Tracciare
Ultimo aggiornamento il 2025-11-06 | Modifica questa pagina
Tempo stimato: 30 minuti
Panoramica
Domande
- Come posso tracciare i miei dati?
- Come posso salvare il mio grafico per la pubblicazione?
Obiettivi
- Crea un grafico di serie temporali che mostra una singola serie di dati.
- Crea un grafico a dispersione che mostra la relazione tra due serie di dati.
matplotlib è la
libreria di grafici scientifici più utilizzata in Python.
- Comunemente si usa una sottolibreria chiamata
matplotlib.pyplot. - Per impostazione predefinita, Jupyter Notebook esegue il rendering dei grafici.
- I grafici semplici si creano (abbastanza) facilmente
PYTHON
time = [0, 1, 2, 3]
position = [0, 100, 200, 300]
plt.plot(time, position)
plt.xlabel('Time (hr)')
plt.ylabel('Position (km)') {alt=‘Un grafico a
linee che mostra il tempo (ore) rispetto alla posizione (km),
utilizzando i valori forniti nel blocco di codice precedente. Per
impostazione predefinita, la linea tracciata è blu su sfondo bianco e
gli assi sono stati scalati automaticamente per adattarsi all’intervallo
dei dati di input.’}
{alt=‘Un grafico a
linee che mostra il tempo (ore) rispetto alla posizione (km),
utilizzando i valori forniti nel blocco di codice precedente. Per
impostazione predefinita, la linea tracciata è blu su sfondo bianco e
gli assi sono stati scalati automaticamente per adattarsi all’intervallo
dei dati di input.’}
Visualizza tutte le figure aperte
Nel nostro esempio di Jupyter Notebook, l’esecuzione della cella dovrebbe generare la figura direttamente sotto il codice. La figura è anche inclusa nel documento del notebook per una visualizzazione futura. Tuttavia, altri ambienti Python, come una sessione Python interattiva avviata da un terminale o uno script Python eseguito dalla riga di comando, richiedono un comando aggiuntivo per visualizzare la figura.
Indica a matplotlib di mostrare una figura:
Questo comando può essere usato anche all’interno di un blocco note, ad esempio per visualizzare più figure se diverse sono state create da una singola cella.
Traccia i dati direttamente da un Pandas dataframe.
- È anche possibile tracciare Pandas dataframes.
- Prima di tracciare, convertiamo le intestazioni delle colonne da un
tipo di dati
stringainteger, poiché rappresentano valori numerici, usando str.replace() per rimuovere il prefissogpdPercap_e poi astype(int) per convertire la serie di valori stringa (['1952', '1957', ..., '2007']) in una serie di interi:[1925, 1957, ..., 2007].
PYTHON
import pandas as pd
data = pd.read_csv('data/gapminder_gdp_oceania.csv', index_col='country')
# Estrae l’anno dagli ultimi 4 caratteri di ciascun nome di colonna.
# I nomi delle colonne attuali sono nella forma 'gdpPercap_(anno)',
# quindi vogliamo mantenere solo la parte (anno) per rendere più chiaro il grafico PIL vs anni.
# Usiamo il metodo replace(), che rimuove dalla stringa i caratteri specificati come argomento.
# Questo metodo agisce su stringhe, quindi utilizziamo replace() attraverso le funzioni vettorializzate per stringhe di Pandas (Series.str).
years = data.columns.str.replace('gdpPercap_', '')
# Converte i valori degli anni in interi e salva i risultati di nuovo nel DataFrame.
data.columns = years.astype(int)
data.loc['Australia'].plot() {alt=‘Grafico del PIL per
l’Australia’}
{alt=‘Grafico del PIL per
l’Australia’}
Seleziona e trasforma i dati, quindi li traccia.
- Per impostazione predefinita,
DataFrame.plotesegue il grafico con le righe come asse X. - È possibile trasporre i dati per tracciare serie multiple.

Sono disponibili molti stili di grafico.
- Ad esempio, si può creare un grafico a barre utilizzando uno stile più sofisticato.
 {alt=‘Grafico a barre del PIL per
l’Australia’}
{alt=‘Grafico a barre del PIL per
l’Australia’}
I dati possono essere tracciati anche chiamando direttamente la
funzione matplotlib plot.
- Il comando è
plt.plot(x, y) - Il colore e il formato dei marcatori possono essere specificati come
argomento opzionale aggiuntivo, ad esempio
b-è una linea blu,g--è una linea verde tratteggiata.
Ottenere i dati sull’Australia dal dataframe
PYTHON
years = data.columns
gdp_australia = data.loc['Australia']
plt.plot(years, gdp_australia, 'g--') {alt=‘Grafico
formattato del PIL per l’Australia’}
{alt=‘Grafico
formattato del PIL per l’Australia’}
Può tracciare molti insiemi di dati contemporaneamente.
PYTHON
# Selezionare i dati relativi a due Paesi
gdp_australia = data.loc['Australia']
gdp_nz = data.loc['New Zealand']
# Graficali con due diversi colori.
plt.plot(years, gdp_australia, 'b-', label='Australia')
plt.plot(years, gdp_nz, 'g-', label='New Zealand')
# Creare una legenda.
plt.legend(loc='upper left')
plt.xlabel('Year')
plt.ylabel('GDP per capita ($)')Aggiunta di una legenda
Spesso quando si tracciano più insiemi di dati sulla stessa figura è auspicabile avere una legenda che descriva i dati.
Questo può essere fatto in matplotlib in due fasi:
- Fornisce un’etichetta per ogni serie di dati nella figura:
PYTHON
plt.plot(years, gdp_australia, label='Australia')
plt.plot(years, gdp_nz, label='New Zealand')- Indica a
matplotlibdi creare la legenda.
Per impostazione predefinita, matplotlib tenta di posizionare la
legenda in una posizione centrale. Se si preferisce specificare una
posizione, è possibile farlo con l’argomento loc=, ad
esempio per posizionare la legenda nell’angolo superiore sinistro del
grafico, specificare loc='upper left'

- Traccia un grafico a dispersione che mette in relazione il PIL di Australia e Nuova Zelanda
- Utilizzare
plt.scatteroDataFrame.plot.scatter


Minimi e massimi
Compilate gli spazi vuoti qui sotto per tracciare il PIL minimo pro capite nel tempo per tutti i paesi europei. Modificatelo di nuovo per tracciare il PIL pro capite massimo nel tempo per l’Europa.

Correlazioni
Modificate l’esempio nelle note per creare un grafico a dispersione che mostri la relazione tra il PIL pro capite minimo e massimo dei paesi asiatici per ogni anno dell’insieme di dati. Quale relazione vedete (se esiste)?
PYTHON
data_asia = pd.read_csv('data/gapminder_gdp_asia.csv', index_col='country')
data_asia.describe().T.plot(kind='scatter', x='min', y='max')
Non si notano particolari correlazioni tra i valori minimi e massimi del PIL anno per anno. Sembra che le fortune dei paesi asiatici non salgano e non scendano insieme.
Correlazioni (continued)
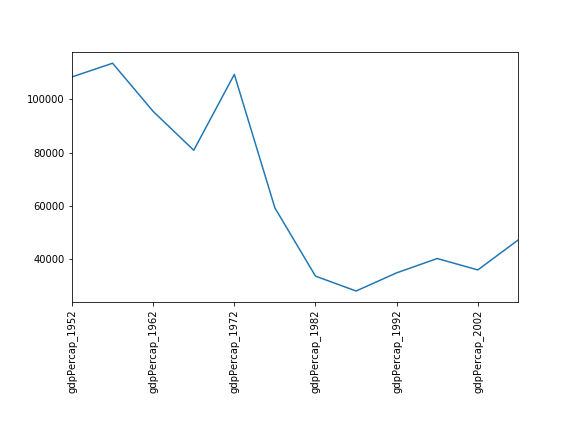
Sembra che la variabilità di questo valore sia dovuta a un forte calo dopo il 1972. Forse è in gioco la geopolitica? Data la predominanza dei paesi produttori di petrolio, forse l’indice del Brent potrebbe essere un confronto interessante? Mentre il Myanmar ha costantemente il PIL più basso, la nazione con il PIL più alto ha subito variazioni più marcate.
Altre correlazioni
Questo breve programma crea un grafico che mostra la correlazione tra il PIL e l’aspettativa di vita per il 2007, normalizzando il marker in base alla popolazione:
PYTHON
data_all = pd.read_csv('data/gapminder_all.csv', index_col='country')
data_all.plot(kind='scatter', x='gdpPercap_2007', y='lifeExp_2007',
s=data_all['pop_2007']/1e6)Utilizzando la guida in linea e altre risorse, spiegate cosa fa ogni
argomento di plot.

Un buon punto di partenza è la documentazione della funzione plot - help(data_all.plot).
kind - Come già visto, determina il tipo di grafico da disegnare.
x e y - Nome di una colonna o indice che determina quali dati saranno posizionati sugli assi x e y del grafico
s - I dettagli sono disponibili nella documentazione di plt.scatter. Un singolo numero o un valore per ogni punto di dati. Determina la dimensione dei punti tracciati.
Salvataggio del grafico in un file
Se siete soddisfatti del grafico che vedete, potreste volerlo salvare in un file, magari per includerlo in una pubblicazione. Esiste una funzione nel modulo matplotlib.pyplot che permette di farlo: savefig. Chiamando questa funzione, ad esempio con
salva la figura corrente nel file my_figure.png. Il
formato del file viene automaticamente dedotto dall’estensione del nome
del file (altri formati sono pdf, ps, eps e svg).
Si noti che le funzioni in plt fanno riferimento a una
variabile globale di figura e dopo che una figura è stata visualizzata
sullo schermo (ad esempio con plt.show) matplotlib farà in
modo che questa variabile faccia riferimento a una nuova figura vuota.
Pertanto, assicurarsi di chiamare plt.savefig prima che il
grafico venga visualizzato sullo schermo, altrimenti si potrebbe trovare
un file con un grafico vuoto.
Quando si usano i dataframe, i dati vengono spesso generati e
tracciati sullo schermo in un’unica riga. Oltre a usare
plt.savefig, si può salvare un riferimento alla figura
corrente in una variabile locale (con plt.gcf) e chiamare
il metodo della classe savefig da quella variabile per
salvare la figura su file.
Rendere accessibili i grafici
Ogni volta che si generano grafici da inserire in un documento o in una presentazione, ci sono alcune cose da fare per assicurarsi che tutti possano capire i grafici.
- Assicuratevi sempre che il testo sia abbastanza visibile da essere
letto. Usate il parametro
fontsizeinxlabel,ylabel,titleelegendetick_paramsconlabelsizeper aumentare la dimensione del testo dei numeri sugli assi. - Allo stesso modo, è necessario che gli elementi del grafico siano
facili da vedere. Usate
sper aumentare le dimensioni dei marcatori del grafico di dispersione elinewidthper aumentare le dimensioni delle linee del grafico. - L’uso del colore (e di nient’altro) per distinguere i diversi
elementi del grafico renderà i grafici illeggibili a chiunque sia
daltonico o abbia una stampante da ufficio in bianco e nero. Per le
linee, il parametro
linestyleconsente di utilizzare diversi tipi di linee. Per i diagrammi di dispersione, il parametromarkerconsente di modificare la forma dei punti. Se non si è sicuri dei colori, si può usare Coblis o Color Oracle per simulare l’aspetto dei grafici per le persone affette da daltonismo.
-
matplotlibè la libreria di grafici scientifici più utilizzata in Python. - Grafica i dati direttamente da un dataframe Pandas.
- Selezionare e trasformare i dati, quindi graficarli.
- Sono disponibili molti stili di grafico: per ulteriori opzioni, consultare la Python Graph Gallery.
- Si possono graficare molti insiemi di dati insieme.