sie einen Alias für ein Bibliotheksmodul, wenn Sie es importieren, um Programme zu verkürzen.
- Benutzen Sie
import ... as ..., um einer Bibliothek einen kurzen Alias zu geben, während Sie sie importieren. - Dann verweisen Sie auf Elemente in der Bibliothek mit diesem verkürzten Namen.
AUSGABE
cos(pi) is -1.0- Wird häufig für Bibliotheken verwendet, die häufig benutzt werden
oder lange Namen haben.
- z.B. wird die
matplotlibPlot-Bibliothek oft alsmplaliasiert.
- z.B. wird die
- Dies kann jedoch dazu führen, dass Programme schwerer zu verstehen sind, da die Leser die Aliasnamen Ihres Programms lernen müssen.
Inspizieren des Math-Moduls
- Welche Funktion aus dem Modul
mathkönnen Sie verwenden, um eine Quadratwurzel ohne Verwendung vonsqrtzu berechnen? - Da die Bibliothek diese Funktion enthält, warum existiert
sqrt?
Mit
help(math)sehen wir, dass wirpow(x,y)zusätzlich zusqrt(x)haben, also könnten wirpow(x, 0.5)benutzen, um eine Quadratwurzel zu finden.Die Funktion
sqrt(x)ist bei der Implementierung von Gleichungen wohl lesbarer alspow(x, 0.5). Lesbarkeit ist ein Eckpfeiler guter Programmierung, daher ist es sinnvoll, eine spezielle Funktion für diesen speziellen Fall bereitzustellen.
Auch das Design der Python-Bibliothek math hat seinen
Ursprung im C-Standard, der sowohl sqrt(x) als auch
pow(x,y) enthält, also zeigt sich ein wenig von der
Geschichte des Programmierens in Pythons Funktionsnamen.
Auffinden des richtigen Moduls
Sie wollen ein zufälliges Zeichen aus einer Zeichenkette auswählen:
- Welches Standardbibliothek-Modul könnte Ihnen helfen?
- Welche Funktion würden Sie aus diesem Modul auswählen? Gibt es Alternativen?
- Versuche, ein Programm zu schreiben, das die Funktion verwendet.
Das Zufallsmodul scheint zu helfen.
Die Zeichenkette besteht aus 11 Zeichen, die jeweils einen
Positionsindex von 0 bis 10 haben. Sie könnten die Funktionen
random.randrange(https://docs.python.org/3/library/random.html#random.randrange)
oder random.randint(https://docs.python.org/3/library/random.html#random.randint)
verwenden, um eine zufällige ganze Zahl zwischen 0 und 10 zu erhalten,
und dann das Zeichenbasesan diesem Index auswählen:
oder noch kompakter:
Vielleicht haben Sie die Funktion random.sample
gefunden? Sie ermöglicht etwas weniger Tipparbeit, ist aber vielleicht
etwas schwerer zu verstehen, wenn man nur liest:
Beachten Sie, dass diese Funktion eine Liste von Werten zurückgibt. Wir werden in Folge 11 etwas über Listen lernen.
Die einfachste und kürzeste Lösung ist die Funktion random.choice,
die genau das tut, was wir wollen:
Jigsaw Puzzle (Parsons’s Problem) Programmierbeispiel
Ordnen Sie die folgenden Anweisungen so an, dass eine zufällige DNA-Base und ihr Index in der Zeichenkette ausgegeben wird. Es werden nicht alle Anweisungen benötigt. Sie können auch Zwischenvariablen verwenden/hinzufügen.
Wann ist die Hilfe verfügbar?
Wenn ein Kollege von Ihnen help(math) tippt, meldet
Python einen Fehler:
FEHLER
NameError: name 'math' is not definedWas hat Ihr Kollege vergessen zu tun?
Importieren des Mathe-Moduls (import math)
kann geschrieben werden als
Da Sie den Code gerade erst geschrieben haben und mit ihm vertraut sind, finden Sie die erste Version vielleicht sogar einfacher zu lesen. Wenn Sie jedoch versuchen, einen umfangreichen Code zu lesen, der von jemand anderem geschrieben wurde, oder wenn Sie nach mehreren Monaten zu Ihrem eigenen umfangreichen Code zurückkehren, sind nicht abgekürzte Namen oft einfacher, es sei denn, es gibt klare Abkürzungskonventionen.
Es gibt viele Möglichkeiten, Bibliotheken zu importieren!
Ordnen Sie die folgenden Druckanweisungen den entsprechenden Bibliotheksaufrufen zu.
Druckbefehle:
print("sin(pi/2) =", sin(pi/2))print("sin(pi/2) =", m.sin(m.pi/2))print("sin(pi/2) =", math.sin(math.pi/2))
Bibliotheksaufrufe:
from math import sin, piimport mathimport math as mfrom math import *
- Bibliotheksaufrufe 1 und 4. Um direkt auf
sinundpiohne den Bibliotheksnamen als Präfix zu verweisen, müssen Sie die Anweisungfrom ... import ...verwenden. Während Bibliotheksaufruf 1 speziell die beiden Funktionensinundpiimportiert, importiert Bibliotheksaufruf 4 alle Funktionen im Modulmath. - Bibliotheksaufruf 3. Hier werden
sinundpimit einem verkürzten Bibliotheksnamenmanstelle vonmathangesprochen. Bibliotheksaufruf 3 macht genau das mit der Syntaximport ... as ...- er erzeugt einen Alias fürmathin Form des verkürzten Namensm. - Bibliotheksaufruf 2. Hier wird auf
sinundpimit dem regulären Bibliotheksnamenmathverwiesen, so dass der reguläre Aufrufimport ...ausreicht.
Hinweis: Obwohl der Bibliotheksaufruf 4
funktioniert, ist es nicht
empfohlen, alle Namen aus einem Modul mit einem Platzhalterimport zu
importieren, da es dadurch unklar wird, welche Namen aus dem Modul im
Code verwendet werden. Im Allgemeinen ist es am besten, Ihre Importe so
spezifisch wie möglich zu gestalten und nur das zu importieren, was Ihr
Code verwendet. In Bibliotheksaufruf 1 sagt uns die Anweisung
import explizit, dass die Funktion sin aus dem
Modul math importiert wird, aber Bibliotheksaufruf 4
vermittelt diese Information nicht.
Importieren bestimmter Elemente
Wahrscheinlich finden Sie diese Version einfacher zu lesen, da sie
weniger dicht ist. Der Hauptgrund, diese Form des Imports nicht zu
verwenden, ist die Vermeidung von Namenskonflikten. Sie würden zum
Beispiel degrees nicht auf diese Weise importieren, wenn
Sie auch den Namen degrees für eine eigene Variable oder
Funktion verwenden wollten. Oder wenn Sie auch eine Funktion mit dem
Namen degrees aus einer anderen Bibliothek importieren
würden.
AUSGABE
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-1-d72e1d780bab> in <module>
1 from math import log
----> 2 log(0)
ValueError: math domain error- Der Logarithmus von
xist nur fürx > 0definiert, also liegt 0 außerhalb des Bereichs der Funktion. - Sie erhalten einen Fehler vom Typ
ValueError, der anzeigt, dass die Funktion einen unpassenden Argumentwert erhalten hat. Die zusätzliche Meldung “math domain error” macht deutlicher, wo das Problem liegt.
- Der größte Teil der Macht einer Programmiersprache liegt in ihren Bibliotheken.
- Ein Programm muss ein Bibliotheksmodul importieren, um es verwenden zu können.
- Verwenden Sie
help, um mehr über den Inhalt eines Bibliotheksmoduls zu erfahren. - Importieren Sie bestimmte Elemente aus einer Bibliothek, um Programme zu verkürzen.
- Erstellen Sie einen Alias für eine Bibliothek, wenn Sie diese importieren, um Programme zu verkürzen.
Content from Tabellarische Daten in DataFrames einlesen
Zuletzt aktualisiert am 2025-10-31 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich tabellarische Daten lesen?
Ziele
- Importieren Sie die Pandas-Bibliothek.
- Verwenden Sie Pandas, um einen einfachen CSV-Datensatz zu laden.
- Erhalten Sie einige grundlegende Informationen über einen Pandas DataFrame.
Verwenden Sie die Pandas-Bibliothek, um Statistiken über tabellarische Daten zu erstellen.
- Pandas ist eine weit verbreitete Python-Bibliothek für Statistiken, insbesondere für tabellarische Daten.
- Übernimmt viele Funktionen aus den Dataframes von R.
- Eine 2-dimensionale Tabelle, deren Spalten Namen haben und möglicherweise verschiedene Datentypen haben.
- Pandas mit
import pandas as pdladen. Der Aliaspdwird üblicherweise verwendet, um im Code auf die Pandas-Bibliothek zu verweisen. - Einlesen einer CSV-Datendatei (Comma Separated Values) mit
pd.read_csv.- Argument ist der Name der zu lesenden Datei.
- Gibt einen DataFrame zurück, den Sie einer Variablen zuweisen können
PYTHON
import pandas as pd
data_oceania = pd.read_csv('data/gapminder_gdp_oceania.csv')
print(data_oceania)AUSGABE
country gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 \
0 Australia 10039.59564 10949.64959 12217.22686
1 New Zealand 10556.57566 12247.39532 13175.67800
gdpPercap_1967 gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 \
0 14526.12465 16788.62948 18334.19751 19477.00928
1 14463.91893 16046.03728 16233.71770 17632.41040
gdpPercap_1987 gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 \
0 21888.88903 23424.76683 26997.93657 30687.75473
1 19007.19129 18363.32494 21050.41377 23189.80135
gdpPercap_2007
0 34435.36744
1 25185.00911- Die Spalten in einem DataFrame sind die beobachteten Variablen und die Zeilen die Beobachtungen.
- Pandas verwendet den Backslash
\, um umbrochene Zeilen anzuzeigen, wenn die Ausgabe zu breit ist, um auf den Bildschirm zu passen. - Die Verwendung von beschreibenden Namen für DataFrame hilft uns, zwischen mehreren DataFrame zu unterscheiden, damit wir nicht versehentlich einen DataFrame überschreiben oder aus dem falschen DataFrame lesen.
Datei nicht gefunden
Unsere Lektionen speichern ihre Datendateien in einem
Unterverzeichnis data, weshalb der Pfad zur Datei
data/gapminder_gdp_oceania.csv lautet. Wenn Sie vergessen,
data/ einzuschließen, oder wenn Sie es einschließen, aber
Ihre Kopie der Datei irgendwo anders liegt, erhalten Sie einen Laufzeitfehler, der mit einer Zeile wie
dieser endet:
FEHLER
FileNotFoundError: [Errno 2] No such file or directory: 'data/gapminder_gdp_oceania.csv'Verwenden Sie index_col, um anzugeben, dass die Werte
einer Spalte als Zeilenüberschriften verwendet werden sollen.
- Die Zeilenüberschriften sind Zahlen (in diesem Fall 0 und 1).
- Möchte wirklich nach Ländern indexieren.
- Übergeben Sie dazu den Namen der Spalte an den Parameter
read_csvalsindex_col. - Die Benennung des DataFrames
data_oceania_countrysagt uns, welche Region die Daten umfassen (oceania) und wie sie indiziert sind (country).
PYTHON
data_oceania_country = pd.read_csv('data/gapminder_gdp_oceania.csv', index_col='country')
print(data_oceania_country)AUSGABE
gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 gdpPercap_1967 \
country
Australia 10039.59564 10949.64959 12217.22686 14526.12465
New Zealand 10556.57566 12247.39532 13175.67800 14463.91893
gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 gdpPercap_1987 \
country
Australia 16788.62948 18334.19751 19477.00928 21888.88903
New Zealand 16046.03728 16233.71770 17632.41040 19007.19129
gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 gdpPercap_2007
country
Australia 23424.76683 26997.93657 30687.75473 34435.36744
New Zealand 18363.32494 21050.41377 23189.80135 25185.00911Verwenden Sie die Methode DataFrame.info(), um mehr
über einen DataFrame herauszufinden.
AUSGABE
<class 'pandas.core.frame.DataFrame'>
Index: 2 entries, Australia to New Zealand
Data columns (total 12 columns):
gdpPercap_1952 2 non-null float64
gdpPercap_1957 2 non-null float64
gdpPercap_1962 2 non-null float64
gdpPercap_1967 2 non-null float64
gdpPercap_1972 2 non-null float64
gdpPercap_1977 2 non-null float64
gdpPercap_1982 2 non-null float64
gdpPercap_1987 2 non-null float64
gdpPercap_1992 2 non-null float64
gdpPercap_1997 2 non-null float64
gdpPercap_2002 2 non-null float64
gdpPercap_2007 2 non-null float64
dtypes: float64(12)
memory usage: 208.0+ bytes- Dies ist ein
DataFrame - Zwei Zeilen mit den Namen
'Australia'und'New Zealand' - Zwölf Spalten, von denen jede zwei tatsächliche
64-Bit-Gleitkommawerte enthält.
- Wir werden später über Nullwerte sprechen, die zur Darstellung fehlender Beobachtungen verwendet werden.
- Benötigt 208 Bytes Speicherplatz.
Die Variable DataFrame.columns speichert Informationen
über die Spalten des DataFrames.
- Beachten Sie, dass es sich hierbei um Daten und nicht um
eine Methode handelt. (Es hat keine Klammern.)
- Wie
math.pi. - Verwenden Sie also nicht
(), um zu versuchen, es aufzurufen.
- Wie
- Wird als Mitgliedvariable oder einfach Mitglied bezeichnet.
AUSGABE
Index(['gdpPercap_1952', 'gdpPercap_1957', 'gdpPercap_1962', 'gdpPercap_1967',
'gdpPercap_1972', 'gdpPercap_1977', 'gdpPercap_1982', 'gdpPercap_1987',
'gdpPercap_1992', 'gdpPercap_1997', 'gdpPercap_2002', 'gdpPercap_2007'],
dtype='object')Verwenden Sie DataFrame.T, um einen DataFrame zu
transponieren.
- Manchmal möchte man Spalten als Zeilen behandeln und umgekehrt.
- Transponieren (geschrieben
.T) kopiert die Daten nicht, sondern ändert nur die Sichtweise des Programms darauf. - Wie
columnsist sie eine Mitgliedsvariable.
AUSGABE
country Australia New Zealand
gdpPercap_1952 10039.59564 10556.57566
gdpPercap_1957 10949.64959 12247.39532
gdpPercap_1962 12217.22686 13175.67800
gdpPercap_1967 14526.12465 14463.91893
gdpPercap_1972 16788.62948 16046.03728
gdpPercap_1977 18334.19751 16233.71770
gdpPercap_1982 19477.00928 17632.41040
gdpPercap_1987 21888.88903 19007.19129
gdpPercap_1992 23424.76683 18363.32494
gdpPercap_1997 26997.93657 21050.41377
gdpPercap_2002 30687.75473 23189.80135
gdpPercap_2007 34435.36744 25185.00911Verwenden Sie DataFrame.describe(), um zusammenfassende
Statistiken über Daten zu erhalten.
DataFrame.describe() liefert die zusammenfassende
Statistik nur für die Spalten, die numerische Daten enthalten. Alle
anderen Spalten werden ignoriert, es sei denn, Sie verwenden das
Argument include='all'.
AUSGABE
gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 gdpPercap_1967 \
count 2.000000 2.000000 2.000000 2.000000
mean 10298.085650 11598.522455 12696.452430 14495.021790
std 365.560078 917.644806 677.727301 43.986086
min 10039.595640 10949.649590 12217.226860 14463.918930
25% 10168.840645 11274.086022 12456.839645 14479.470360
50% 10298.085650 11598.522455 12696.452430 14495.021790
75% 10427.330655 11922.958888 12936.065215 14510.573220
max 10556.575660 12247.395320 13175.678000 14526.124650
gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 gdpPercap_1987 \
count 2.00000 2.000000 2.000000 2.000000
mean 16417.33338 17283.957605 18554.709840 20448.040160
std 525.09198 1485.263517 1304.328377 2037.668013
min 16046.03728 16233.717700 17632.410400 19007.191290
25% 16231.68533 16758.837652 18093.560120 19727.615725
50% 16417.33338 17283.957605 18554.709840 20448.040160
75% 16602.98143 17809.077557 19015.859560 21168.464595
max 16788.62948 18334.197510 19477.009280 21888.889030
gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 gdpPercap_2007
count 2.000000 2.000000 2.000000 2.000000
mean 20894.045885 24024.175170 26938.778040 29810.188275
std 3578.979883 4205.533703 5301.853680 6540.991104
min 18363.324940 21050.413770 23189.801350 25185.009110
25% 19628.685413 22537.294470 25064.289695 27497.598692
50% 20894.045885 24024.175170 26938.778040 29810.188275
75% 22159.406358 25511.055870 28813.266385 32122.777857
max 23424.766830 26997.936570 30687.754730 34435.367440- Nicht besonders nützlich bei nur zwei Datensätzen, aber sehr hilfreich, wenn es Tausende sind.
Andere Daten lesen
Lesen Sie die Daten in gapminder_gdp_americas.csv (die
sich im gleichen Verzeichnis wie gapminder_gdp_oceania.csv
befinden sollten) in eine Variable mit dem Namen
data_americas und zeigen Sie deren zusammenfassende
Statistik an.
Um eine CSV-Datei einzulesen, verwenden wir pd.read_csv
und übergeben ihr den Dateinamen
'data/gapminder_gdp_americas.csv'. Wir übergeben auch
wieder den Spaltennamen 'country' an den Parameter
index_col, um nach Ländern zu indizieren. Die
zusammenfassende Statistik kann mit der Methode
DataFrame.describe() angezeigt werden.
Inspektion der Daten
Nachdem du die Daten für Amerika gelesen hast, benutze
help(data_americas.head) und
help(data_americas.tail), um herauszufinden, was
DataFrame.head und DataFrame.tail tun.
- Welcher Methodenaufruf zeigt die ersten drei Zeilen dieser Daten an?
- Mit welchem Methodenaufruf werden die letzten drei Spalten dieser Daten angezeigt? (Hinweis: Möglicherweise müssen Sie Ihre Ansicht der Daten ändern.)
- Wir können uns die ersten fünf Zeilen von
data_americasansehen, indem wirdata_americas.head()ausführen, wodurch wir den Anfang des DataFrame sehen können. Wir können die Anzahl der Zeilen angeben, die wir sehen wollen, indem wir den Parameternin unserem Aufruf vondata_americas.head()angeben. Um die ersten drei Zeilen zu sehen, führen Sie aus:
AUSGABE
continent gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 \
country
Argentina Americas 5911.315053 6856.856212 7133.166023
Bolivia Americas 2677.326347 2127.686326 2180.972546
Brazil Americas 2108.944355 2487.365989 3336.585802
gdpPercap_1967 gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 \
country
Argentina 8052.953021 9443.038526 10079.026740 8997.897412
Bolivia 2586.886053 2980.331339 3548.097832 3156.510452
Brazil 3429.864357 4985.711467 6660.118654 7030.835878
gdpPercap_1987 gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 \
country
Argentina 9139.671389 9308.418710 10967.281950 8797.640716
Bolivia 2753.691490 2961.699694 3326.143191 3413.262690
Brazil 7807.095818 6950.283021 7957.980824 8131.212843
gdpPercap_2007
country
Argentina 12779.379640
Bolivia 3822.137084
Brazil 9065.800825- Um die letzten drei Zeilen von
data_americaszu überprüfen, würden wir den Befehlamericas.tail(n=3)verwenden, analog zuhead()wie oben. In diesem Fall wollen wir jedoch die letzten drei Spalten betrachten, also müssen wir unsere Ansicht ändern und danntail()verwenden. Dazu erstellen wir einen neuen DataFrame, in dem Zeilen und Spalten vertauscht sind:
Wir können dann die letzten drei Spalten von americas
betrachten, indem wir die letzten drei Zeilen von
americas_flipped betrachten:
AUSGABE
country Argentina Bolivia Brazil Canada Chile Colombia \
gdpPercap_1997 10967.3 3326.14 7957.98 28954.9 10118.1 6117.36
gdpPercap_2002 8797.64 3413.26 8131.21 33329 10778.8 5755.26
gdpPercap_2007 12779.4 3822.14 9065.8 36319.2 13171.6 7006.58
country Costa Rica Cuba Dominican Republic Ecuador ... \
gdpPercap_1997 6677.05 5431.99 3614.1 7429.46 ...
gdpPercap_2002 7723.45 6340.65 4563.81 5773.04 ...
gdpPercap_2007 9645.06 8948.1 6025.37 6873.26 ...
country Mexico Nicaragua Panama Paraguay Peru Puerto Rico \
gdpPercap_1997 9767.3 2253.02 7113.69 4247.4 5838.35 16999.4
gdpPercap_2002 10742.4 2474.55 7356.03 3783.67 5909.02 18855.6
gdpPercap_2007 11977.6 2749.32 9809.19 4172.84 7408.91 19328.7
country Trinidad and Tobago United States Uruguay Venezuela
gdpPercap_1997 8792.57 35767.4 9230.24 10165.5
gdpPercap_2002 11460.6 39097.1 7727 8605.05
gdpPercap_2007 18008.5 42951.7 10611.5 11415.8Dies zeigt die gewünschten Daten an, aber vielleicht möchten wir lieber drei Spalten statt drei Zeilen anzeigen lassen, also können wir es umdrehen:
Anmerkung: Wir hätten die oben genannten Befehle auch in einer einzigen Codezeile ausführen können, indem wir sie “verkettet” hätten:
Lesen von Dateien in anderen Verzeichnissen
Die Daten für Ihr aktuelles Projekt sind in einer Datei namens
microbes.csv gespeichert, die sich in einem Ordner namens
field_data befindet. Sie führen die Analyse in einem
Notizbuch mit dem Namen analysis.ipynb in einem
Schwesterordner namens thesis durch:
AUSGABE
your_home_directory
+-- field_data/
| +-- microbes.csv
+-- thesis/
+-- analysis.ipynbWelche(r) Wert(e) sollte(n) man an read_csv übergeben,
um microbes.csv in analysis.ipynb zu
lesen?
Wir müssen den Pfad zu der Datei, die uns interessiert, in dem Aufruf
von pd.read_csv angeben. Zunächst müssen wir mit “../” aus
dem Ordner thesis und dann mit “field_data/” in den Ordner
field_data “springen”. Dann können wir den Dateinamen
microbes.csv angeben. Das Ergebnis ist wie folgt:
Daten schreiben
Neben der Funktion read_csv zum Lesen von Daten aus
einer Datei, bietet Pandas eine Funktion to_csv zum
Schreiben von DataFrame in Dateien. Wenden Sie an, was Sie über das
Lesen von Dateien gelernt haben, und schreiben Sie einen Ihrer DataFrame
in eine Datei namens processed.csv. Du kannst
help benutzen, um Informationen darüber zu bekommen, wie
man to_csv benutzt.
Um den DataFrame data_americas in eine Datei mit dem
Namen processed.csv zu schreiben, führen Sie den folgenden
Befehl aus:
Um Hilfe zu read_csv oder to_csv zu
erhalten, können Sie z.B. ausführen:
Beachten Sie, dass help(to_csv) oder
help(pd.to_csv) einen Fehler auslöst! Das liegt daran, dass
to_csv keine globale Pandas-Funktion ist, sondern eine
Mitgliedsfunktion von DataFrames. Das bedeutet, dass man sie nur auf
einer Instanz eines DataFrames aufrufen kann, z.B.
data_americas.to_csv oder
data_oceania.to_csv
- Verwenden Sie die Pandas-Bibliothek, um grundlegende Statistiken aus tabellarischen Daten zu erhalten.
- Verwenden Sie
index_col, um anzugeben, daß die Werte einer Spalte als Zeilenüberschriften verwendet werden sollen. - Verwenden Sie
DataFrame.info, um mehr über einen DataFrame herauszufinden. - Die Variable
DataFrame.columnsspeichert Informationen über die Spalten des DataFrames. - Verwenden Sie
DataFrame.T, um einen DataFrame zu transponieren. - Verwenden Sie
DataFrame.describe, um zusammenfassende Statistiken über Daten zu erhalten.
Content from Pandas DatenFrames
Zuletzt aktualisiert am 2025-10-31 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich eine statistische Analyse von Tabellendaten durchführen?
Ziele
- Wähle einzelne Werte aus einem Pandas-DataFrame aus.
- Wähle ganze Zeilen oder ganze Spalten aus einem DataFrame aus.
- Wählen Sie in einer einzigen Operation eine Teilmenge von Zeilen und Spalten aus einem DataFrame aus.
- Wählen Sie eine Teilmenge eines DataFrames anhand eines einzigen booleschen Kriteriums aus.
Hinweis zu Pandas DataFrames/Series
Ein DataFrame ist eine Sammlung von Series; Der DataFrame ist die Art und Weise, wie Pandas eine Tabelle darstellt, und Series ist die Datenstruktur, die Pandas zur Darstellung einer Spalte verwendet.
Pandas baut auf der Numpy-Bibliothek auf, was in der Praxis bedeutet, dass die meisten der für Numpy-Arrays definierten Methoden auch für Pandas Series/DataFrames gelten.
Was Pandas so attraktiv macht, ist die leistungsfähige Schnittstelle für den Zugriff auf einzelne Datensätze der Tabelle, die korrekte Behandlung fehlender Werte und relationale Datenbankoperationen zwischen DataFrames.
Auswählen von Werten
Um auf einen Wert an der Position [i,j] eines DataFrame
zuzugreifen, haben wir zwei Möglichkeiten, je nachdem, was die Bedeutung
von i im Gebrauch ist. Erinnern Sie sich daran, dass ein
DataFrame einen Index zur Verfügung stellt, um die Zeilen der
Tabelle zu identifizieren; eine Zeile hat also sowohl eine
Position innerhalb der Tabelle als auch ein Label, das
ihren Eintrag im DataFrame eindeutig identifiziert.
Verwenden Sie DataFrame.iloc[..., ...], um Werte nach
ihrer (Eingangs-)Position auszuwählen
- Kann die Position durch einen numerischen Index angeben, analog zur 2D-Version der Zeichenauswahl in Zeichenketten.
PYTHON
import pandas as pd
data = pd.read_csv('data/gapminder_gdp_europe.csv', index_col='country')
print(data.iloc[0, 0])AUSGABE
1601.056136Benutzen Sie DataFrame.loc[..., ...], um Werte nach
ihrer (Eintrags-)Bezeichnung auszuwählen.
- Kann den Ort durch Zeilen- und/oder Spaltennamen angeben.
AUSGABE
1601.056136Verwenden Sie : allein, um alle Spalten oder alle
Zeilen zu meinen.
- Genau wie die übliche Python-Slicing-Notation.
AUSGABE
gdpPercap_1952 1601.056136
gdpPercap_1957 1942.284244
gdpPercap_1962 2312.888958
gdpPercap_1967 2760.196931
gdpPercap_1972 3313.422188
gdpPercap_1977 3533.003910
gdpPercap_1982 3630.880722
gdpPercap_1987 3738.932735
gdpPercap_1992 2497.437901
gdpPercap_1997 3193.054604
gdpPercap_2002 4604.211737
gdpPercap_2007 5937.029526
Name: Albania, dtype: float64- Würde das gleiche Ergebnis liefern, wenn man
data.loc["Albania"](ohne zweiten Index) ausgibt.
AUSGABE
country
Albania 1601.056136
Austria 6137.076492
Belgium 8343.105127
⋮ ⋮ ⋮
Switzerland 14734.232750
Turkey 1969.100980
United Kingdom 9979.508487
Name: gdpPercap_1952, dtype: float64- Würde das gleiche Ergebnis erhalten, wenn man
data["gdpPercap_1952"]ausgibt - Das gleiche Ergebnis erhält man auch, wenn man
data.gdpPercap_1952ausdruckt (nicht empfohlen, da leicht mit der Notation.für Methoden zu verwechseln)
Wählen Sie mehrere Spalten oder Zeilen mit
DataFrame.loc und einem benannten Slice.
AUSGABE
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy 8243.582340 10022.401310 12269.273780
Montenegro 4649.593785 5907.850937 7778.414017
Netherlands 12790.849560 15363.251360 18794.745670
Norway 13450.401510 16361.876470 18965.055510
Poland 5338.752143 6557.152776 8006.506993Im obigen Code stellen wir fest, dass Slicing unter
Verwendung von loc an beiden Enden inklusiv ist,
was sich von Slicing unter Verwendung von
iloc unterscheidet, bei dem Slicing alles bis zum
letzten Index, aber nicht einschließlich, anzeigt.
Das Ergebnis der Zerlegung kann in weiteren Operationen verwendet werden.
- Normalerweise druckt man nicht nur einen Ausschnitt.
- Alle statistischen Operatoren, die auf ganze DataFrame angewendet werden, funktionieren auf die gleiche Weise auf Slices.
- Berechne z.B. den Maximalwert eines Slice.
AUSGABE
gdpPercap_1962 13450.40151
gdpPercap_1967 16361.87647
gdpPercap_1972 18965.05551
dtype: float64AUSGABE
gdpPercap_1962 4649.593785
gdpPercap_1967 5907.850937
gdpPercap_1972 7778.414017
dtype: float64Verwende Vergleiche, um Daten nach ihrem Wert auszuwählen.
- Der Vergleich wird Element für Element durchgeführt.
- Gibt einen ähnlich geformten DataFrame von
TrueundFalsezurück.
PYTHON
# Use a subset of data to keep output readable.
subset = data.loc['Italy':'Poland', 'gdpPercap_1962':'gdpPercap_1972']
print('Subset of data:\n', subset)
# Which values were greater than 10000 ?
print('\nWhere are values large?\n', subset > 10000)AUSGABE
Subset of data:
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy 8243.582340 10022.401310 12269.273780
Montenegro 4649.593785 5907.850937 7778.414017
Netherlands 12790.849560 15363.251360 18794.745670
Norway 13450.401510 16361.876470 18965.055510
Poland 5338.752143 6557.152776 8006.506993
Where are values large?
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy False True True
Montenegro False False False
Netherlands True True True
Norway True True True
Poland False False FalseWähle Werte oder NaN mit einer booleschen Maske.
- Ein Rahmen voller Boolescher Operatoren wird manchmal als Maske bezeichnet, weil er so verwendet werden kann.
AUSGABE
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy NaN 10022.40131 12269.27378
Montenegro NaN NaN NaN
Netherlands 12790.84956 15363.25136 18794.74567
Norway 13450.40151 16361.87647 18965.05551
Poland NaN NaN NaN- Ermittelt den Wert, wenn die Maske wahr ist, und NaN (Not a Number), wenn sie falsch ist.
- Nützlich, weil NaNs von Operationen wie max, min, Durchschnitt usw. ignoriert werden.
AUSGABE
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
count 2.000000 3.000000 3.000000
mean 13120.625535 13915.843047 16676.358320
std 466.373656 3408.589070 3817.597015
min 12790.849560 10022.401310 12269.273780
25% 12955.737547 12692.826335 15532.009725
50% 13120.625535 15363.251360 18794.745670
75% 13285.513523 15862.563915 18879.900590
max 13450.401510 16361.876470 18965.055510Gruppieren nach: split-apply-combine
Pandas Vektorisierungsmethoden und Gruppierungsoperationen sind Funktionen, die Benutzern viel Flexibilität bei der Analyse ihrer Daten bieten.
Nehmen wir zum Beispiel an, dass wir einen besseren Überblick darüber haben wollen, wie sich die europäischen Länder nach ihrem BIP aufteilen.
- Wir können uns einen Überblick verschaffen, indem wir die Länder in den untersuchten Jahren in zwei Gruppen aufteilen: diejenigen, die ein BIP höher als der europäische Durchschnitt aufweisen, und diejenigen mit einem niedrigeren BIP.
- Wir schätzen dann einen Wohlstandsscore auf der Grundlage der historischen Werte (von 1962 bis 2007), wobei wir berücksichtigen, wie oft ein Land an den Gruppen mit geringerem oder höherem BIP teilgenommen hat
PYTHON
mask_higher = data > data.mean()
wealth_score = mask_higher.aggregate('sum', axis=1) / len(data.columns)
print(wealth_score)AUSGABE
country
Albania 0.000000
Austria 1.000000
Belgium 1.000000
Bosnia and Herzegovina 0.000000
Bulgaria 0.000000
Croatia 0.000000
Czech Republic 0.500000
Denmark 1.000000
Finland 1.000000
France 1.000000
Germany 1.000000
Greece 0.333333
Hungary 0.000000
Iceland 1.000000
Ireland 0.333333
Italy 0.500000
Montenegro 0.000000
Netherlands 1.000000
Norway 1.000000
Poland 0.000000
Portugal 0.000000
Romania 0.000000
Serbia 0.000000
Slovak Republic 0.000000
Slovenia 0.333333
Spain 0.333333
Sweden 1.000000
Switzerland 1.000000
Turkey 0.000000
United Kingdom 1.000000
dtype: float64Schließlich wird für jede Gruppe in der Tabelle
wealth_score ihr (finanzieller) Beitrag über die
untersuchten Jahre mit Hilfe verketteter Methoden summiert:
AUSGABE
gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 gdpPercap_1967 \
0.000000 36916.854200 46110.918793 56850.065437 71324.848786
0.333333 16790.046878 20942.456800 25744.935321 33567.667670
0.500000 11807.544405 14505.000150 18380.449470 21421.846200
1.000000 104317.277560 127332.008735 149989.154201 178000.350040
gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 gdpPercap_1987 \
0.000000 88569.346898 104459.358438 113553.768507 119649.599409
0.333333 45277.839976 53860.456750 59679.634020 64436.912960
0.500000 25377.727380 29056.145370 31914.712050 35517.678220
1.000000 215162.343140 241143.412730 263388.781960 296825.131210
gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 gdpPercap_2007
0.000000 92380.047256 103772.937598 118590.929863 149577.357928
0.333333 67918.093220 80876.051580 102086.795210 122803.729520
0.500000 36310.666080 40723.538700 45564.308390 51403.028210
1.000000 315238.235970 346930.926170 385109.939210 427850.333420Auswahl der einzelnen Werte
Angenommen, Pandas wurde in Ihr Notebook importiert und die Gapminder-BIP-Daten für Europa wurden geladen:
PYTHON
import pandas as pd
data_europe = pd.read_csv('data/gapminder_gdp_europe.csv', index_col='country')Schreiben Sie einen Ausdruck, um das Pro-Kopf-BIP von Serbien im Jahr 2007 zu ermitteln.
Ausmaß des Slicings
Nein, sie erzeugen nicht die gleiche Ausgabe! Die Ausgabe der ersten Anweisung ist:
AUSGABE
gdpPercap_1952 gdpPercap_1957
country
Albania 1601.056136 1942.284244
Austria 6137.076492 8842.598030Die zweite Anweisung ergibt:
AUSGABE
gdpPercap_1952 gdpPercap_1957 gdpPercap_1962
country
Albania 1601.056136 1942.284244 2312.888958
Austria 6137.076492 8842.598030 10750.721110
Belgium 8343.105127 9714.960623 10991.206760Es ist offensichtlich, dass die zweite Anweisung eine zusätzliche
Spalte und eine zusätzliche Zeile im Vergleich zur ersten Anweisung
erzeugt.
Welche Schlussfolgerung können wir ziehen? Wir sehen, dass ein
numerisches Slice, 0:2, den letzten Index (d. h. Index 2) in dem
angegebenen Bereich ausschließt, während ein benanntes Slice,
‘gdpPercap_1952’:‘gdpPercap_1962’, das letzte Element
einschließt.
Daten rekonstruieren
Erkläre, was jede Zeile in dem folgenden kurzen Programm macht: was
steht in first, second, usw.?
Gehen wir diesen Teil des Codes Zeile für Zeile durch.
Diese Zeile lädt den Datensatz mit den BIP-Daten aller Länder in
einen DataFrame mit der Bezeichnung first. Der Parameter
index_col='country' wählt aus, welche Spalte als
Zeilenbeschriftung im DataFrame verwendet werden soll.
In dieser Zeile wird eine Auswahl getroffen: Es werden nur die Zeilen
von first extrahiert, bei denen die Spalte “continent” mit
“Americas” übereinstimmt. Beachten Sie, dass der boolesche Ausdruck in
den eckigen Klammern, first['continent'] == 'Americas',
verwendet wird, um nur die Zeilen auszuwählen, in denen der Ausdruck
wahr ist. Versuchen Sie, diesen Ausdruck zu drucken! Können Sie auch die
einzelnen Wahr/Falsch-Elemente ausdrucken? (Hinweis: Weisen Sie den
Ausdruck zunächst einer Variablen zu)
Wie die Syntax vermuten lässt, wird in dieser Zeile die Zeile von
second mit der Bezeichnung “Puerto Rico” gelöscht. Der
resultierende DataFrame third hat eine Zeile weniger als
der ursprüngliche DataFrame second.
Auch hier wenden wir die Drop-Funktion an, aber in diesem Fall lassen
wir nicht eine Zeile, sondern eine ganze Spalte fallen. Um dies zu
erreichen, müssen wir auch den Parameter axis angeben (wir
wollen die zweite Spalte mit dem Index 1 löschen).
Der letzte Schritt besteht darin, die Daten, an denen wir gearbeitet
haben, in eine csv-Datei zu schreiben. Pandas macht dies mit der
Funktion to_csv() einfach. Das einzige erforderliche
Argument für die Funktion ist der Dateiname. Beachten Sie, dass die
Datei in das Verzeichnis geschrieben wird, von dem aus Sie die Jupyter-
oder Python-Sitzung gestartet haben.
Für jede Spalte in data gibt idxmin den
Indexwert zurück, der dem Minimum jeder Spalte entspricht;
idxmax tut das Gleiche für den Maximalwert jeder
Spalte.
Sie können diese Funktionen immer dann verwenden, wenn Sie den Zeilenindex des Minimal-/Maximalwerts und nicht den tatsächlichen Minimal-/Maximalwert erhalten möchten.
Übung mit der Auswahl
Angenommen, Pandas wurde importiert und die Gapminder-BIP-Daten für Europa wurden geladen. Schreiben Sie einen Ausdruck, um jedes der folgenden Elemente auszuwählen:
- Pro-Kopf-BIP für alle Länder im Jahr 1982.
- BIP pro Kopf für Dänemark für alle Jahre.
- BIP pro Kopf für alle Länder für die Jahre nach 1985.
- Das Pro-Kopf-BIP für jedes Land im Jahr 2007 als Vielfaches des Pro-Kopf-BIP für dieses Land im Jahr 1952.
1:
2:
3:
Pandas ist intelligent genug, um die Zahl am Ende der
Spaltenbezeichnung zu erkennen und gibt keinen Fehler aus, obwohl keine
Spalte mit dem Namen gdpPercap_1985 existiert. Dies ist
nützlich, wenn der CSV-Datei später neue Spalten hinzugefügt werden.
4:
Viele Möglichkeiten des Zugriffs
Es gibt mindestens zwei Möglichkeiten, auf einen Wert oder ein Slice
eines DataFrame zuzugreifen: über den Namen oder den Index. Es gibt
jedoch noch viele andere. Zum Beispiel kann auf eine einzelne Spalte
oder Zeile entweder als DataFrame oder als
Series Objekt zugegriffen werden.
Schlagen Sie verschiedene Möglichkeiten vor, die folgenden Operationen mit einem DataFrame durchzuführen:
- Zugriff auf eine einzelne Spalte
- Zugriff auf eine einzelne Zeile
- Zugriff auf ein einzelnes DataFrame-Element
- Zugriff auf mehrere Spalten
- Zugriff auf mehrere Zeilen
- Zugriff auf eine Teilmenge von bestimmten Zeilen und Spalten
- Zugriff auf eine Teilmenge von Zeilen- und Spaltenbereichen
1. Zugriff auf eine einzelne Spalte:
PYTHON
# by name
data["col_name"] # as a Series
data[["col_name"]] # as a DataFrame
# by name using .loc
data.T.loc["col_name"] # as a Series
data.T.loc[["col_name"]].T # as a DataFrame
# Dot notation (Series)
data.col_name
# by index (iloc)
data.iloc[:, col_index] # as a Series
data.iloc[:, [col_index]] # as a DataFrame
# using a mask
data.T[data.T.index == "col_name"].T2. Zugriff auf eine einzelne Zeile:
PYTHON
# by name using .loc
data.loc["row_name"] # as a Series
data.loc[["row_name"]] # as a DataFrame
# by name
data.T["row_name"] # as a Series
data.T[["row_name"]].T # as a DataFrame
# by index
data.iloc[row_index] # as a Series
data.iloc[[row_index]] # as a DataFrame
# using mask
data[data.index == "row_name"]3. Greife auf ein einzelnes DataFrame-Element zu:
PYTHON
# by column/row names
data["column_name"]["row_name"] # als Series
data[["col_name"]].loc["row_name"] # als Series
data[["col_name"]].loc[["row_name"]] # als DataFrame
data.loc["row_name"]["col_name"] # als Wert
data.loc[["row_name"]]["col_name"] # als Series
data.loc[["row_name"]][["col_name"]] # als DataFrame
data.loc["row_name", "col_name"] # als Wert
data.loc[["row_name"], "col_name"] # Series. Behält den Index bei. Der Spaltenname wird nach `.name` verschoben.
data.loc["row_name", ["col_name"]] # als Series. Der Index wird nach „.name.“ verschoben. Setzt den Index auf den Spaltennamen.
data.loc[["row_name"], ["col_name"]] # als DataFrame (behält den ursprünglichen Index und Spaltennamen bei)
# by column/row names: Dot notation
data.col_name.row_name
# by column/row indices
data.iloc[row_index, col_index] # als Wert
data.iloc[[row_index], col_index] # # Series. Behält den Index bei. Der Spaltenname wird nach `.name` verschoben.
data.iloc[row_index, [col_index]] # als Series. Der Index wird nach „.name.“ verschoben. Setzt den Index auf den Spaltennamen.
data.iloc[[row_index], [col_index]] # # als DataFrame (behält den ursprünglichen Index und Spaltennamen bei)
# column name + row index
data["col_name"][row_index]
data.col_name[row_index]
data["col_name"].iloc[row_index]
# column index + row name
data.iloc[:, [col_index]].loc["row_name"] # alsSeries
data.iloc[:, [col_index]].loc[["row_name"]] # als DataFrame
# using masks
data[data.index == "row_name"].T[data.T.index == "col_name"].T4. Zugriff auf mehrere Spalten:
PYTHON
# by name
data[["col1", "col2", "col3"]]
data.loc[:, ["col1", "col2", "col3"]]
# by index
data.iloc[:, [col1_index, col2_index, col3_index]]5. Zugriff auf mehrere Zeilen
PYTHON
# by name
data.loc[["row1", "row2", "row3"]]
# by index
data.iloc[[row1_index, row2_index, row3_index]]6. Zugriff auf eine Teilmenge von bestimmten Zeilen und Spalten
PYTHON
# by names
data.loc[["row1", "row2", "row3"], ["col1", "col2", "col3"]]
# by indices
data.iloc[[row1_index, row2_index, row3_index], [col1_index, col2_index, col3_index]]
# column names + row indices
data[["col1", "col2", "col3"]].iloc[[row1_index, row2_index, row3_index]]
# column indices + row names
data.iloc[:, [col1_index, col2_index, col3_index]].loc[["row1", "row2", "row3"]]7. Zugriff auf eine Teilmenge von Zeilen- und Spaltenbereichen
PYTHON
# nach Namen
data.loc["row1":"row2", "col1":"col2"]
# nach index
data.iloc[row1_index:row2_index, col1_index:col2_index]
# column names + row indices
data.loc[:, "col1_name":"col2_name"].iloc[row1_index:row2_index]
# column indices + row names
data.iloc[:, col1_index:col2_index].loc["row1":"row2"]Untersuchung der verfügbaren Methoden mit der
Funktion dir()
Python enthält eine Funktion dir(), mit der man alle
verfügbaren Methoden (Funktionen) anzeigen kann, die in ein Datenobjekt
eingebaut sind. In Episode 4 haben wir einige Methoden mit einer
Zeichenkette verwendet. Aber wir können sehen, dass noch viel mehr
verfügbar sind, wenn wir dir() benutzen:
Dieser Befehl gibt zurück:
PYTHON
['__add__',
...
'__subclasshook__',
'capitalize',
'casefold',
'center',
...
'upper',
'zfill']Sie können help() oder
Shift+Tab verwenden, um mehr Informationen
darüber zu erhalten, was diese Methoden tun.
Angenommen, Pandas wurde importiert und die Gapminder-BIP-Daten für
Europa wurden als data geladen. Verwenden Sie dann
dir(), um die Funktion zu finden, die den Median des
Pro-Kopf-BIP aller europäischen Länder für jedes Jahr, für das
Informationen verfügbar sind, ausgibt.
Interpretation
Die Grenzen Polens sind seit 1945 stabil, haben sich aber in den Jahren davor mehrmals geändert. Wie würden Sie dies handhaben, wenn Sie eine Tabelle des Pro-Kopf-BIP für Polen für das gesamte zwanzigste Jahrhundert erstellen würden?
- Benutze
DataFrame.iloc[..., ...], um Werte nach ganzzahliger Position auszuwählen. - Benutze
:allein, um alle Spalten oder alle Zeilen zu meinen. - Wähle mehrere Spalten oder Zeilen mit
DataFrame.locund einem benannten Slice. - Das Ergebnis der Zerlegung kann in weiteren Operationen verwendet werden.
- Verwende Vergleiche, um Daten nach ihrem Wert auszuwählen.
- Wähle Werte oder NaN mit Hilfe einer booleschen Maske.
Content from Plotten
Zuletzt aktualisiert am 2025-10-31 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich meine Daten darstellen?
- Wie kann ich meinen Plot für die Veröffentlichung speichern?
Ziele
- Erstellt ein Zeitseriendiagramm mit einem einzelnen Datensatz.
- Erstellt ein Streudiagramm, das die Beziehung zwischen zwei Datensätzen zeigt.
matplotlib ist
die am weitesten verbreitete wissenschaftliche Plotting-Bibliothek in
Python.
- Üblicherweise wird eine Unterbibliothek namens
matplotlib.pyplotverwendet. - Das Jupyter Notebook rendert Plots standardmäßig inline.
- Einfache Diagramme sind dann (relativ) einfach zu erstellen.
PYTHON
time = [0, 1, 2, 3]
position = [0, 100, 200, 300]
plt.plot(time, position)
plt.xlabel('Time (hr)')
plt.ylabel('Position (km)')
Alle offenen Abbildungen anzeigen
In unserem Jupyter-Notebook-Beispiel sollte das Ausführen der Zelle die Abbildung direkt unterhalb des Codes erzeugen. Die Abbildung wird auch in das Notebook-Dokument aufgenommen und kann später betrachtet werden. Andere Python-Umgebungen wie eine interaktive Python-Sitzung, die von einem Terminal aus gestartet wird, oder ein Python-Skript, das über die Kommandozeile ausgeführt wird, erfordern jedoch einen zusätzlichen Befehl, um die Abbildung anzuzeigen.
Weist matplotlib an, eine Abbildung darzustellen:
Dieser Befehl kann auch innerhalb eines Notizbuchs verwendet werden - zum Beispiel, um mehrere Zahlen anzuzeigen, wenn mehrere von einer einzigen Zelle erstellt wurden.
Plotten von Daten direkt aus einem Pandas dataframe.
- Wir können auch Pandas dataframes plotten.
- Vor dem Plotten konvertieren wir die Spaltenüberschriften von einem
string-Datentyp ininteger, da sie numerische Werte darstellen, indem wir str.replace() verwenden, um das PräfixgpdPercap_zu entfernen, und dann astype(int), um die Reihe von String-Werten (['1952', '1957', ..., '2007']) in eine Reihe von Ganzzahlen zu konvertieren:[1925, 1957, ..., 2007].
PYTHON
import pandas as pd
data = pd.read_csv('data/gapminder_gdp_oceania.csv', index_col='country')
# Extract year from last 4 characters of each column name
# The current column names are structured as 'gdpPercap_(year)',
# so we want to keep the (year) part only for clarity when plotting GDP vs. years
# To do this we use replace(), which removes from the string the characters stated in the argument
# This method works on strings, so we use replace() from Pandas Series.str vectorized string functions
years = data.columns.str.replace('gdpPercap_', '')
# Convert year values to integers, saving results back to dataframe
data.columns = years.astype(int)
data.loc['Australia'].plot()
Wählen Sie Daten aus, transformieren Sie sie und stellen Sie sie dann dar.
- Standardmäßig zeichnet
DataFrame.plotmit den Zeilen als X-Achse. - Wir können die Daten transponieren, um mehrere Reihen zu zeichnen.

Es stehen viele Darstellungsarten zur Verfügung.
- Erstellen Sie z. B. ein Balkendiagramm mit einem ausgefeilteren Stil.

Daten können auch durch direkten Aufruf der Funktion
matplotlib plot geplottet werden.
- Der Befehl lautet
plt.plot(x, y) - Die Farbe und das Format der Marker können auch als zusätzliches
optionales Argument angegeben werden, z.B.
b-ist eine blaue Linie,g--ist eine grüne gestrichelte Linie.
Holt Australien-Daten aus dem Datenrahmen
PYTHON
years = data.columns
gdp_australia = data.loc['Australia']
plt.plot(years, gdp_australia, 'g--')
Kann viele Datensätze zusammen darstellen.
PYTHON
# Select two countries' worth of data.
gdp_australia = data.loc['Australia']
gdp_nz = data.loc['New Zealand']
# Plot with differently-colored markers.
plt.plot(years, gdp_australia, 'b-', label='Australia')
plt.plot(years, gdp_nz, 'g-', label='New Zealand')
# Create legend.
plt.legend(loc='upper left')
plt.xlabel('Year')
plt.ylabel('GDP per capita ($)')Hinzufügen einer Legende
Beim Plotten mehrerer Datensätze auf derselben Abbildung ist es oft wünschenswert, eine Legende zur Beschreibung der Daten zu haben.
Dies kann in matplotlib in zwei Stufen erfolgen:
- Geben Sie eine Beschriftung für jeden Datensatz in der Abbildung an:
PYTHON
plt.plot(years, gdp_australia, label='Australia')
plt.plot(years, gdp_nz, label='New Zealand')- Weist
matplotliban, die Legende zu erstellen.
Standardmäßig versucht matplotlib, die Legende an einer geeigneten
Stelle zu platzieren. Wenn Sie lieber eine Position angeben möchten,
können Sie dies mit dem Argument loc= tun, z.B. um die
Legende in der oberen linken Ecke des Plots zu platzieren, geben Sie
loc='upper left' an

- Plotten eines Streudiagramms, das das BIP von Australien und Neuseeland in Beziehung setzt
- Verwenden Sie entweder
plt.scatteroderDataFrame.plot.scatter


Minima und Maxima
Füllen Sie die folgenden Felder aus, um das minimale Pro-Kopf-BIP aller europäischen Länder im Zeitverlauf darzustellen. Ändern Sie das Diagramm erneut, um das maximale Pro-Kopf-BIP für Europa im Zeitverlauf darzustellen.
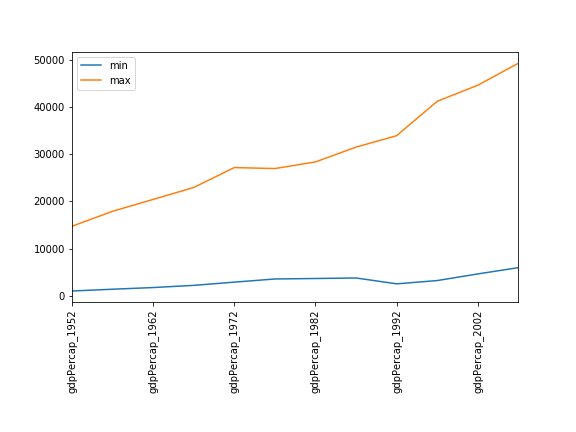
Korrelationen
Ändern Sie das Beispiel in den Anmerkungen, um ein Streudiagramm zu erstellen, das die Beziehung zwischen dem minimalen und maximalen Pro-Kopf-BIP der asiatischen Länder für jedes Jahr im Datensatz zeigt. Welche Beziehung sehen Sie (wenn überhaupt)?
PYTHON
data_asia = pd.read_csv('data/gapminder_gdp_asia.csv', index_col='country')
data_asia.describe().T.plot(kind='scatter', x='min', y='max')
Es sind keine besonderen Korrelationen zwischen den Mindest- und Höchstwerten des BIP von Jahr zu Jahr zu erkennen. Es scheint, als ob die Geschicke der asiatischen Länder nicht gemeinsam steigen und fallen.
Korrelationen (continued)
Sie werden feststellen, dass die Variabilität des Maximums viel größer ist als die des Minimums. Schauen Sie sich die Indizes Maximum und Maximum an:
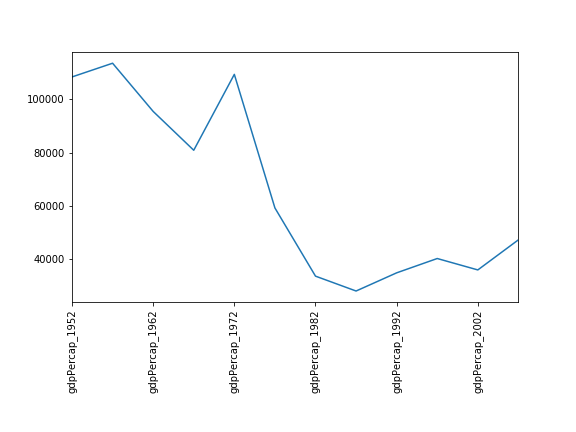
Es scheint, dass die Schwankungen in diesem Wert auf einen starken Rückgang nach 1972 zurückzuführen sind. Vielleicht sind geopolitische Gründe im Spiel? Angesichts der Dominanz der Erdöl produzierenden Länder wäre vielleicht der Brent-Rohöl-Index ein interessanter Vergleich? Während Myanmar durchweg das niedrigste BIP aufweist, sind die Schwankungen bei der Nation mit dem höchsten BIP noch ausgeprägter.
Weitere Korrelationen
Dieses kurze Programm erstellt ein Diagramm, das die Korrelation zwischen dem BIP und der Lebenserwartung für das Jahr 2007 zeigt, wobei die Markergröße durch die Bevölkerung normalisiert wird:
PYTHON
data_all = pd.read_csv('data/gapminder_all.csv', index_col='country')
data_all.plot(kind='scatter', x='gdpPercap_2007', y='lifeExp_2007',
s=data_all['pop_2007']/1e6)Erläutern Sie anhand der Online-Hilfe und anderer Quellen, was die
einzelnen Argumente von plot bewirken.

Eine gute Anlaufstelle ist die Dokumentation für die Plot-Funktion - help(data_all.plot).
kind - Wie bereits gesehen, bestimmt dies die Art der Darstellung, die gezeichnet werden soll.
x und y - Ein Spaltenname oder Index, der bestimmt, welche Daten auf der x- und y-Achse des Diagramms platziert werden sollen
s - Details dazu finden Sie in der Dokumentation von plt.scatter. Eine einzelne Zahl oder ein Wert für jeden Datenpunkt. Bestimmt die Größe der gezeichneten Punkte.
Speichern der Darstellung in einer Datei
Wenn Sie mit der Darstellung zufrieden sind, möchten Sie sie vielleicht in einer Datei speichern, um sie in eine Veröffentlichung aufzunehmen. Im Modul matplotlib.pyplot gibt es eine Funktion, mit der dies möglich ist: savefig. Der Aufruf dieser Funktion, z.B. mit
speichert die aktuelle Abbildung in der Datei
my_figure.png. Das Dateiformat wird automatisch aus der
Dateinamenerweiterung abgeleitet (andere Formate sind pdf, ps, eps und
svg).
Beachten Sie, dass die Funktionen in plt auf eine
globale Abbildungvariable verweisen. Nachdem eine Abbildung auf dem
Bildschirm angezeigt wurde (z.B. mit plt.show), wird
matplotlib diese Variable auf eine neue leere Abbildung verweisen
lassen. Stellen Sie daher sicher, dass Sie plt.savefig
aufrufen, bevor der Plot auf dem Bildschirm angezeigt wird, sonst
könnten Sie eine Datei mit einem leeren Plot vorfinden.
Bei der Verwendung von Datenrahmen werden die Daten oft in einer
einzigen Zeile erzeugt und auf dem Bildschirm dargestellt. Zusätzlich
zur Verwendung von plt.savefig können wir einen Verweis auf
die aktuelle Abbildung in einer lokalen Variablen (mit
plt.gcf) speichern und die Klassenmethode
savefig von dieser Variablen aus aufrufen, um die Abbildung
in einer Datei zu speichern.
Zugänglich machen von Plots
Wenn Sie Diagramme für ein Papier oder eine Präsentation erstellen, gibt es ein paar Dinge, die Sie tun können, um sicherzustellen, dass jeder Ihre Diagramme verstehen kann.
- Stellen Sie immer sicher, dass Ihr Text groß genug ist, um ihn zu
lesen. Verwenden Sie den Parameter
fontsizeinxlabel,ylabel,titleundlegend, undtick_paramsmitlabelsize, um die Textgröße der Zahlen auf Ihren Achsen zu erhöhen. - In ähnlicher Weise sollten Sie die Elemente Ihres Graphen gut
sichtbar machen. Benutzen Sie
s, um die Größe Ihrer Streudiagramm-Markierungen zu erhöhen undlinewidth, um die Größe Ihrer Diagrammlinien zu erhöhen. - Die Verwendung von Farbe (und nichts anderem) zur Unterscheidung
zwischen verschiedenen Plot-Elementen macht Ihre Plots unlesbar für
jeden, der farbenblind ist oder zufällig einen Schwarz-Weiß-Bürodrucker
hat. Für Linien können Sie mit dem Parameter
linestyleverschiedene Linientypen verwenden. Bei Streudiagrammen können Sie mitmarkerdie Form der Punkte ändern. Wenn Sie sich mit den Farben nicht sicher sind, können Sie Coblis oder Color Oracle verwenden, um zu simulieren, wie Ihre Diagramme für Menschen mit Farbenblindheit aussehen würden.
-
matplotlibist die am weitesten verbreitete wissenschaftliche Plotting-Bibliothek in Python. - Plotten von Daten direkt aus einem Pandas-Datenframe.
- Wählen Sie Daten aus, transformieren Sie sie und stellen Sie sie dann dar.
- Es stehen viele Darstellungsarten zur Verfügung: Weitere Optionen finden Sie in der Python Graph Gallery.
- Kann viele Datensätze zusammen darstellen.
Content from Mittagessen
Zuletzt aktualisiert am 2025-03-02 | Diese Seite bearbeiten
Denken Sie während des Mittagessens über die folgenden Punkte nach und diskutieren Sie sie:
- Welche Art von Paketen könnten Sie in Python verwenden und warum würden Sie sie verwenden?
- Wie müssten die Daten formatiert werden, um in Pandas Datenrahmen verwendet werden zu können? Würden die Daten, die Sie haben, diese Anforderungen erfüllen?
- Auf welche Einschränkungen oder Probleme könntest du stoßen, wenn du darüber nachdenkst, wie du das Gelernte auf deine eigenen Projekte oder Daten anwenden kannst?
Content from Listen
Zuletzt aktualisiert am 2025-10-31 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich mehrere Werte speichern?
Ziele
- Erklären Sie, warum Programme Wertesammlungen benötigen.
- Programme schreiben, die flache Listen erstellen, indizieren, zerschneiden und durch Zuweisungen und Methodenaufrufe modifizieren.
Eine Liste speichert viele Werte in einer einzigen Struktur.
- Berechnungen mit hundert Variablen, die
pressure_001,pressure_002, usw. heißen, wären mindestens so langsam wie die manuelle Berechnung. - Verwenden Sie eine Liste, um viele Werte zusammen zu
speichern.
- Enthält Werte innerhalb eckiger Klammern
[...]. - Werte sind durch Kommata
,getrennt.
- Enthält Werte innerhalb eckiger Klammern
- Verwenden Sie
len, um herauszufinden, wie viele Werte in einer Liste sind.
PYTHON
pressures = [0.273, 0.275, 0.277, 0.275, 0.276]
print('pressures:', pressures)
print('length:', len(pressures))AUSGABE
pressures: [0.273, 0.275, 0.277, 0.275, 0.276]
length: 5Verwenden Sie den Index eines Elements, um es aus einer Liste zu holen.
- Genau wie Zeichenketten.
PYTHON
print('zeroth item of pressures:', pressures[0])
print('fourth item of pressures:', pressures[4])AUSGABE
zeroth item of pressures: 0.273
fourth item of pressures: 0.276Die Werte von Listen können durch Zuweisungen ersetzt werden.
- Verwenden Sie einen Indexausdruck auf der linken Seite der Zuweisung, um einen Wert zu ersetzen.
AUSGABE
pressures is now: [0.265, 0.275, 0.277, 0.275, 0.276]Das Anhängen von Elementen an eine Liste verlängert diese.
- Verwenden Sie
list_name.append, um Elemente am Ende einer Liste hinzuzufügen.
PYTHON
primes = [2, 3, 5]
print('primes is initially:', primes)
primes.append(7)
print('primes has become:', primes)AUSGABE
primes is initially: [2, 3, 5]
primes has become: [2, 3, 5, 7]-
appendist eine Methode von Listen.- Wie eine Funktion, aber an ein bestimmtes Objekt gebunden.
- Verwenden Sie
object_name.method_name, um Methoden aufzurufen.- ähnelt absichtlich der Art und Weise, wie wir in einer Bibliothek auf Dinge verweisen.
- Wir werden im weiteren Verlauf weitere Methoden für Listen
kennenlernen.
- Verwenden Sie
help(list)für eine Vorschau.
- Verwenden Sie
-
extendist ähnlich wieappend, erlaubt es aber, zwei Listen zu kombinieren. Zum Beispiel:
PYTHON
teen_primes = [11, 13, 17, 19]
middle_aged_primes = [37, 41, 43, 47]
print('primes is currently:', primes)
primes.extend(teen_primes)
print('primes has now become:', primes)
primes.append(middle_aged_primes)
print('primes has finally become:', primes)AUSGABE
primes is currently: [2, 3, 5, 7]
primes has now become: [2, 3, 5, 7, 11, 13, 17, 19]
primes has finally become: [2, 3, 5, 7, 11, 13, 17, 19, [37, 41, 43, 47]]Beachten Sie, dass extend zwar die “flache” Struktur der
Liste beibehält, aber das Anhängen einer Liste an eine Liste bedeutet,
dass das letzte Element in primes selbst eine Liste und
keine Ganzzahl ist. Listen können Werte beliebigen Typs enthalten; daher
sind auch Listen von Listen möglich.
Verwenden Sie del, um Elemente aus einer Liste
vollständig zu entfernen.
- Wir verwenden
del list_name[index], um ein Element aus einer Liste zu entfernen (im Beispiel ist 9 keine Primzahl) und sie damit zu kürzen. -
delist keine Funktion oder Methode, sondern eine Anweisung in der Sprache.
PYTHON
primes = [2, 3, 5, 7, 9]
print('primes before removing last item:', primes)
del primes[4]
print('primes after removing last item:', primes)AUSGABE
primes before removing last item: [2, 3, 5, 7, 9]
primes after removing last item: [2, 3, 5, 7]Die leere Liste enthält keine Werte.
- Verwenden Sie
[]allein, um eine Liste darzustellen, die keine Werte enthält.- “Die Null der Listen.”
- Hilfreich als Ausgangspunkt für die Sammlung von Werten (die wir in der nächsten Folge sehen werden).
Listen können Werte unterschiedlichen Typs enthalten.
- Eine einzelne Liste kann Zahlen, Zeichenketten und alles andere enthalten.
Zeichenketten können wie Listen indiziert werden.
- Abrufen einzelner Zeichen aus einer Zeichenkette unter Verwendung von Indizes in eckigen Klammern.
PYTHON
element = 'carbon'
print('zeroth character:', element[0])
print('third character:', element[3])AUSGABE
zeroth character: c
third character: bZeichenketten sind unveränderlich.
- Die Zeichen in einer Zeichenkette können nicht geändert werden,
nachdem sie erstellt wurde.
- Immutable (unveränderlich): kann nach der Erstellung nicht mehr geändert werden.
- Im Gegensatz dazu sind Listen veränderlich: Sie können an Ort und Stelle geändert werden.
- Python betrachtet die Zeichenkette als einen einzelnen Wert mit Teilen, nicht als eine Sammlung von Werten.
FEHLER
TypeError: 'str' object does not support item assignment- Listen und Zeichenketten sind beides Sammlungen.
Eine Indizierung über das Ende der Auflistung hinaus ist ein Fehler.
- Python meldet einen
IndexError, wenn wir versuchen, auf einen Wert zuzugreifen, der nicht existiert.- Dies ist eine Art von Laufzeitfehler.
- Kann beim Parsen des Codes nicht erkannt werden, da der Index möglicherweise anhand von Daten berechnet wird.
AUSGABE
IndexError: string index out of rangeFüllen Sie die Lücken aus
Wie groß ist ein Slice?
Wenn start und stop beide nicht-negative
ganze Zahlen sind, wie lang ist die Liste
values[start:stop]?
Die Liste values[start:stop] hat bis zu
stop - start Elemente. Zum Beispiel hat
values[1:4] die 3 Elemente values[1],
values[2], und values[3]. Warum “bis zu”? Wie
wir in Folge 2 gesehen haben, erhalten
wir immer noch eine Liste zurück, wenn stop größer ist als
die Gesamtlänge der Liste values, aber sie wird kürzer sein
als erwartet.
-
list('some string')wandelt eine Zeichenkette in eine Liste um, die alle ihre Zeichen enthält. -
joingibt eine Zeichenkette zurück, die die Verkettung jedes Zeichenkettenelements in der Liste ist und fügt das Trennzeichen zwischen jedem Element in der Liste hinzu. Das Ergebnis istx-y-z. Das Trennzeichen zwischen den Elementen ist die Zeichenkette, die diese Methode liefert.
Arbeiten mit dem Ende
Was gibt das folgende Programm aus?
- Wie interpretiert Python einen negativen Index?
- Wenn eine Liste oder Zeichenkette N Elemente hat, welches ist der negativste Index, der sicher verwendet werden kann, und welche Stelle repräsentiert dieser Index?
- Wenn
valueseine Liste ist, was macht danndel values[-1]? - Wie kann man alle Elemente außer dem letzten anzeigen, ohne
valueszu ändern? (Tipp: Sie müssen Slicing und negative Indizierung kombinieren.)
Das Programm gibt m aus.
- Python interpretiert einen negativen Index so, als würde man vom
Ende her beginnen (im Gegensatz zum Anfang). Das letzte Element ist
-1. - Der letzte Index, der bei einer Liste mit N Elementen sicher
verwendet werden kann, ist das Element
-N, das das erste Element darstellt. -
del values[-1]entfernt das letzte Element aus der Liste. values[:-1]
Das Programm druckt
-
strideist die Schrittweite des Slice. - Das Slice
1::2wählt alle geradzahligen Elemente einer Sammlung aus: es beginnt mit dem Element1(welches das zweite Element ist, da die Indizierung bei0beginnt), geht weiter bis zum Ende (da keinendangegeben ist) und verwendet eine Schrittweite von2(d.h. es wählt jedes zweite Element aus).
AUSGABE
lithiumDie erste Anweisung gibt die gesamte Zeichenkette aus, da der Slice über die Gesamtlänge der Zeichenkette hinausgeht. Die zweite Anweisung gibt eine leere Zeichenkette zurück, da der Ausschnitt “außerhalb der Grenzen” der Zeichenkette liegt.
Programm A druckt
AUSGABE
letters is ['g', 'o', 'l', 'd'] and result is ['d', 'g', 'l', 'o']Programm B druckt
AUSGABE
letters is ['d', 'g', 'l', 'o'] and result is Nonesorted(letters) gibt eine sortierte Kopie der Liste
letters zurück (die ursprüngliche Liste
letters bleibt unverändert), während
letters.sort() die Liste letters in-place
sortiert und nichts zurückgibt.
Programm A druckt
AUSGABE
new is ['D', 'o', 'l', 'd'] and old is ['D', 'o', 'l', 'd']Programm B druckt
AUSGABE
new is ['D', 'o', 'l', 'd'] and old is ['g', 'o', 'l', 'd']new = old macht new zu einem Verweis auf
die Liste old; new und old zeigen
auf das gleiche Objekt.
new = old[:] erzeugt jedoch ein neues Listenobjekt
new, das alle Elemente der Liste old enthält;
new und old sind unterschiedliche Objekte.
- Eine Liste speichert viele Werte in einer einzigen Struktur.
- Verwenden Sie den Index eines Elements, um es aus einer Liste zu holen.
- Die Werte von Listen können durch Zuweisung ersetzt werden.
- Das Anhängen von Elementen an eine Liste verlängert diese.
- Verwenden Sie
del, um Elemente aus einer Liste vollständig zu entfernen. - Die leere Liste enthält keine Werte.
- Listen können Werte unterschiedlichen Typs enthalten.
- Zeichenketten können wie Listen indiziert werden.
- Zeichenketten sind unveränderlich.
- Die Indizierung über das Ende der Auflistung hinaus ist ein Fehler.
Content from For-Schleifen
Zuletzt aktualisiert am 2025-10-31 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich ein Programm dazu bringen, viele Dinge zu tun?
Ziele
- Erläutern Sie, wozu for-Schleifen normalerweise verwendet werden.
- Verfolgen Sie die Ausführung einer einfachen (nicht verschachtelten) Schleife und geben Sie die Werte der Variablen in jeder Iteration korrekt an.
- Schreiben Sie for-Schleifen, die das Accumulator-Muster verwenden, um Werte zu aggregieren.
Eine for-Schleife führt Befehle für jeden Wert in einer Sammlung einmal aus.
- Die Berechnung der Werte in einer Liste ist genauso mühsam wie die
Arbeit mit
pressure_001,pressure_002, etc. - Eine for-Schleife weist Python an, einige Anweisungen für jeden Wert in einer Liste, einer Zeichenkette oder einer anderen Sammlung einmal auszuführen.
- “führe für jedes Ding in dieser Gruppe diese Operationen aus”
- Diese
forSchleife ist äquivalent zu:
- Und die Ausgabe der
forSchleife ist:
AUSGABE
2
3
5Eine for-Schleife besteht aus einer Auflistung, einer
Schleifenvariablen und einem Körper.
- Die Schleife wird auf der Sammlung
[2, 3, 5]ausgeführt. - Der Körper,
print(number), gibt an, was für jeden Wert in der Sammlung zu tun ist. - Die Schleifenvariable,
number, ändert sich bei jeder Iteration der Schleife.- Das “aktuelle Ding”.
Die erste Zeile der for-Schleife muss mit einem
Doppelpunkt enden, und der Körper muss eingerückt sein.
- Der Doppelpunkt am Ende der ersten Zeile signalisiert den Beginn eines Blocks von Anweisungen.
- Python verwendet Einrückungen anstelle von
{}oderbegin/end, um Schachtelungen anzuzeigen.- Jede konsistente Einrückung ist erlaubt, aber fast jeder verwendet vier Leerzeichen.
FEHLER
IndentationError: expected an indented block- Die Einrückung ist in Python immer sinnvoll.
FEHLER
File "<ipython-input-7-f65f2962bf9c>", line 2
lastName = "Smith"
^
IndentationError: unexpected indent- Dieser Fehler kann behoben werden, indem die zusätzlichen Leerzeichen am Anfang der zweiten Zeile entfernt werden.
Schleifenvariablen können beliebig benannt werden.
- Wie alle Variablen sind auch die Schleifenvariablen:
- Wird bei Bedarf erstellt.
- Bedeutungslos: ihre Namen können alles Mögliche sein.
Der Körper einer Schleife kann viele Anweisungen enthalten.
- Aber keine Schleife sollte mehr als ein paar Zeilen lang sein.
- Für Menschen ist es schwer, sich größere Codeabschnitte zu merken.
AUSGABE
2 4 8
3 9 27
5 25 125Verwenden Sie range, um über eine Folge von Zahlen zu
iterieren.
- Die eingebaute Funktion
rangeerzeugt eine Folge von Zahlen.- Keine Liste: Die Zahlen werden bei Bedarf erzeugt, um die Schleifenbildung über große Bereiche effizienter zu machen.
-
range(N)ist die Zahlen 0..N-1- Genau die zulässigen Indizes einer Liste oder Zeichenkette der Länge N
AUSGABE
a range is not a list: range(0, 3)
0
1
2Das Accumulator-Muster macht aus vielen Werten einen einzigen.
- Ein häufiges Muster in Programmen ist to:
- Initialisiere eine Accumulator-Variable auf Null, die leere Zeichenkette oder die leere Liste.
- Aktualisiere die Variable mit Werten aus einer Sammlung.
PYTHON
# Sum the first 10 integers.
total = 0
for number in range(10):
total = total + (number + 1)
print(total)AUSGABE
55- Lies
total = total + (number + 1)als:- Addiere 1 zum aktuellen Wert der Schleifenvariablen
number. - Addiere das zum aktuellen Wert der Akkumulatorvariablen
total. - Weisen Sie dies
totalzu und ersetzen Sie damit den aktuellen Wert.
- Addiere 1 zum aktuellen Wert der Schleifenvariablen
- Wir müssen
number + 1hinzufügen, weilrange0..9 erzeugt, nicht 1..10.
Klassifizierung von Fehlern
Ist ein Einrückungsfehler ein Syntaxfehler oder ein Laufzeitfehler?
Ein IndentationError ist ein Syntaxfehler. Programme mit Syntaxfehlern können nicht gestartet werden. Ein Programm mit einem Laufzeitfehler wird zwar gestartet, aber unter bestimmten Bedingungen wird ein Fehler ausgelöst.
| Line no | Variables |
|---|---|
| 1 | total = 0 |
| 2 | total = 0 char = ‘t’ |
| 3 | total = 1 char = ‘t’ |
| 2 | total = 1 char = ‘i’ |
| 3 | total = 2 char = ‘i’ |
| 2 | total = 2 char = ‘n’ |
| 3 | total = 3 char = ‘n’ |
Übung Akkumulieren (continued)
Erstellen eines Akronyms: Ausgehend von der Liste
["red", "green", "blue"], erstellen Sie das Akronym
"RGB" mit Hilfe einer for-Schleife.
Hinweis: Möglicherweise müssen Sie eine String-Methode verwenden, um das Akronym richtig zu formatieren.
Kumulative Summe
Ordnen Sie die folgenden Codezeilen neu an und rücken Sie sie richtig
ein, so dass sie eine Liste mit der kumulierten Summe der Daten
ausgeben. Das Ergebnis sollte [1, 3, 5, 10] sein.
Identifizierung von Variablennamensfehlern
- Lesen Sie den folgenden Code und versuchen Sie, die Fehler zu identifizieren, ohne ihn auszuführen.
- Führen Sie den Code aus und lesen Sie die Fehlermeldung. Was für ein
Typ von
NameErrorist dies Ihrer Meinung nach? Ist es eine Zeichenkette ohne Anführungszeichen, eine falsch geschriebene Variable oder eine Variable, die definiert werden sollte, aber nicht definiert wurde? - Beheben Sie den Fehler.
- Wiederholen Sie die Schritte 2 und 3, bis Sie alle Fehler behoben haben.
- Bei Python-Variablennamen wird zwischen Groß- und Kleinschreibung
unterschieden:
numberundNumberbeziehen sich auf unterschiedliche Variablen. - Die Variable
messagemuss mit einem leeren String initialisiert werden. - Wir wollen die Zeichenkette
"a"zumessagehinzufügen, nicht die undefinierte Variablea.
Identifizierung von Elementfehlern
- Lesen Sie den folgenden Code und versuchen Sie, die Fehler zu identifizieren, ohne ihn auszuführen.
- Führen Sie den Code aus, und lesen Sie die Fehlermeldung. Um welche Art von Fehler handelt es sich?
- Beheben Sie den Fehler.
- Eine for-Schleife führt Befehle einmal für jeden Wert in einer Sammlung aus.
- Eine for-Schleifebesteht aus einer Sammlung, einer Schleifenvariablen und einem Körper.
- Die erste Zeile der for-Schleife muss mit einem Doppelpunkt enden, und der Körper muss eingerückt sein.
- Die Einrückung ist in Python immer sinnvoll.
- Schleifenvariablen können beliebig benannt werden (es wird jedoch dringend empfohlen, einen aussagekräftigen Namen für die Schleifenvariable zu verwenden).
- Der Körper einer Schleife kann viele Anweisungen enthalten.
- Benutze
range, um über eine Folge von Zahlen zu iterieren. - Das Accumulator-Muster macht aus vielen Werten einen einzigen.
Content from Konditionale
Zuletzt aktualisiert am 2025-10-31 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie können Programme verschiedene Dinge für verschiedene Daten tun?
Ziele
- Korrektes Schreiben von Programmen, die if- und else-Anweisungen und einfache boolesche Ausdrücke (ohne logische Operatoren) verwenden.
- Verfolgen Sie die Ausführung von nicht verschachtelten Konditionalen und Konditionalen in Schleifen.
Benutze if Anweisungen, um zu kontrollieren, ob ein
Codeblock ausgeführt wird oder nicht.
- Eine
if-Anweisung (richtiger: eine bedingte Anweisung) steuert, ob ein Codeblock ausgeführt wird oder nicht. - Die Struktur ähnelt der einer
for-Anweisung:- Die erste Zeile beginnt mit
ifund endet mit einem Doppelpunkt - Körper, der eine oder mehrere Anweisungen enthält, wird eingerückt (normalerweise um 4 Leerzeichen)
- Die erste Zeile beginnt mit
PYTHON
mass = 3.54
if mass > 3.0:
print(mass, 'is large')
mass = 2.07
if mass > 3.0:
print (mass, 'is large')AUSGABE
3.54 is largeKonditionale Bedingungen werden oft innerhalb von Schleifen verwendet.
- Es macht wenig Sinn, eine Bedingung zu verwenden, wenn wir den Wert kennen (wie oben).
- Nützlich, wenn wir eine Sammlung zu verarbeiten haben.
AUSGABE
3.54 is large
9.22 is largeVerwenden Sie else, um einen Codeblock auszuführen,
wenn eine if Bedingung nicht wahr ist.
-
elsekann nach einemifverwendet werden. - Ermöglicht die Angabe einer Alternative, die ausgeführt werden soll,
wenn der
ifZweig nicht genommen wird.
PYTHON
masses = [3.54, 2.07, 9.22, 1.86, 1.71]
for m in masses:
if m > 3.0:
print(m, 'is large')
else:
print(m, 'is small')AUSGABE
3.54 is large
2.07 is small
9.22 is large
1.86 is small
1.71 is smallVerwenden Sie elif, um zusätzliche Tests zu
spezifizieren.
- Vielleicht möchten Sie mehrere Alternativen anbieten, jede mit ihrem eigenen Test.
- Verwenden Sie
elif(kurz für “else if”) und eine Bedingung, um diese anzugeben. - Immer verbunden mit einem
if. - Muss vor
elsestehen (das ist der “catch all”).
PYTHON
masses = [3.54, 2.07, 9.22, 1.86, 1.71]
for m in masses:
if m > 9.0:
print(m, 'is HUGE')
elif m > 3.0:
print(m, 'is large')
else:
print(m, 'is small')AUSGABE
3.54 is large
2.07 is small
9.22 is HUGE
1.86 is small
1.71 is smallBedingungen werden einmal getestet, in der Reihenfolge.
- Python durchläuft die Zweige der Bedingung der Reihe nach und testet sie.
- Die Reihenfolge ist also wichtig.
PYTHON
grade = 85
if grade >= 90:
print('grade is A')
elif grade >= 80:
print('grade is B')
elif grade >= 70:
print('grade is C')AUSGABE
grade is B- Geht nicht automatisch zurück und wertet neu aus, wenn sich Werte ändern.
PYTHON
velocity = 10.0
if velocity > 20.0:
print('moving too fast')
else:
print('adjusting velocity')
velocity = 50.0AUSGABE
adjusting velocity- Verwenden Sie oft Konditionale in einer Schleife, um die Werte von Variablen zu “entwickeln”.
PYTHON
velocity = 10.0
for i in range(5): # execute the loop 5 times
print(i, ':', velocity)
if velocity > 20.0:
print('moving too fast')
velocity = velocity - 5.0
else:
print('moving too slow')
velocity = velocity + 10.0
print('final velocity:', velocity)AUSGABE
0 : 10.0
moving too slow
1 : 20.0
moving too slow
2 : 30.0
moving too fast
3 : 25.0
moving too fast
4 : 20.0
moving too slow
final velocity: 30.0Erstellen Sie eine Tabelle mit den Werten von Variablen, um die Ausführung eines Programms zu verfolgen.
| i | 0 | . | 1 | . | 2 | . | 3 | . | 4 | . |
| velocity | 10.0 | 20.0 | . | 30.0 | . | 25.0 | . | 20.0 | . | 30.0 |
- Das Programm muss eine
print-Anweisung außerhalb des Schleifenkörpers haben, um den Endwert vonvelocityanzuzeigen, da sein Wert durch die letzte Iteration der Schleife aktualisiert wird.
Zusammengesetzte Beziehungen mit
and, or und Klammern
Oft will man, dass eine Kombination von Dingen wahr ist. Sie können
Beziehungen innerhalb einer Bedingung mit and und
or kombinieren. Um das obige Beispiel fortzusetzen, nehmen
wir an, Sie haben
PYTHON
mass = [ 3.54, 2.07, 9.22, 1.86, 1.71]
velocity = [10.00, 20.00, 30.00, 25.00, 20.00]
i = 0
for i in range(5):
if mass[i] > 5 and velocity[i] > 20:
print("Fast heavy object. Duck!")
elif mass[i] > 2 and mass[i] <= 5 and velocity[i] <= 20:
print("Normal traffic")
elif mass[i] <= 2 and velocity[i] <= 20:
print("Slow light object. Ignore it")
else:
print("Whoa! Something is up with the data. Check it")Genau wie in der Arithmetik können und sollten Sie Klammern
verwenden, wenn es eine mögliche Mehrdeutigkeit gibt. Eine gute
allgemeine Regel ist es, immer Klammern zu verwenden, wenn man
and und or in derselben Bedingung mischt. Das
heißt, anstelle von:
verwenden Sie eine der folgenden Formulierungen:
PYTHON
if (mass[i] <= 2 or mass[i] >= 5) and velocity[i] > 20:
if mass[i] <= 2 or (mass[i] >= 5 and velocity[i] > 20):so ist es für den Leser (und für Python) völlig klar, was Sie wirklich meinen.
AUSGABE
25.0Trimmen von Werten
Füllen Sie die Lücken aus, so dass dieses Programm eine neue Liste erstellt, die Nullen enthält, wenn die Werte der ursprünglichen Liste negativ waren, und Einsen, wenn die Werte der ursprünglichen Liste positiv waren.
PYTHON
original = [-1.5, 0.2, 0.4, 0.0, -1.3, 0.4]
result = ____
for value in original:
if ____:
result.append(0)
else:
____
print(result)AUSGABE
[0, 1, 1, 1, 0, 1]Initialisierung
Ändern Sie dieses Programm so, dass es den größten und den kleinsten Wert in der Liste findet, unabhängig davon, wie groß der ursprüngliche Wertebereich ist.
PYTHON
values = [...some test data...]
smallest, largest = None, None
for v in values:
if ____:
smallest, largest = v, v
____:
smallest = min(____, v)
largest = max(____, v)
print(smallest, largest)Was sind die Vor- und Nachteile dieser Methode, um den Bereich der Daten zu bestimmen?
PYTHON
values = [-2,1,65,78,-54,-24,100]
smallest, largest = None, None
for v in values:
if smallest is None and largest is None:
smallest, largest = v, v
else:
smallest = min(smallest, v)
largest = max(largest, v)
print(smallest, largest)Wenn Sie == None anstelle von is None
geschrieben haben, funktioniert das auch, aber Python-Programmierer
schreiben immer is None wegen der besonderen Art und Weise,
wie None in dieser Sprache funktioniert.
Man kann argumentieren, dass ein Vorteil dieser Methode darin
besteht, den Code lesbarer zu machen. Ein Nachteil ist jedoch, dass
dieser Code nicht effizient ist, da es innerhalb jeder Iteration der
Schleifenanweisung for zwei weitere Schleifen gibt, die
jeweils über zwei Zahlen laufen (die Funktionen min und
max). Es wäre effizienter, jede Zahl nur einmal zu
durchlaufen:
PYTHON
values = [-2,1,65,78,-54,-24,100]
smallest, largest = None, None
for v in values:
if smallest is None or v < smallest:
smallest = v
if largest is None or v > largest:
largest = v
print(smallest, largest)Jetzt haben wir eine Schleife, aber vier Vergleichstests. Es gibt zwei Möglichkeiten, die Schleife weiter zu verbessern: Entweder werden in jeder Iteration weniger Vergleiche durchgeführt, oder es werden zwei Schleifen verwendet, die jeweils nur einen Vergleichstest enthalten. Die einfachste Lösung ist oft die beste:
- Verwenden Sie
if-Anweisungen, um zu kontrollieren, ob ein Codeblock ausgeführt wird oder nicht. - Konditionale Bedingungen werden oft innerhalb von Schleifen verwendet.
- Verwenden Sie
else, um einen Codeblock auszuführen, wenn eineifBedingung nicht wahr ist. - Verwenden Sie
elif, um zusätzliche Tests zu spezifizieren. - Die Bedingungen werden einmal in der Reihenfolge getestet.
- Erstellen Sie eine Tabelle mit den Werten der Variablen, um die Ausführung eines Programms zu verfolgen.
Content from Schleifen über Datensätze
Zuletzt aktualisiert am 2025-10-31 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich viele Datensätze mit einem einzigen Befehl verarbeiten?
Ziele
- In der Lage sein, Globbing-Ausdrücke zu lesen und zu schreiben, die mit Dateimengen übereinstimmen.
- Verwenden Sie glob, um Listen von Dateien zu erstellen.
- Schreibe for-Schleifen, um Operationen auf Dateien durchzuführen, deren Namen in einer Liste angegeben sind.
Verwenden Sie eine for-Schleife, um Dateien mit einer
Liste ihrer Namen zu verarbeiten.
- Ein Dateiname ist eine Zeichenkette.
- Und Listen können Zeichenketten enthalten.
PYTHON
import pandas as pd
for filename in ['data/gapminder_gdp_africa.csv', 'data/gapminder_gdp_asia.csv']:
data = pd.read_csv(filename, index_col='country')
print(filename, data.min())AUSGABE
data/gapminder_gdp_africa.csv gdpPercap_1952 298.846212
gdpPercap_1957 335.997115
gdpPercap_1962 355.203227
gdpPercap_1967 412.977514
⋮ ⋮ ⋮
gdpPercap_1997 312.188423
gdpPercap_2002 241.165877
gdpPercap_2007 277.551859
dtype: float64
data/gapminder_gdp_asia.csv gdpPercap_1952 331
gdpPercap_1957 350
gdpPercap_1962 388
gdpPercap_1967 349
⋮ ⋮ ⋮
gdpPercap_1997 415
gdpPercap_2002 611
gdpPercap_2007 944
dtype: float64Verwenden Sie glob.glob,
um Gruppen von Dateien zu finden, deren Namen einem Muster
entsprechen.
- In Unix bedeutet der Begriff “globbing” “eine Menge von Dateien mit einem Muster abgleichen”.
- Die häufigsten Muster sind:
-
*bedeutet “entspricht null oder mehr Zeichen” -
?bedeutet “genau ein Zeichen übereinstimmen”
-
- Die Standardbibliothek von Python enthält das Modul
glob, um die Funktionalität des Mustervergleichs bereitzustellen - Das
globModul enthält eine Funktion, die auchglobgenannt wird, um Dateimuster zu finden - Z.B. passt
glob.glob('*.txt')auf alle Dateien im aktuellen Verzeichnis, deren Namen mit.txtenden. - Das Ergebnis ist eine (möglicherweise leere) Liste von Zeichenketten.
AUSGABE
all csv files in data directory: ['data/gapminder_all.csv', 'data/gapminder_gdp_africa.csv', \
'data/gapminder_gdp_americas.csv', 'data/gapminder_gdp_asia.csv', 'data/gapminder_gdp_europe.csv', \
'data/gapminder_gdp_oceania.csv']AUSGABE
all PDB files: []Verwenden Sie glob und for, um Stapel von
Dateien zu verarbeiten.
- Es hilft sehr, wenn die Dateien systematisch und konsistent benannt und gespeichert werden, damit einfache Muster die richtigen Daten finden.
PYTHON
for filename in glob.glob('data/gapminder_*.csv'):
data = pd.read_csv(filename)
print(filename, data['gdpPercap_1952'].min())AUSGABE
data/gapminder_all.csv 298.8462121
data/gapminder_gdp_africa.csv 298.8462121
data/gapminder_gdp_americas.csv 1397.717137
data/gapminder_gdp_asia.csv 331.0
data/gapminder_gdp_europe.csv 973.5331948
data/gapminder_gdp_oceania.csv 10039.59564- Dies beinhaltet alle Daten, sowie Daten pro Region.
- Verwenden Sie ein spezifischeres Muster in den Übungen, um den gesamten Datensatz auszuschließen.
- Aber beachten Sie, dass das Minimum des gesamten Datensatzes auch das Minimum eines der Datensätze ist, was eine nette Überprüfung der Korrektheit ist.
Ermitteln von Übereinstimmungen
Auf welche dieser Dateien trifft der Ausdruck
glob.glob('data/*as*.csv') nicht zu?
data/gapminder_gdp_africa.csvdata/gapminder_gdp_americas.csvdata/gapminder_gdp_asia.csv
1 wird vom glob nicht gefunden.
Minimale Dateigröße
Ändern Sie dieses Programm so, dass es die Anzahl der Datensätze in der Datei mit den wenigsten Datensätzen ausgibt.
PYTHON
import glob
import pandas as pd
fewest = ____
for filename in glob.glob('data/*.csv'):
dataframe = pd.____(filename)
fewest = min(____, dataframe.shape[0])
print('smallest file has', fewest, 'records')Beachten Sie, dass die Methode
DataFrame.shape() ein Tupel mit der Anzahl der Zeilen
und Spalten des Datenrahmens zurückgibt.
PYTHON
import glob
import pandas as pd
fewest = float('Inf')
for filename in glob.glob('data/*.csv'):
dataframe = pd.read_csv(filename)
fewest = min(fewest, dataframe.shape[0])
print('smallest file has', fewest, 'records')Sie könnten sich dafür entschieden haben, die Variable
fewest mit einer Zahl zu initialisieren, die größer ist als
die Zahlen, mit denen Sie arbeiten, aber das könnte zu Problemen führen,
wenn Sie den Code mit größeren Zahlen wiederverwenden. In Python können
Sie positive Unendlichkeit verwenden, was unabhängig von der Größe Ihrer
Zahlen funktioniert. Welche anderen speziellen Zeichenketten erkennt die
Funktion
float?
Vergleich von Daten
Schreiben Sie ein Programm, das die regionalen Datensätze einliest und das durchschnittliche Pro-Kopf-BIP für jede Region über die Zeit in einem einzigen Diagramm darstellt. Pandas gibt eine Fehlermeldung aus, wenn es auf nicht-numerische Spalten in einer Datenrahmenberechnung stößt. Sie müssen also entweder diese Spalten herausfiltern oder Pandas anweisen, sie zu ignorieren.
Diese Lösung erstellt eine nützliche Legende, indem sie die string
split method verwendet, um die region aus
dem Pfad ‘data/gapminder_gdp_a_specific_region.csv’ zu extrahieren.
PYTHON
import glob
import pandas as pd
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1,1)
for filename in glob.glob('data/gapminder_gdp*.csv'):
dataframe = pd.read_csv(filename)
# Extrahieren Sie <Region> aus dem Dateinamen, der voraussichtlich das Format „data/gapminder_gdp_<Region>.csv” hat.
# Wir teilen die Zeichenfolge mit der Split-Methode und „_” als Trennzeichen,
# rufen die letzte Zeichenfolge in der Liste ab, die Split zurückgibt („<Region>.csv”),
# und entfernen dann die Erweiterung „.csv” aus dieser Zeichenfolge.
# HINWEIS: Das im nächsten Callout behandelte Modul „pathlib” bietet ebenfalls
# praktische Abstraktionen für die Arbeit mit Dateisystempfaden und könnte dies ebenfalls lösen:
# from pathlib import Path
# region = Path(filename).stem.split(‚_‘)[-1]
region = filename.split('_')[-1][:-4]
# Extrahieren Sie die Jahreszahlen aus den Spalten des Datenrahmens.
headings = dataframe.columns[1:]
years = headings.str.split('_').str.get(1)
# pandas gibt Fehler aus, wenn es bei der Berechnung eines Datenrahmens auf nicht numerische Spalten stößt.
# Wir können pandas jedoch mit dem Parameter „numeric_only” anweisen, diese zu ignorieren.
dataframe.mean(numeric_only=True).plot(ax=ax, label=region)
# HINWEIS: Eine andere Möglichkeit besteht darin, mithilfe der Filtermethode nur die Spalten auszuwählen, deren Name „gdp” enthält.
# dataframe.filter(like=„gdp“).mean().plot(ax=ax, label=region)
# Titel und Beschriftungen festlegen
ax.set_title('GDP Per Capita for Regions Over Time')
ax.set_xticks(range(len(years)))
ax.set_xticklabels(years)
ax.set_xlabel('Year')
plt.tight_layout()
plt.legend()
plt.show()Umgang mit Dateipfaden
Das Modul
pathlib bietet nützliche Abstraktionen für die Datei-
und Pfadmanipulation, wie z.B. die Rückgabe des Namens einer Datei ohne
die Dateierweiterung. Dies ist sehr nützlich, wenn man eine Schleife
über Dateien und Verzeichnisse zieht. Im folgenden Beispiel erstellen
wir ein Objekt Path und untersuchen seine Attribute.
PYTHON
from pathlib import Path
p = Path("data/gapminder_gdp_africa.csv")
print(p.parent)
print(p.stem)
print(p.suffix)AUSGABE
data
gapminder_gdp_africa
.csvHinweis: Überprüfen Sie alle verfügbaren Attribute
und Methoden des Objekts Path mit der Funktion
dir().
- Verwenden Sie eine
for-Schleife, um Dateien mit einer Liste von Namen zu verarbeiten. - Verwenden Sie
glob.glob, um Gruppen von Dateien zu finden, deren Namen einem Muster entsprechen. - Verwenden Sie
globundfor, um Stapel von Dateien zu verarbeiten.
Content from Kaffee am Nachmittag
Zuletzt aktualisiert am 2025-03-02 | Diese Seite bearbeiten
Reflexionsübung
Denken Sie in der Pause über die folgenden Punkte nach und diskutieren Sie sie:
- Ein gängiger Spruch in der Softwareentwicklung ist “Wiederhole dich nicht”. Wie können die Techniken, die wir in den letzten Lektionen gelernt haben, uns helfen, Wiederholungen zu vermeiden? *Beachten Sie, dass es in der Praxis einige Nuancen gibt, die mit der einfachsten Lösung, die möglich ist, in Einklang gebracht werden sollten
- Was sind die Vor- und Nachteile, wenn man eine Variable global oder lokal zu einer Funktion macht?
- Wann würden Sie erwägen, einen Codeblock in eine Funktionsdefinition zu verwandeln?
Content from Funktionen schreiben
Zuletzt aktualisiert am 2025-11-05 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich meine eigenen Funktionen erstellen?
Ziele
- Erklären und identifizieren Sie den Unterschied zwischen Funktionsdefinition und Funktionsaufruf.
- Schreiben Sie eine Funktion, die eine kleine, feste Anzahl von Argumenten annimmt und ein einziges Ergebnis liefert.
Zerlegen Sie Programme in Funktionen, um sie besser verstehen zu können.
- Der Mensch kann nur einige wenige Dinge gleichzeitig im Arbeitsgedächtnis behalten.
- Verstehen Sie größere/kompliziertere Ideen, indem Sie Teile
verstehen und kombinieren.
- Komponenten in einer Maschine.
- Lemmata beim Beweisen von Theoremen.
- Funktionen dienen in Programmen demselben Zweck.
- Kapseln wir die Komplexität ein, so dass wir sie als ein einziges “Ding” behandeln können.
- Ermöglicht auch die Wiederverwendung.
- Einmal schreiben, viele Male verwenden.
Definieren Sie eine Funktion mit def mit einem Namen,
Parametern und einem Codeblock.
- Beginnen Sie die Definition einer neuen Funktion mit
def. - Gefolgt vom Namen der Funktion.
- Muss denselben Regeln gehorchen wie Variablennamen.
- Dann Parameter in Klammern.
- Leere Klammern, wenn die Funktion keine Eingaben annimmt.
- Wir werden dies gleich im Detail besprechen.
- Dann ein Doppelpunkt.
- Dann ein eingerückter Code-Block.
Durch die Definition einer Funktion wird diese nicht ausgeführt.
- Die Definition einer Funktion führt sie nicht aus.
- Wie die Zuweisung eines Wertes zu einer Variablen.
- Muss die Funktion aufrufen, um den in ihr enthaltenen Code auszuführen.
AUSGABE
Hello!Argumente in einem Funktionsaufruf werden mit ihren definierten Parametern abgeglichen.
- Funktionen sind am nützlichsten, wenn sie mit verschiedenen Daten arbeiten können.
- Geben Sie Parameter an, wenn Sie eine Funktion definieren.
- Diese werden zu Variablen, wenn die Funktion ausgeführt wird.
- werden die Argumente im Aufruf (d.h. die der Funktion übergebenen Werte) zugeordnet.
- Wenn Sie die Argumente nicht benennen, wenn Sie sie im Aufruf verwenden, werden die Argumente den Parametern in der Reihenfolge zugeordnet, in der die Parameter in der Funktion definiert sind.
PYTHON
def print_date(year, month, day):
joined = str(year) + '/' + str(month) + '/' + str(day)
print(joined)
print_date(1871, 3, 19)AUSGABE
1871/3/19Oder wir können die Argumente benennen, wenn wir die Funktion aufrufen, was uns erlaubt, sie in beliebiger Reihenfolge anzugeben und die Aufrufseite übersichtlicher zu gestalten; andernfalls könnte man beim Lesen des Codes vergessen, ob das zweite Argument zum Beispiel der Monat oder der Tag ist.
AUSGABE
1871/3/19- Über Twitter:
()enthält die Zutaten für die Funktion, während der Körper das Rezept enthält.
Funktionen können mit return ein Ergebnis an ihren
Aufrufer zurückgeben.
- Verwenden Sie
return ..., um einen Wert an den Aufrufer zurückzugeben. - Kann an beliebiger Stelle in der Funktion auftreten.
- Aber Funktionen sind leichter zu verstehen, wenn
returnvorkommt:- Am Anfang, um Sonderfälle zu behandeln.
- Ganz am Ende, mit einem Endergebnis.
AUSGABE
average of actual values: 2.6666666666666665AUSGABE
average of empty list: None- Zur Erinnerung: jede Funktion gibt etwas zurück.
- Eine Funktion, die nicht ausdrücklich
returneinen Wert angibt, gibt automatischNonezurück.
AUSGABE
1871/3/19
result of call is: NoneErkennen von Syntaxfehlern
- Lesen Sie den folgenden Code und versuchen Sie, die Fehler zu identifizieren, ohne ihn auszuführen.
- Führen Sie den Code aus und lesen Sie die Fehlermeldung. Ist es ein
SyntaxErroroder einIndentationError? - Beheben Sie den Fehler.
- Wiederholen Sie die Schritte 2 und 3, bis Sie alle Fehler behoben haben.
AUSGABE
calling <function report at 0x7fd128ff1bf8> 22.5Ein Funktionsaufruf muss immer in Klammern gesetzt werden, sonst erhält man die Speicheradresse des Funktionsobjekts. Wenn wir also die Funktion mit dem Namen report aufrufen und ihr den Wert 22.5 geben wollen, könnten wir unseren Funktionsaufruf wie folgt formulieren
AUSGABE
calling
pressure is 22.5Reihenfolge der Operationen
- Was ist in diesem Beispiel falsch?
PYTHON
result = print_time(11, 37, 59)
def print_time(hour, minute, second):
time_string = str(hour) + ':' + str(minute) + ':' + str(second)
print(time_string)- Erläutern Sie nach der Lösung des obigen Problems, warum dieser Beispielcode ausgeführt wird:
ergibt diese Ausgabe:
AUSGABE
11:37:59
result of call is: None- Warum ist das Ergebnis des Aufrufs
None?
Das Problem bei diesem Beispiel ist, dass die Funktion
print_time()erst nach dem Aufruf der Funktion definiert wird. Python weiß nicht, wie es den Namenprint_timeauflösen soll, da er noch nicht definiert wurde, und wird einNameErrorauslösen, z.B.NameError: name 'print_time' is not definedDie erste Zeile der Ausgabe
11:37:59wird von der ersten Codezeileresult = print_time(11, 37, 59)gedruckt, die den durch den Aufruf vonprint_timezurückgegebenen Wert an die Variableresultbindet. Die zweite Zeile stammt aus dem zweiten Druckaufruf, um den Inhalt der Variablenresultzu drucken.print_time()nicht explizitreturneinen Wert, so dass es automatischNonezurückgibt.
Einkapselung
Finde die erste
Füllen Sie die Lücken aus, um eine Funktion zu erstellen, die eine Liste von Zahlen als Argument nimmt und den ersten negativen Wert in der Liste zurückgibt. Was macht Ihre Funktion, wenn die Liste leer ist? Was ist, wenn die Liste keine negativen Zahlen enthält?
Aufruf durch Name
Vorhin haben wir diese Funktion gesehen:
PYTHON
def print_date(year, month, day):
joined = str(year) + '/' + str(month) + '/' + str(day)
print(joined)Wir haben gesehen, dass wir die Funktion mit benannten Argumenten aufrufen können, etwa so:
- Was gibt
print_date(day=1, month=2, year=2003)aus? - Wann haben Sie schon einmal einen Funktionsaufruf wie diesen gesehen?
- Wann und warum ist es sinnvoll, Funktionen auf diese Weise aufzurufen?
2003/2/1- Wir haben Beispiele für die Verwendung von benannten
Argumenten bei der Arbeit mit der Pandas-Bibliothek gesehen. Wenn
man zum Beispiel einen Datensatz mit
data = pd.read_csv('data/gapminder_gdp_europe.csv', index_col='country')einliest, ist das letzte Argumentindex_colein benanntes Argument. - Die Verwendung von benannten Argumenten kann den Code lesbarer machen, da man aus dem Funktionsaufruf erkennen kann, welchen Namen die verschiedenen Argumente innerhalb der Funktion haben. Es kann auch die Wahrscheinlichkeit verringern, dass Argumente in der falschen Reihenfolge übergeben werden, da bei der Verwendung von benannten Argumenten die Reihenfolge keine Rolle spielt.
Einkapselung eines If/Print-Blocks
Der folgende Code wird auf einem Etikettendrucker für Hühnereier ausgeführt. Eine digitale Waage meldet dem Computer die Masse eines Hühnereis (in Gramm) und der Computer druckt dann ein Etikett.
PYTHON
import random
for i in range(10):
# simulating the mass of a chicken egg
# the (random) mass will be 70 +/- 20 grams
mass = 70 + 20.0 * (2.0 * random.random() - 1.0)
print(mass)
# egg sizing machinery prints a label
if mass >= 85:
print("jumbo")
elif mass >= 70:
print("large")
elif mass < 70 and mass >= 55:
print("medium")
else:
print("small")Der if-Block, der die Eier klassifiziert, könnte auch in anderen
Situationen nützlich sein. Um eine Wiederholung zu vermeiden, könnten
wir ihn in eine Funktion falten, get_egg_label(). Wenn wir
das Programm überarbeiten, um die Funktion zu verwenden, würden wir
folgendes erhalten:
PYTHON
# revised version
import random
for i in range(10):
# simulating the mass of a chicken egg
# the (random) mass will be 70 +/- 20 grams
mass = 70 + 20.0 * (2.0 * random.random() - 1.0)
print(mass, get_egg_label(mass))- Erstellen Sie eine Funktionsdefinition für
get_egg_label(), die mit dem überarbeiteten Programm oben funktionieren wird. Beachten Sie, dass der Rückgabewert der Funktionget_egg_label()wichtig sein wird. Die Beispielausgabe des obigen Programms wäre71.23 large. - Ein schmutziges Ei könnte eine Masse von mehr als 90 Gramm haben,
und ein verdorbenes oder zerbrochenes Ei hat wahrscheinlich eine Masse
von weniger als 50 Gramm. Ändern Sie Ihre Funktion
get_egg_label(), um diese Fehlerbedingungen zu berücksichtigen. Eine Beispielausgabe könnte25 too light, probably spoiledsein.
PYTHON
def get_egg_label(mass):
# egg sizing machinery prints a label
egg_label = "Unlabelled"
if mass >= 90:
egg_label = "warning: egg might be dirty"
elif mass >= 85:
egg_label = "jumbo"
elif mass >= 70:
egg_label = "large"
elif mass < 70 and mass >= 55:
egg_label = "medium"
elif mass < 50:
egg_label = "too light, probably spoiled"
else:
egg_label = "small"
return egg_labelVerkapselnde Datenanalyse
Nehmen Sie an, dass der folgende Code ausgeführt wurde:
PYTHON
import pandas as pd
data_asia = pd.read_csv('data/gapminder_gdp_asia.csv', index_col=0)
japan = data_asia.loc['Japan']- Vervollständigen Sie die nachstehenden Aussagen, um das durchschnittliche BIP Japans über die für die 1980er Jahre angegebenen Jahre zu erhalten.
PYTHON
year = 1983
gdp_decade = 'gdpPercap_' + str(year // ____)
avg = (japan.loc[gdp_decade + ___] + japan.loc[gdp_decade + ___]) / 2- Fassen Sie den obigen Code in einer einzigen Funktion zusammen.
PYTHON
def avg_gdp_in_decade(country, continent, year):
data_countries = pd.read_csv('data/gapminder_gdp_'+___+'.csv',delimiter=',',index_col=0)
____
____
____
return avg- Wie würden Sie diese Funktion verallgemeinern, wenn Sie im Voraus nicht wüssten, welche spezifischen Jahre als Spalten in den Daten vorkommen? Was wäre zum Beispiel, wenn wir für jedes Jahrzehnt auch Daten von Jahren hätten, die mit 1 und 9 enden? (Tipp: Verwenden Sie die Spalten, um die Spalten herauszufiltern, die dem Jahrzehnt entsprechen, anstatt sie im Code aufzuzählen)
- Das durchschnittliche BIP für Japan über die Jahre, die für die 1980er Jahre berichtet werden, wird mit berechnet:
PYTHON
year = 1983
gdp_decade = 'gdpPercap_' + str(year // 10)
avg = (japan.loc[gdp_decade + '2'] + japan.loc[gdp_decade + '7']) / 2- Dieser Code als Funktion ist:
PYTHON
def avg_gdp_in_decade(country, continent, year):
data_countries = pd.read_csv('data/gapminder_gdp_' + continent + '.csv', index_col=0)
c = data_countries.loc[country]
gdp_decade = 'gdpPercap_' + str(year // 10)
avg = (c.loc[gdp_decade + '2'] + c.loc[gdp_decade + '7'])/2
return avg- Um den Durchschnitt für die betreffenden Jahre zu erhalten, müssen wir eine Schleife über sie ziehen:
PYTHON
def avg_gdp_in_decade(country, continent, year):
data_countries = pd.read_csv('data/gapminder_gdp_' + continent + '.csv', index_col=0)
c = data_countries.loc[country]
gdp_decade = 'gdpPercap_' + str(year // 10)
total = 0.0
num_years = 0
for yr_header in c.index: # c's index contains reported years
if yr_header.startswith(gdp_decade):
total = total + c.loc[yr_header]
num_years = num_years + 1
return total/num_yearsDie Funktion kann nun aufgerufen werden durch:
AUSGABE
20880.023800000003Simulation eines dynamischen Systems
In der Mathematik ist ein dynamisches System ein System, in dem eine Funktion die Zeitabhängigkeit eines Punktes in einem geometrischen Raum beschreibt. Ein kanonisches Beispiel für ein dynamisches System ist die logistische Karte, ein Wachstumsmodell, das eine neue Bevölkerungsdichte (zwischen 0 und 1) auf der Grundlage der aktuellen Dichte berechnet. In diesem Modell nimmt die Zeit die diskreten Werte 0, 1, 2, …
- Definieren Sie eine Funktion namens
logistic_map, die zwei Eingaben benötigt:x, die die aktuelle Bevölkerung (zum Zeitpunktt) darstellt, und einen Parameterr = 1. Diese Funktion sollte einen Wert zurückgeben, der den Zustand des Systems (der Population) zum Zeitpunktt + 1repräsentiert, wobei die Abbildungsfunktion verwendet wird:
f(t+1) = r * f(t) * [1 - f(t)]
Iterieren Sie die in Teil 1 definierte Funktion
logistic_mapausgehend von einer Grundgesamtheit von 0,5 über einen Zeitraum vont_final = 10in einer Schleifeforoderwhile. Speichern Sie die Zwischenergebnisse in einer Liste, so dass Sie nach Beendigung der Schleife eine Folge von Werten haben, die den Zustand der logistischen Karte zu Zeitent = [0,1,...,t_final](insgesamt 11 Werte) darstellen. Drucken Sie diese Liste aus, um die Entwicklung der Population zu sehen.Kapseln Sie die Logik Ihrer Schleife in eine Funktion mit dem Namen
iterate, die die Ausgangsbevölkerung als erste Eingabe, den Parametert_finalals zweite Eingabe und den Parameterrals dritte Eingabe erhält. Die Funktion sollte die Liste der Werte zurückgeben, die den Zustand der logistischen Karte zu den Zeitpunktent = [0,1,...,t_final]darstellen. Führen Sie diese Funktion für die Zeiträumet_final = 100und1000aus und geben Sie einige der Werte aus. Entwickelt sich die Bevölkerung zu einem stabilen Zustand?
PYTHON
initial_population = 0.5
t_final = 10
r = 1.0
population = [initial_population]
for t in range(t_final):
population.append( logistic_map(population[t], r) )PYTHON
def iterate(initial_population, t_final, r):
population = [initial_population]
for t in range(t_final):
population.append( logistic_map(population[t], r) )
return population
for period in (10, 100, 1000):
population = iterate(0.5, period, 1)
print(population[-1])AUSGABE
0.06945089389714401
0.009395779870614648
0.0009913908614406382Die Bevölkerung scheint sich dem Nullpunkt zu nähern.
Verwendung von Funktionen mit Konditionalen in Pandas
Funktionen enthalten oft Konditionale. Hier ist ein kurzes Beispiel, das anzeigt, in welchem Quartil sich das Argument befindet, basierend auf handcodierten Werten für die Quartilsschnittpunkte.
PYTHON
def calculate_life_quartile(exp):
if exp < 58.41:
# This observation is in the first quartile
return 1
elif exp >= 58.41 and exp < 67.05:
# This observation is in the second quartile
return 2
elif exp >= 67.05 and exp < 71.70:
# This observation is in the third quartile
return 3
elif exp >= 71.70:
# This observation is in the fourth quartile
return 4
else:
# This observation has bad data
return None
calculate_life_quartile(62.5)AUSGABE
2Diese Funktion würde typischerweise innerhalb einer
for-Schleife verwendet werden, aber Pandas hat einen
anderen, effizienteren Weg, das Gleiche zu tun, und zwar durch
Anwendung einer Funktion auf einen Datenrahmen oder einen Teil
eines Datenrahmens. Hier ist ein Beispiel, das die obige Definition
verwendet.
PYTHON
data = pd.read_csv('data/gapminder_all.csv')
data['life_qrtl'] = data['lifeExp_1952'].apply(calculate_life_quartile)Diese zweite Zeile enthält eine ganze Menge, also gehen wir sie Stück
für Stück durch. Auf der rechten Seite von = beginnen wir
mit data['lifeExp'], das ist die Spalte in dem Datenrahmen
namens data mit der Bezeichnung lifExp. Wir
benutzen apply(), um das zu tun, was es sagt, nämlich
calculate_life_quartile auf den Wert dieser Spalte für jede
Zeile des Datenrahmens anzuwenden.
- Zerlegen Sie Programme in Funktionen, um sie besser verstehen zu können.
- Definieren Sie eine Funktion mit
defmit einem Namen, Parametern und einem Codeblock. - Die Definition einer Funktion führt sie nicht aus.
- Argumente in einem Funktionsaufruf werden mit ihren definierten Parametern abgeglichen.
- Funktionen können mit
returnein Ergebnis an ihren Aufrufer zurückgeben.
Content from Variablenumfang
Zuletzt aktualisiert am 2025-11-05 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie funktionieren eigentlich Funktionsaufrufe?
- Wie kann ich feststellen, wo Fehler aufgetreten sind?
Ziele
- Identifizieren Sie lokale und globale Variablen.
- Identifizieren Sie Parameter als lokale Variablen.
- Lies einen Traceback und bestimme die Datei, Funktion und Zeilennummer, in der der Fehler aufgetreten ist, den Fehlertyp und die Fehlermeldung.
Der Geltungsbereich (Englisch: scope) einer Variablen ist der Teil eines Programms, der diese Variable ‘sehen’ kann.
- Es gibt nur so viele sinnvolle Namen für Variablen.
- Leute, die Funktionen benutzen, sollten sich nicht darum kümmern müssen, welche Variablennamen der Autor der Funktion benutzt hat.
- Leute, die Funktionen schreiben, sollten sich nicht darum kümmern müssen, welche Variablennamen der Funktionsaufrufer verwendet.
- Der Teil eines Programms, in dem eine Variable sichtbar ist, wird ihr Scope genannt.
-
pressureist eine globale Variable.- Definiert außerhalb einer bestimmten Funktion.
- Überall sichtbar.
-
tundtemperaturesind lokale Variablen inadjust.- Definiert in der Funktion.
- Nicht sichtbar im Hauptprogramm.
- Erinnern Sie sich: Ein Funktionsparameter ist eine Variable, der automatisch ein Wert zugewiesen wird, wenn die Funktion aufgerufen wird.
AUSGABE
adjusted: 0.01238691049085659FEHLER
Traceback (most recent call last):
File "/Users/swcarpentry/foo.py", line 8, in <module>
print('temperature after call:', temperature)
NameError: name 'temperature' is not definedVerwendung von lokalen und globalen Variablen
Lesen von Fehlermeldungen
Lesen Sie den Traceback unten, und identifizieren Sie das Folgende:
- Wie viele Ebenen hat der Traceback?
- Wie lautet der Name der Datei, in der der Fehler aufgetreten ist?
- Wie lautet der Name der Funktion, bei der der Fehler aufgetreten ist?
- Bei welcher Zeilennummer in dieser Funktion ist der Fehler aufgetreten?
- Um welche Art von Fehler handelt es sich?
- Wie lautet die Fehlermeldung?
FEHLER
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-2-e4c4cbafeeb5> in <module>()
1 import errors_02
----> 2 errors_02.print_friday_message()
/Users/ghopper/thesis/code/errors_02.py in print_friday_message()
13
14 def print_friday_message():
---> 15 print_message("Friday")
/Users/ghopper/thesis/code/errors_02.py in print_message(day)
9 "sunday": "Aw, the weekend is almost over."
10 }
---> 11 print(messages[day])
12
13
KeyError: 'Friday'- Drei Ebenen.
errors_02.pyprint_message- Zeile 11
-
KeyError. Diese Fehler treten auf, wenn versucht wird, einen Schlüssel nachzuschlagen, der nicht vorhanden ist (normalerweise in einer Datenstruktur wie einem Wörterbuch). Weitere Informationen überKeyErrorund andere eingebaute Ausnahmen finden Sie in den Python docs. KeyError: 'Friday'
- Der Geltungsbereich einer Variablen ist der Teil eines Programms, der diese Variable ‘sehen’ kann.
Content from Programmierstil
Zuletzt aktualisiert am 2025-11-05 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie kann ich meine Programme besser lesbar machen?
- Wie formatieren die meisten Programmierer ihren Code?
- Wie können Programme ihre eigene Funktion überprüfen?
Ziele
- Begründen Sie die grundlegenden Regeln des Kodierungsstils.
- Refactor one-page programs to make them more readable and justify the changes.
- Verwenden Sie die Python Community Coding Standards (PEP-8).
Kodierungsstil
Ein konsistenter Kodierungsstil hilft anderen (einschließlich unserer zukünftigen Selbst), den Code leichter zu lesen und zu verstehen. Code wird viel öfter gelesen als geschrieben, und wie es im Zen of Python heißt, “Lesbarkeit zählt”. Python hat mit einem seiner ersten Python Enhancement Proposals (PEP), PEP8, einen Standardstil vorgeschlagen.
Einige Punkte, die hervorzuheben sind:
- Dokumentieren Sie Ihren Code und stellen Sie sicher, dass Annahmen, interne Algorithmen, erwartete Eingaben, erwartete Ausgaben, etc. klar sind
- Verwenden Sie klare, semantisch sinnvolle Variablennamen
- Verwenden Sie Leerzeichen, nicht Tabulatoren, um Zeilen einzurücken (Tabulatoren können in verschiedenen Texteditoren, Betriebssystemen und Versionskontrollsystemen Probleme verursachen)
Befolgen Sie den Standard-Python-Stil in Ihrem Code.
-
PEP8: eine
Stilanleitung für Python, die Themen wie die Benennung von Variablen,
das Einrücken von Code, die Strukturierung von
import-Anweisungen usw. behandelt. Die Einhaltung von PEP8 macht es für andere Python-Entwickler einfacher, Ihren Code zu lesen und zu verstehen, und zu wissen, wie ihre Beiträge aussehen sollten. - Um Ihren Code auf die Einhaltung von PEP8 zu überprüfen, können Sie die pycodestyle Anwendung verwenden und Werkzeuge wie der black code formatter können Ihren Code automatisch so formatieren, dass er mit PEP8 und pycodestyle konform ist (es gibt auch einen Jupyter notebook formatter nb_black).
- Einige Gruppen und Organisationen folgen anderen Stilrichtlinien als PEP8. Der [Google style guide on Python] (https://google.github.io/styleguide/pyguide.html) gibt zum Beispiel leicht abweichende Empfehlungen. Google hat eine Anwendung geschrieben, die Ihnen dabei helfen kann, Ihren Code entweder nach ihrem Stil oder nach PEP8 zu formatieren: yapf.
- In Bezug auf den Kodierungsstil ist der Schlüssel Konsistenz. Wählen Sie einen Stil für Ihr Projekt, sei es PEP8, der Google-Stil oder etwas anderes, und tun Sie Ihr Bestes, um sicherzustellen, dass Sie und alle anderen, mit denen Sie zusammenarbeiten, sich daran halten. Die Konsistenz innerhalb eines Projekts ist oft wichtiger als der verwendete Stil. Ein einheitlicher Stil macht Ihre Software für andere und für Sie selbst einfacher zu lesen und zu verstehen.
Verwenden Sie Assertions, um auf interne Fehler zu prüfen.
Assertions sind eine einfache, aber mächtige Methode, um sicherzustellen, dass der Kontext, in dem Ihr Code ausgeführt wird, so ist, wie Sie es erwarten.
PYTHON
def calc_bulk_density(mass, volume):
'''Return dry bulk density = powder mass / powder volume.'''
assert volume > 0
return mass / volumeWenn die Behauptung False ist, löst der
Python-Interpreter eine AssertionError-Laufzeit-Ausnahme
aus. Der Quellcode des fehlgeschlagenen Ausdrucks wird als Teil der
Fehlermeldung angezeigt. Um Behauptungen in Ihrem Code zu ignorieren,
führen Sie den Interpreter mit dem Schalter ‘-O’ (optimize) aus.
Behauptungen sollten nur einfache Prüfungen enthalten und niemals den
Zustand des Programms verändern. Zum Beispiel sollte eine Assertion
niemals eine Zuweisung enthalten.
Verwenden Sie docstrings, um eingebaute Hilfe bereitzustellen.
Wenn das erste Ding in einer Funktion eine Zeichenkette ist, die nicht direkt einer Variablen zugewiesen ist, fügt Python sie an die Funktion an, die über die eingebaute Hilfefunktion zugänglich ist. Diese dokumentierende Zeichenkette wird auch als Docstring bezeichnet.
PYTHON
def average(values):
"Return average of values, or None if no values are supplied."
if len(values) == 0:
return None
return sum(values) / len(values)
help(average)AUSGABE
Help on function average in module __main__:
average(values)
Return average of values, or None if no values are supplied.Was wird angezeigt?
Markieren Sie die Zeilen im folgenden Code, die als Online-Hilfe verfügbar sein werden. Gibt es Zeilen, die verfügbar gemacht werden sollten, aber nicht verfügbar sind? Gibt es Zeilen, die einen Syntaxfehler oder einen Laufzeitfehler verursachen?
PYTHON
"Find maximum edit distance between multiple sequences."
# This finds the maximum distance between all sequences.
def overall_max(sequences):
'''Determine overall maximum edit distance.'''
highest = 0
for left in sequences:
for right in sequences:
'''Avoid checking sequence against itself.'''
if left != right:
this = edit_distance(left, right)
highest = max(highest, this)
# Report.
return highestDokumentieren Sie dies
Verwenden Sie Kommentare, um potentiell unintuitive Abschnitte oder einzelne Codezeilen zu beschreiben und anderen zu helfen, sie zu verstehen. Sie sind besonders nützlich für alle, die Ihren Code in Zukunft verstehen und bearbeiten müssen, einschließlich Ihnen selbst.
Verwenden Sie docstrings, um die zulässigen Eingaben und erwarteten
Ausgaben einer Methode oder Klasse, ihren Zweck, ihre Annahmen und ihr
beabsichtigtes Verhalten zu dokumentieren. Docstrings werden angezeigt,
wenn ein Benutzer die eingebaute Methode help für Ihre
Methode oder Klasse aufruft.
Verwandeln Sie den Kommentar in der folgenden Funktion in einen
docstring und überprüfen Sie, ob help ihn richtig
anzeigt.
Diesen Code aufräumen
- Lesen Sie dieses kurze Programm und versuchen Sie zu erraten, was es tut.
- Führen Sie es aus: Wie genau war Ihre Vorhersage?
- Refaktorieren Sie das Programm, um es lesbarer zu machen. Denken Sie daran, es nach jeder Änderung auszuführen, um sicherzustellen, dass sich sein Verhalten nicht geändert hat.
- Vergleichen Sie Ihren Rewrite mit dem Ihres Nachbarn. Was haben Sie gleich gemacht? Was haben Sie anders gemacht, und warum?
Hier ist eine Lösung.
PYTHON
def string_machine(input_string, iterations):
"""
Takes input_string and generates a new string with -'s and *'s
corresponding to characters that have identical adjacent characters
or not, respectively. Iterates through this procedure with the resultant
strings for the supplied number of iterations.
"""
print(input_string)
input_string_length = len(input_string)
old = input_string
for i in range(iterations):
new = ''
# iterate through characters in previous string
for j in range(input_string_length):
left = j-1
right = (j+1) % input_string_length # ensure right index wraps around
if old[left] == old[right]:
new = new + '-'
else:
new = new + '*'
print(new)
# store new string as old
old = new
string_machine('et cetera', 10)AUSGABE
et cetera
*****-***
----*-*--
---*---*-
--*-*-*-*
**-------
***-----*
--**---**
*****-***
----*-*--
---*---*-- Befolgen Sie den Standard-Python-Stil in Ihrem Code.
- Verwenden Sie docstrings, um eingebaute Hilfe bereitzustellen.
Content from Nachbereitung
Zuletzt aktualisiert am 2025-03-02 | Diese Seite bearbeiten
Übersicht
Fragen
- Was haben wir gelernt?
- Was gibt es sonst noch und wo finde ich es?
Ziele
- Nennen und lokalisieren Sie wissenschaftliche Python-Community-Seiten für Software, Workshops und Hilfe.
Leslie Lamport sagte einmal: “Schreiben ist die Art der Natur, dir zu zeigen, wie schlampig dein Denken ist.” Das Gleiche gilt für das Programmieren: Viele Dinge, die offensichtlich erscheinen, wenn wir über sie nachdenken, erweisen sich als etwas anderes, wenn wir sie genau erklären müssen.
Python unterstützt eine große und vielfältige Gemeinschaft im akademischen Bereich und in der Industrie.
Die Python 3 Dokumentation behandelt die Kernsprache und die Standardbibliothek.
PyCon ist die größte jährliche Konferenz für die Python-Gemeinschaft.
SciPy ist eine umfangreiche Sammlung wissenschaftlicher Hilfsprogramme. Es ist auch der Name von einer Reihe von jährlichen Konferenzen.
Jupyter ist die Heimat des Projekts Jupyter.
Pandas ist die Heimat der Pandas-Datenbibliothek.
Stack Overflow’s general Python section kann hilfreich sein, ebenso wie die Abschnitte über NumPy, SciPy, und Pandas.
- Python unterstützt eine große und vielfältige Gemeinschaft im akademischen Bereich und in der Industrie.
Content from Rückmeldung
Zuletzt aktualisiert am 2025-03-02 | Diese Seite bearbeiten
Übersicht
Fragen
- Wie ist der Kurs gelaufen?
Ziele
- Sammeln Sie Feedback zum Kurs
Sammeln Sie das Feedback der Teilnehmer.
- Wir sind ständig bemüht, diesen Kurs zu verbessern.