Todo en una sola página
Content from Ejecutar y salir
Última actualización: 2025-07-01 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo ejecutar programas Python?
Objetivos
- Inicia el servidor de JupyterLab.
- Crea un nuevo script Python.
- Crea un cuaderno Jupyter.
- Apaga el servidor de JupyterLab.
- Comprender la diferencia entre un script Python y un cuaderno Jupyter.
- Crea celdas Markdown en un cuaderno.
- Crear y ejecutar celdas de Python en un cuaderno.
Para ejecutar Python, vamos a utilizar Jupyter Notebooks a través de JupyterLab para el resto de este taller. Los cuadernos Jupyter son comunes en la ciencia de datos y visualización, y sirven como una experiencia conveniente para ejecutar código Python de forma interactiva donde podemos ver y compartir fácilmente los resultados de nuestro código Python.
Existen otras formas de editar, gestionar y ejecutar código. Los desarrolladores de software suelen utilizar un entorno de desarrollo integrado (IDE) como PyCharm o Visual Studio Code, o editores de texto como Vim o Emacs, para crear y editar sus programas Python. Después de editar y guardar sus programas Python puede ejecutar esos programas dentro del propio IDE o directamente en la línea de comandos. En cambio, los cuadernos Jupyter nos permiten ejecutar y ver los resultados de nuestro código Python inmediatamente dentro del cuaderno.
JupyterLab tiene otras funciones muy útiles:
- Puedes escribir, editar y copiar y pegar fácilmente bloques de código.
- En pestaña completa te permite acceder fácilmente a los nombres de las cosas que estás utilizando y aprender más sobre ellas.
- Te permite anotar tu código con enlaces, texto de distinto tamaño, viñetas, etc. para hacerlo más accesible a ti y a tus colaboradores.
- Te permite mostrar figuras junto al código que las produce para contar una historia completa del análisis.
Cada cuaderno contiene una o más celdas que contienen código, texto o imágenes.
Introducción a JupyterLab
JupyterLab es un servidor de aplicaciones con interfaz web de usuario del Proyecto Jupyter que permite trabajar con documentos y actividades como cuadernos Jupyter, editores de texto, terminales e incluso componentes personalizados de forma flexible, integrada y extensible. JupyterLab requiere un navegador razonablemente actualizado (idealmente una versión actual de Chrome, Safari o Firefox); las versiones 9 e inferiores de Internet Explorer no son compatibles.
JupyterLab se incluye como parte de la distribución Anaconda Python. Si aún no has instalado la distribución Anaconda Python, consulta las instrucciones de instalación para obtener instrucciones de instalación.
En esta lección ejecutaremos JupyterLab localmente en nuestras propias máquinas, por lo que no será necesaria una conexión a Internet aparte de la conexión inicial para descargar e instalar Anaconda y JupyterLab
- Inicia el servidor de JupyterLab en tu máquina
- Utiliza un navegador web para abrir una URL localhost especial que conecte con tu servidor JupyterLab
- El servidor de JupyterLab hace el trabajo y el navegador web muestra el resultado
- Escriba código en el navegador y vea los resultados después de que su servidor JupyterLab haya terminado de ejecutar su código
¿JupyterLab? ¿Y para los cuadernos Jupyter?
JupyterLab es la siguiente etapa en la evolución del Jupyter Notebook. Si tienes experiencia previa trabajando con cuadernos Jupyter, entonces tendrás una buena idea de qué esperar de JupyterLab.
Los usuarios experimentados de Jupyter notebooks interesados en una discusión más detallada de las similitudes y diferencias entre las interfaces de usuario de JupyterLab y Jupyter notebook pueden encontrar más información en la documentación de la interfaz de usuario de JupyterLab.
Iniciando JupyterLab
Puede iniciar el servidor JupyterLab a través de la línea de comandos
o a través de una aplicación llamada Anaconda Navigator.
Anaconda Navigator se incluye como parte de la distribución Anaconda
Python.
macOS - Línea de comandos
Para iniciar el servidor de JupyterLab necesitarás acceder a la línea de comandos a través del Terminal. Hay dos formas de abrir Terminal en Mac.
- En la carpeta Aplicaciones, abre Utilidades y haz doble clic en Terminal
- Pulsa Comando + barra espaciadora para iniciar
Spotlight. Escriba
Terminaly, a continuación, haga doble clic en el resultado de la búsqueda o pulse Intro
Después de lanzar Terminal, escribe el comando para lanzar el servidor JupyterLab.
Usuarios de Windows - Línea de comandos
Para iniciar el servidor de JupyterLab necesitarás acceder al Prompt de Anaconda.
Pulsa Tecla del logotipo de Windows y busca
Anaconda Prompt, haz clic en el resultado o pulsa
intro.
Después de haber lanzado Anaconda Prompt, escriba el comando:
Navegador Anaconda
Para iniciar un servidor JupyterLab desde Anaconda Navigator primero
debes iniciar
Anaconda Navigator (haz clic para obtener instrucciones detalladas en
macOS, Windows y Linux). Puedes buscar Anaconda Navigator a través
de Spotlight en macOS (Comando + barra
espaciadora), la función de búsqueda de Windows (Tecla del
logotipo de Windows) o abriendo un intérprete de comandos de
terminal y ejecutando el ejecutable anaconda-navigator
desde la línea de comandos.
Después de iniciar el Navegador Anaconda, haz clic en el botón
Launch debajo de JupyterLab. Puede que tengas que
desplazarte hacia abajo para encontrarlo.
He aquí una captura de pantalla de una página de Anaconda Navigator similar a la que debería abrirse en macOS o Windows.

Y aquí tienes una captura de pantalla de una página de inicio de JupyterLab que debería ser similar a la que se abre en tu navegador web predeterminado después de iniciar el servidor de JupyterLab en macOS o Windows.
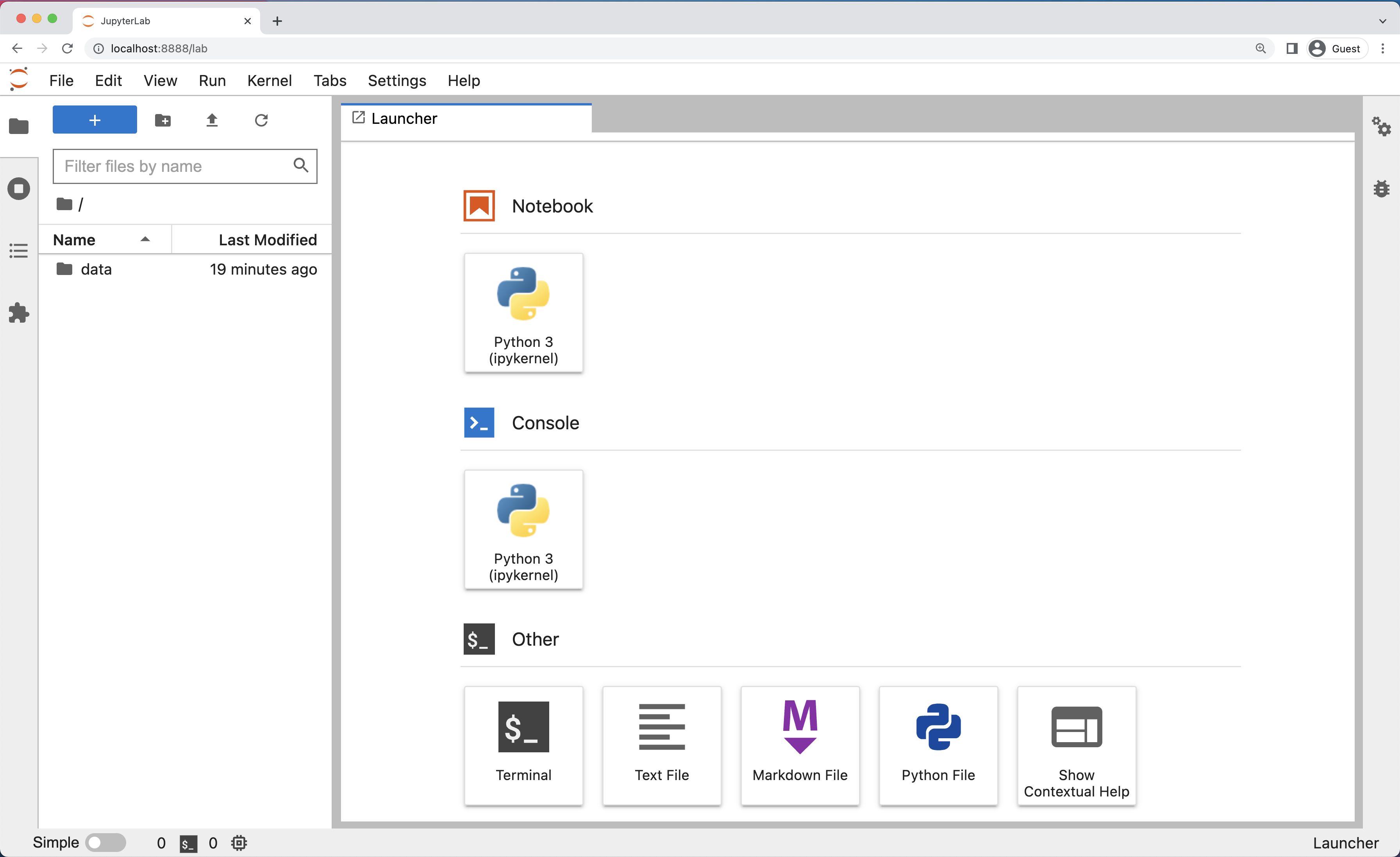
La interfaz de JupyterLab
JupyterLab tiene muchas características que se encuentran en los entornos de desarrollo integrados (IDE) tradicionales, pero se centra en proporcionar bloques de construcción flexibles para la computación interactiva y exploratoria.
La Interfaz de JupyterLab consiste en la Barra de Menú, una Barra Lateral Izquierda colapsable, y el Área de Trabajo Principal que contiene pestañas de documentos y actividades.
Barra de menús
La Barra de Menús en la parte superior de JupyterLab tiene los menús de nivel superior que exponen varias acciones disponibles en JupyterLab junto con sus atajos de teclado (donde sea aplicable). Los siguientes menús están incluidos por defecto.
- Archivo: Acciones relacionadas con archivos y directorios como Nuevo, Abrir, Cerrar, Guardar, etc. El menú Archivo también incluye la acción Apagar utilizada para apagar el servidor de JupyterLab.
- Edición: Acciones relacionadas con la edición de documentos y otras actividades como Deshacer, Cortar, Copiar, Pegar, etc.
- Ver: Acciones que alteran la apariencia de JupyterLab.
- Ejecutar: Acciones para ejecutar código en diferentes actividades como cuadernos y consolas de código (discutidas más adelante).
- Kernel: Acciones para gestionar kernels. Los kernels en Jupyter se explicarán con más detalle a continuación.
- Pestañas: Una lista de los documentos y actividades abiertos en el área de trabajo principal.
- Configuración: Los ajustes comunes de JupyterLab pueden configurarse usando este menú. También hay una opción Editor de Ajustes Avanzados en el menú desplegable que proporciona un control más fino de los ajustes de JupyterLab y las opciones de configuración.
- Ayuda: Una lista de enlaces de ayuda de JupyterLab y del kernel.
Núcleos
Los [docs] de JupyterLab(https://jupyterlab.readthedocs.io/en/stable/user/documents_kernels.html) definen los kernels como “procesos separados iniciados por el servidor que ejecuta tu código en diferentes lenguajes y entornos de programación.” Cuando abrimos un Jupyter Notebook, se inicia un kernel - un proceso - que va a ejecutar el código. En esta lección, utilizaremos el kernel ipython de Jupyter que nos permite ejecutar código Python 3 de forma interactiva.
El uso de otros [kernels para otros lenguajes de programación] de Jupyter (https://github.com/jupyter/jupyter/wiki/Jupyter-kernels) nos permitiría escribir y ejecutar código en otros lenguajes de programación en la misma interfaz de JupyterLab, como R, Java, Julia, Ruby, JavaScript, Fortran, etc.
A continuación se muestra una captura de pantalla de la Barra de Menús por defecto.

Barra lateral izquierda
La barra lateral izquierda contiene una serie de pestañas de uso común, como un explorador de archivos (que muestra el contenido del directorio en el que se inició el servidor JupyterLab), una lista de kernels y terminales en ejecución, la paleta de comandos y una lista de pestañas abiertas en el área de trabajo principal. A continuación se muestra una captura de pantalla de la barra lateral izquierda por defecto.
La barra lateral izquierda puede contraerse o expandirse seleccionando “Mostrar barra lateral izquierda” en el menú Ver o haciendo clic en la pestaña de la barra lateral activa.
Área de trabajo principal
El área de trabajo principal de JupyterLab permite organizar los documentos (cuadernos, archivos de texto, etc.) y otras actividades (terminales, consolas de código, etc.) en paneles de pestañas que se pueden redimensionar o subdividir. A continuación se muestra una captura de pantalla del Área de trabajo principal por defecto.
Si no ves la pestaña Launcher, haz clic en el signo más azul bajo los menús “Archivo” y “Editar” y aparecerá.
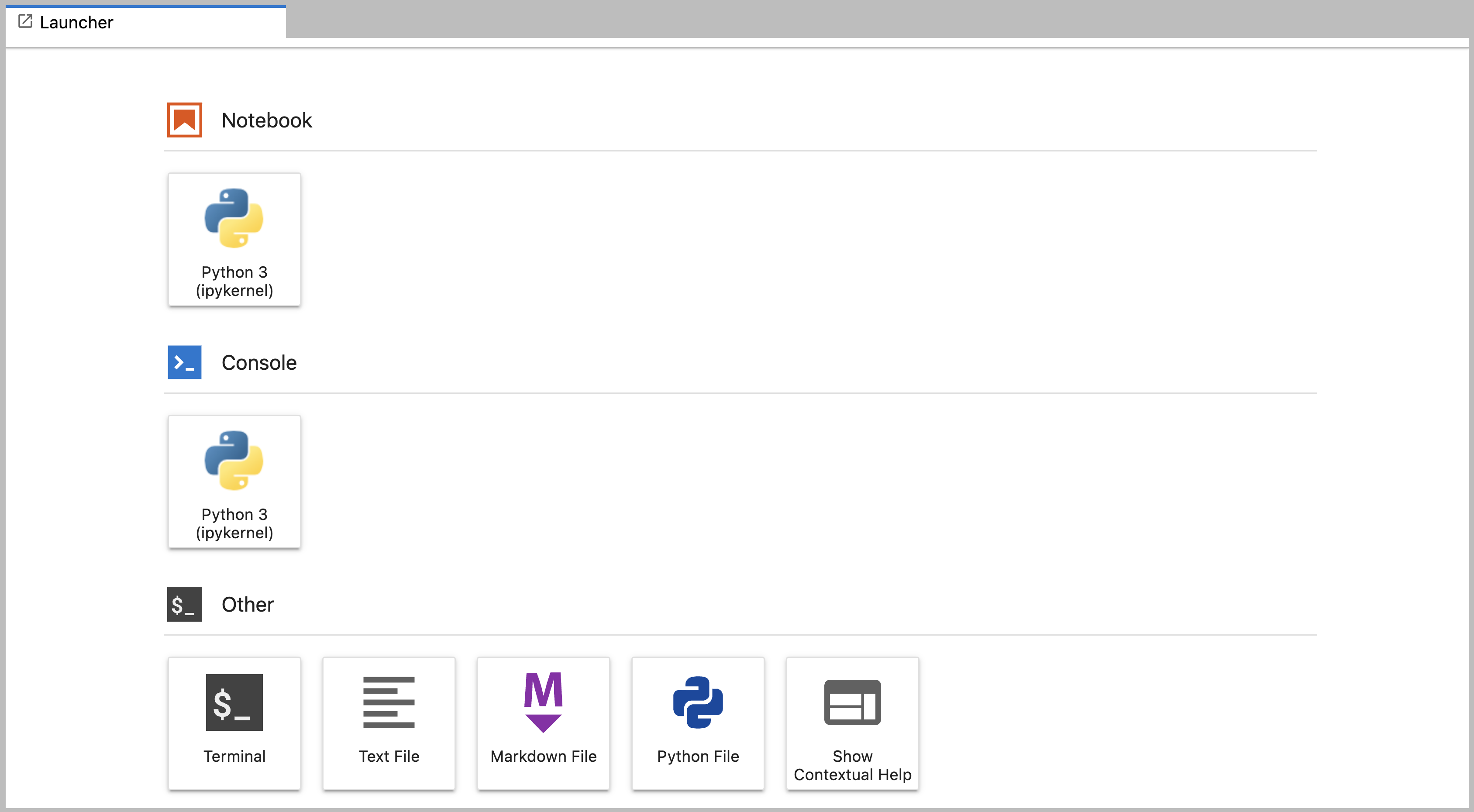
Arrastre una pestaña al centro de un panel de pestañas para mover la pestaña al panel. Subdividir un panel de pestañas arrastrando una pestaña a la izquierda, derecha, parte superior o inferior del panel. El área de trabajo tiene una única actividad actual. La pestaña de la actividad actual está marcada con un borde superior de color (azul por defecto).
Creación de un script Python
- Para empezar a escribir un nuevo programa Python haz clic en el
icono Archivo de Texto bajo la cabecera Others en la pestaña
Lanzador del Área de Trabajo Principal.
- También puede crear un nuevo archivo de texto sin formato seleccionando New -> Textfile en el menú File de la barra de menús.
- Para convertir este archivo de texto plano en un programa Python,
selecciona la acción Save file as del menú File en la
Barra de Menú y dale a tu nuevo archivo de texto un nombre que termine
con la extensión
.py.- La extensión
.pypermite a todo el mundo (incluido el sistema operativo) saber que este archivo de texto es un programa Python. - Esto es una convención, no un requisito.
- La extensión
Crear un cuaderno Jupyter
Para abrir un nuevo cuaderno haz clic en el icono Python 3 bajo la cabecera Notebook en la pestaña Lanzador del área de trabajo principal. También puedes crear un nuevo cuaderno seleccionando New -> Notebook en el menú File de la Barra de Menús.
Notas adicionales sobre los cuadernos Jupyter.
- Los archivos de cuaderno tienen la extensión
.ipynbpara distinguirlos de los programas Python de texto plano. - Los cuadernos pueden exportarse como scripts de Python que pueden ejecutarse desde la línea de comandos.
A continuación se muestra una captura de pantalla de un cuaderno Jupyter ejecutándose dentro de JupyterLab. Si estás interesado en más detalles, consulta la documentación oficial del cuaderno.
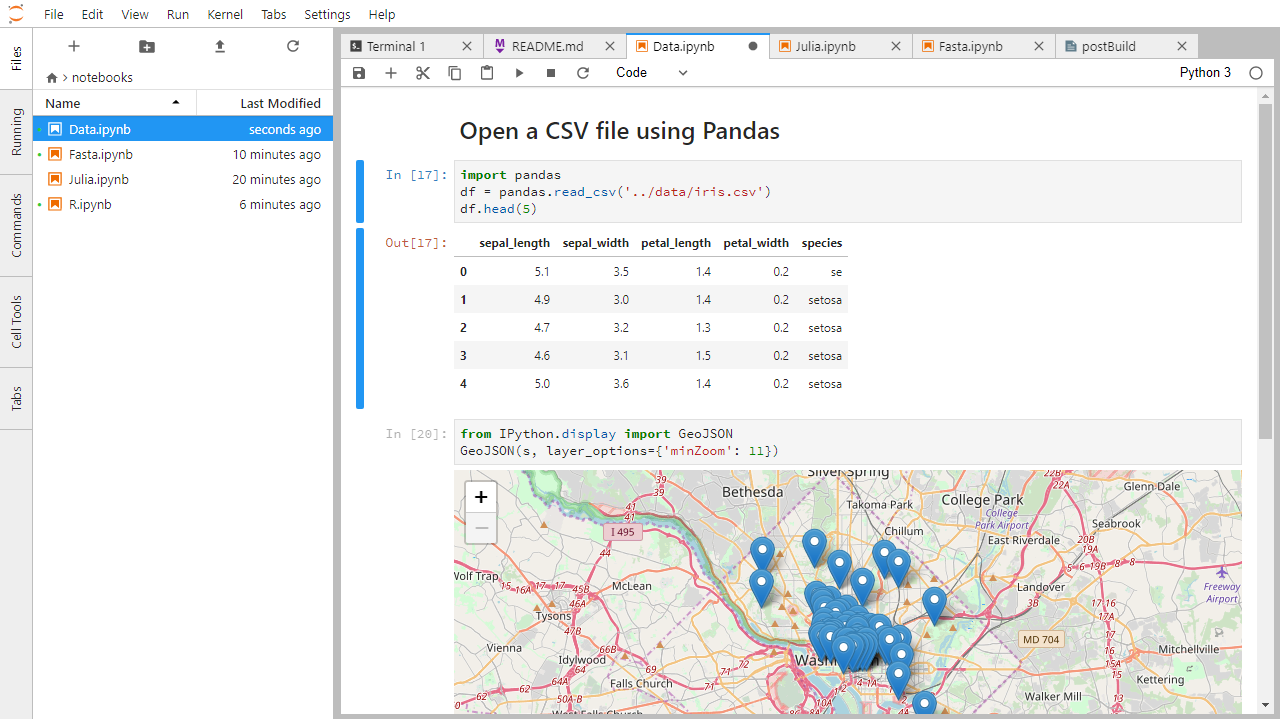
Cómo se almacena
- El archivo del cuaderno se almacena en un formato llamado JSON.
- Al igual que una página web, lo que se guarda tiene un aspecto diferente de lo que se ve en el navegador.
- Pero este formato permite a Jupyter mezclar código fuente, texto e imágenes, todo en un mismo archivo.
Organizar documentos en paneles de pestañas
En el área de trabajo principal de JupyterLab puedes organizar los documentos en paneles de pestañas. Aquí tienes un ejemplo de la documentación oficial.
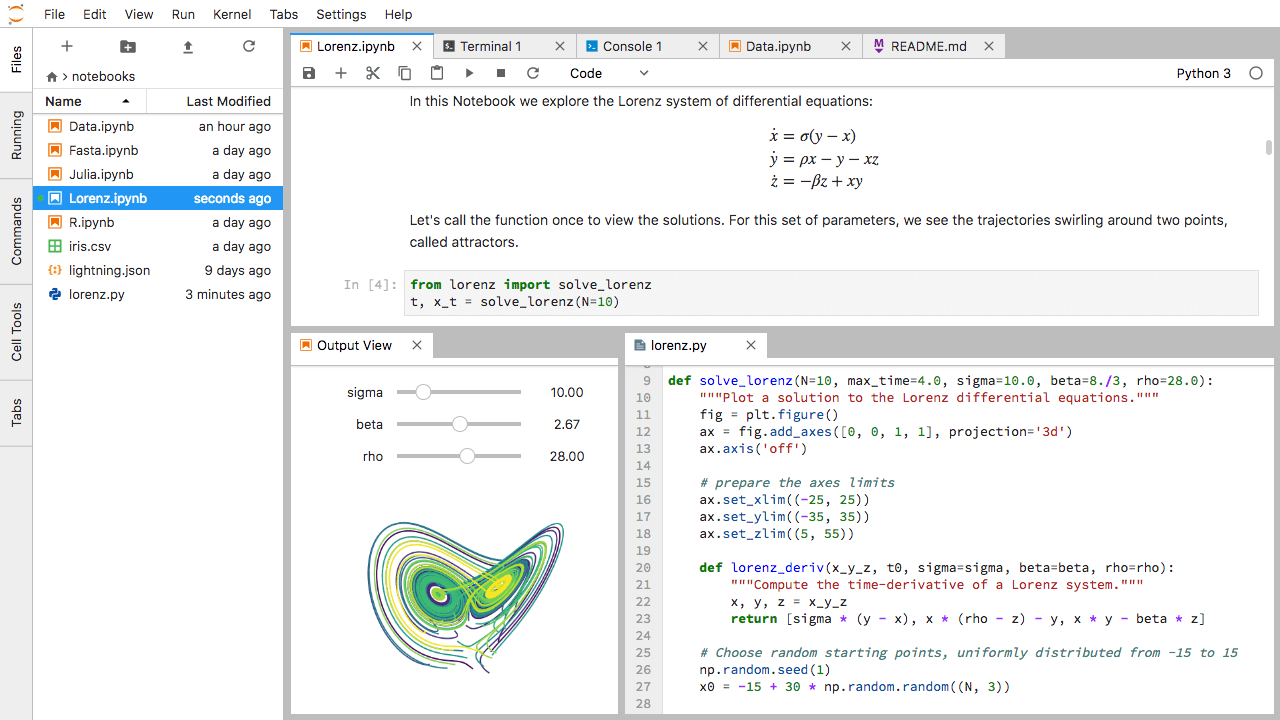
En primer lugar, cree un archivo de texto, una consola Python y una ventana de terminal y dispóngalos en tres paneles en el área de trabajo principal. A continuación, cree un cuaderno, una ventana de terminal y un archivo de texto y dispóngalos en tres paneles en el área de trabajo principal. Por último, crea tu propia combinación de paneles y pestañas. ¿Qué combinación de paneles y pestañas crees que será más útil para tu flujo de trabajo?
Después de crear las pestañas necesarias, puedes arrastrar una de las pestañas al centro de un panel para mover la pestaña al panel; después puedes subdividir un panel de pestañas arrastrando una pestaña a la izquierda, derecha, parte superior o inferior del panel.
Código vs. Texto
Jupyter mezcla código y texto en diferentes tipos de bloques, llamados celdas. A menudo utilizamos el término “código” para referirnos al “código fuente del software escrito en un lenguaje como Python”. Una “celda de código” en un Cuaderno es una celda que contiene software; una “celda de texto” es una que contiene prosa ordinaria escrita para seres humanos.
El Cuaderno dispone de los modos Comando y Edición.
- Si pulsa Esc y Return alternativamente, el borde exterior de su celda de código cambiará de gris a azul.
- Estos son los modos Command/Comando (gris) y Edit/Edición (azul) de tu bloc de notas.
- El modo Comando te permite editar las características del cuaderno, y el modo Edición cambia el contenido de las celdas.
- En modo Comando (esc/gris),
- La tecla b creará una nueva celda debajo de la celda seleccionada actualmente.
- La tecla a hará una arriba.
- La tecla x borrará la celda actual.
- La tecla z deshará su última operación de celda (que podría ser una eliminación, creación, etc.).
- Todas las acciones se pueden realizar utilizando los menús, pero hay muchos atajos de teclado para agilizar las cosas.
Comando Vs. Edición
En la página del cuaderno Jupyter, ¿estás actualmente en modo Comando
o Edición?
Cambia entre los modos. Utiliza los atajos para generar una nueva celda.
Utiliza los atajos para borrar una celda. Utiliza los atajos para
deshacer la última operación de celda realizada.
El modo Comando tiene un borde gris y el modo Edición tiene un borde azul. Utilice Esc y Return para cambiar de un modo a otro. Necesitas estar en modo Comando (Pulsa Esc si tu celda es azul). Escribe b o a. Tienes que estar en modo Comando (Pulsa Esc si tu celda es azul). Escriba x. Tienes que estar en modo Comando (Pulsa Esc si tu celda es azul). Escriba z.
Utiliza el teclado y el ratón para seleccionar y editar celdas.
- Al pulsar la tecla Return, el borde se vuelve azul y se activa el modo Edición, que permite escribir dentro de la celda.
- Como queremos poder escribir muchas líneas de código en una sola celda, al pulsar la tecla Retorno cuando se está en modo Edición (azul) se mueve el cursor a la siguiente línea de la celda, igual que en un editor de texto.
- Necesitamos alguna otra forma de decirle al Notebook que queremos ejecutar lo que hay en la celda.
- Al pulsar conjuntamente Mayús+Retorno se ejecutará el contenido de la celda.
- Observa que las teclas Return y Shift de la derecha del teclado están una al lado de la otra.
El Cuaderno convertirá Markdown en documentación con una bonita impresión.
- Los cuadernos también pueden renderizar Markdown.
- Un sencillo formato de texto plano para escribir listas, enlaces y otras cosas que podrían ir en una página web.
- Equivalentemente, un subconjunto de HTML que se parece a lo que enviarías en un correo electrónico a la antigua usanza.
- Convierte la celda actual en una celda Markdown entrando en el modo Comando (Esc/gris) y pulsa la tecla M.
-
In [ ]:desaparecerá para mostrar que ya no es una celda de código y podrás escribir en Markdown. - Convierta la celda actual en una celda de Código entrando en el modo Comando (Esc/gris) y pulse la tecla y.
Markdown hace la mayor parte de lo que hace HTML.
Tabla: Mostrando algo de sintaxis markdown y su salida renderizada.
| Markdown code | Rendered output |
|---|---|
|
|
|
|
|
|
|
A Level-1 Heading |
|
A Level-2 Heading (etc.) |
|
Line breaks don’t matter. But blank lines create new paragraphs. |
|
Links are created with
|
Creación de listas en Markdown
Crea una lista anidada en una celda Markdown de un cuaderno con el siguiente aspecto:
- Obtener financiación.
- Haz el trabajo.
- Experimento de diseño.
- Recopilar datos.
- Analizar.
- Escribe.
- Publicar.
Este reto integra tanto la lista numerada como la lista con viñetas. Observe que la lista con viñetas está sangrada 2 espacios para que esté en línea con los elementos de la lista numerada.
1. Get funding.
2. Do work.
* Design experiment.
* Collect data.
* Analyze.
3. Write up.
4. Publish.Cambiar una celda existente de código a Markdown
¿Qué ocurre si escribes algo de Python en una celda de código y luego lo cambias a una celda de Markdown? Por ejemplo, pon lo siguiente en una celda de código:
Y luego ejecútalo con Shift+Return para asegurarte de que funciona como una celda de código. Ahora vuelve a la celda y usa Esc y luego m para cambiar la celda a Markdown y “ejecútala” con Shift+Return. ¿Qué ha pasado y en qué puede ser útil?
Ecuaciones
Markdown estándar (como el que estamos utilizando para estas notas) no mostrará ecuaciones, pero Notebook sí. Crea una nueva celda Markdown e introduce lo siguiente:
$\sum_{i=1}^{N} 2^{-i} \approx 1$(Probablemente sea más fácil copiar y pegar.) ¿Qué muestra? ¿Qué
crees que hacen el guión bajo, _, el circunflejo,
^, y el símbolo del dólar, $?
El cuaderno muestra la ecuación tal y como se representaría a partir
de la sintaxis de ecuaciones de LaTeX. El signo del dólar,
$, se utiliza para indicar a Markdown que el texto
intermedio es una ecuación LaTeX. Si no está familiarizado con LaTeX, el
guión bajo, _, se utiliza para los subíndices y el
circunflejo, ^, para los superíndices. Un par de llaves,
{ y }, se utilizan para agrupar texto de forma
que la expresión i=1 se convierta en subíndice y
N en superíndice. Del mismo modo, -i está
entre llaves para que toda la expresión sea el superíndice de
2.\sum y \approx son comandos
LaTeX para los símbolos “suma sobre” y “aproxima”.
Cerrar JupyterLab
- En la barra de menús, seleccione el menú “File” y, a continuación, elija “Shut down” en la parte inferior del menú desplegable. Se le pedirá que confirme que desea apagar el servidor JupyterLab (¡no olvide guardar su trabajo!). Haga clic en “Shut Down” para apagar el servidor JupyterLab.
- Para reiniciar el servidor de JupyterLab tendrás que volver a ejecutar el siguiente comando desde un intérprete de comandos.
$ jupyter labCerrar JupyterLab
Practica cerrando y reiniciando el servidor de JupyterLab.
- Los scripts de Python son archivos de texto sin formato.
- Utiliza el Jupyter Notebook para editar y ejecutar Python.
- El Notebook dispone de los modos Command y Edition.
- Utilizar el teclado y el ratón para seleccionar y editar celdas.
- El Cuaderno convertirá Markdown en documentación con una bonita impresión.
- Markdown hace la mayor parte de lo que hace HTML.
Content from Variables y asignación
Última actualización: 2025-02-28 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo almacenar datos en los programas?
Objetivos
- Escribe programas que asignen valores escalares a variables y realicen cálculos con esos valores.
- Trazar correctamente cambios de valor en programas que usan asignación escalar.
Usa variables para almacenar valores.
Variables son nombres para valores.
-
Nombres de variables
-
sólo puede contener letras, dígitos y el guión bajo
_(típicamente usado para separar palabras en nombres largos de variables) - no puede empezar por un dígito
- son sensibles a mayúsculas (edad, Age y AGE son tres variables diferentes)
-
sólo puede contener letras, dígitos y el guión bajo
El nombre también debe ser significativo para que usted u otro programador sepa lo que es
Los nombres de variables que empiezan con guiones bajos como
__alistairs_real_agetienen un significado especial, así que no lo haremos hasta que entendamos la convención.En Python el símbolo
=asigna el valor de la derecha al nombre de la izquierda.La variable se crea cuando se le asigna un valor.
-
Aquí, Python asigna una edad a la variable
agey un nombre entre comillas a la variablefirst_name.
Usa print para mostrar valores.
- Python tiene una función integrada llamada
printque imprime cosas como texto. - Llama a la función (es decir, dile a Python que la ejecute) utilizando su nombre.
- Proporcione valores a la función (es decir, las cosas a imprimir) entre paréntesis.
- Para añadir una cadena a la impresión, encierre la cadena entre comillas simples o dobles.
- Los valores pasados a la función se llaman argumentos
SALIDA
Ahmed is 42 years old-
printpone automáticamente un espacio entre los elementos para separarlos. - Y se envuelve en una nueva línea al final.
Las variables deben ser creadas antes de ser usadas.
- Si una variable aún no existe, o si el nombre está mal escrito, Python informa de un error. (A diferencia de algunos lenguajes, que “adivinan” un valor por defecto)
ERROR
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-1-c1fbb4e96102> in <module>()
----> 1 print(last_name)
NameError: name 'last_name' is not defined- La última línea de un mensaje de error suele ser la más informativa.
- Veremos los mensajes de error en detalle más adelante.
Las variables persisten entre celdas
Ten en cuenta que lo importante en un cuaderno Jupyter es el orden de ejecución de las celdas, no el orden en que aparecen. Python recordará todo el código que se ejecutó previamente, incluyendo cualquier variable que hayas definido, independientemente del orden en el cuaderno. Por lo tanto, si defines variables más abajo en el cuaderno y luego (re)ejecutas celdas más arriba, las definidas más abajo seguirán presentes. Como ejemplo, cree dos celdas con el siguiente contenido, en este orden:
Si ejecutas esto en orden, la primera celda dará un error. Sin
embargo, si ejecutas la primera celda después de la segunda se
imprimirá 1. Para evitar confusiones, puede ser útil
utilizar la opción Kernel ->
Restart & Run All que limpia el intérprete y ejecuta
todo desde cero de arriba a abajo.
Las variables pueden usarse en cálculos.
- Podemos usar variables en cálculos como si fueran valores.
- Recuerda, asignamos el valor
42aagehace unas líneas.
- Recuerda, asignamos el valor
SALIDA
Age in three years: 45Usa un índice para obtener un único carácter de una cadena.
- Los caracteres (letras, números, etc.) de una cadena están
ordenados. Por ejemplo, la cadena
'AB'no es lo mismo que'BA'. Debido a este orden, podemos tratar la cadena como una lista de caracteres. - A cada posición en la cadena (primera, segunda, etc.) se le asigna un número. Este número se llama índice o a veces subíndice.
- Los índices se numeran desde 0.
- Usa el índice de la posición entre corchetes para obtener el carácter en esa posición.
SALIDA
hUsa un slice para obtener una subcadena.
- Una parte de una cadena se llama subcadena. Una subcadena puede ser tan corta como un solo carácter.
- Un elemento de una lista se llama elemento. Cuando tratamos una cadena como si fuera una lista, los elementos de la cadena son sus caracteres individuales.
- Un slice es una parte de una cadena (o, más generalmente, una parte de cualquier cosa parecida a una lista).
- Tomamos una porción con la notación
[start:stop], dondestartes el índice entero del primer elemento que queremos ystopes el índice entero del elemento justo después del último elemento que queremos. - La diferencia entre
stopystartes la longitud de la porción. - Tomar un slice no cambia el contenido de la cadena original. En su lugar, al tomar una porción se devuelve una copia de parte de la cadena original.
SALIDA
sodUsa la función len para encontrar la longitud de una
cadena.
SALIDA
6- Las funciones anidadas se evalúan de dentro a fuera, como en matemáticas.
Python distingue entre mayúsculas y minúsculas.
- Python piensa que las mayúsculas y minúsculas son diferentes, por lo
que
Nameynameson variables diferentes. - Hay convenciones para usar mayúsculas al principio de los nombres de las variables, así que por ahora usaremos minúsculas.
Usa nombres de variables con sentido.
- A Python no le importa cómo llames a las variables siempre que cumplan las reglas (caracteres alfanuméricos y guión bajo).
- Utiliza nombres de variables significativos para ayudar a otras personas a entender lo que hace el programa.
- La “otra persona” más importante es tu futuro yo.
SALIDA
# Command # Value of x # Value of y # Value of swap #
x = 1.0 # 1.0 # not defined # not defined #
y = 3.0 # 1.0 # 3.0 # not defined #
swap = x # 1.0 # 3.0 # 1.0 #
x = y # 3.0 # 3.0 # 1.0 #
y = swap # 3.0 # 1.0 # 1.0 #Estas tres líneas intercambian los valores en x y
y usando la variable swap para almacenamiento
temporal. Este es un lenguaje de programación bastante común.
Desafío
Si asignas a = 123, ¿qué pasa si intentas obtener el
segundo dígito de a mediante a[1]?
Los números no son cadenas o secuencias y Python dará un error si
intentas realizar una operación de índice en un número. En la próxima lección sobre tipos y conversión
de tipos aprenderemos más sobre tipos y cómo convertir entre
diferentes tipos. Si quieres el enésimo dígito de un número puedes
convertirlo en una cadena utilizando la función incorporada
str y luego realizar una operación de índice sobre esa
cadena.
ERROR
TypeError: 'int' object is not subscriptableSALIDA
2Elegir un Nombre
¿Qué nombre de variable es mejor, m, min o
minutes? Pista: piensa qué código preferirías heredar de
alguien que va a dejar el laboratorio:
ts = m * 60 + stot_sec = min * 60 + sectotal_seconds = minutes * 60 + seconds
minutes es mejor porque min puede
significar algo como “mínimo” (y en realidad es una función incorporada
en Python que veremos más adelante).
SALIDA
atom_name[1:3] is: arConceptos de rebanado
Dada la siguiente cadena:
¿Qué devolverían estas expresiones?
species_name[2:8]-
species_name[11:](sin valor después de los dos puntos) -
species_name[:4](sin valor antes de los dos puntos) -
species_name[:](sólo dos puntos) species_name[11:-3]species_name[-5:-3]- ¿Qué pasa cuando eliges un valor
stopque está fuera de rango? (por ejemplo, prueba conspecies_name[0:20]ospecies_name[:103])
-
species_name[2:8]devuelve la subcadena'acia b' -
species_name[11:]devuelve la subcadena'folia', desde la posición 11 hasta el final -
species_name[:4]devuelve la subcadena'Acac', desde el inicio hasta la posición 4, pero sin incluirla -
species_name[:]devuelve la cadena completa'Acacia buxifolia' -
species_name[11:-3]devuelve la subcadena'fo', desde la posición 11 hasta la antepenúltima posición -
species_name[-5:-3]también devuelve la subcadena'fo', desde la quinta última posición hasta la antepenúltima - Si una parte de la porción está fuera del rango, la operación no
falla.
species_name[0:20]da el mismo resultado quespecies_name[0:], yspecies_name[:103]da el mismo resultado quespecies_name[:]
- Utiliza variables para almacenar valores.
- Usa
printpara mostrar valores. - Las variables persisten entre celdas.
- Las variables deben crearse antes de usarse.
- Las variables pueden usarse en cálculos.
- Utiliza un índice para obtener un único carácter de una cadena.
- Usa un slice para obtener una subcadena.
- Usa la función
lenpara encontrar la longitud de una cadena. - Python distingue entre mayúsculas y minúsculas.
- Usa nombres de variables con sentido.
Content from Tipos de datos y conversión de tipos
Última actualización: 2025-07-01 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Qué tipo de datos almacenan los programas?
- ¿Cómo puedo convertir un tipo en otro?
Objetivos
- Explica las principales diferencias entre los números enteros y los de coma flotante.
- Explica las principales diferencias entre números y cadenas de caracteres.
- Utiliza funciones incorporadas para convertir entre enteros, números de coma flotante y cadenas.
Cada valor tiene un tipo.
- Cada valor en un programa tiene un tipo específico.
- Número entero (
int): representa números enteros positivos o negativos como 3 o -512. - Número en coma flotante (
float): representa números reales como 3.14159 o -2.5. - Cadena de caracteres (normalmente llamada “string”,
str): texto.- Escrita entre comillas simples o dobles (siempre que coincidan).
- Las comillas no se imprimen cuando se muestra la cadena.
Utilice la función incorporada type para encontrar el
tipo de un valor.
- Utilice la función incorporada
typepara averiguar qué tipo tiene un valor. - También funciona con variables.
- Pero recuerda: el valor tiene el tipo — la variable es sólo una etiqueta.
SALIDA
<class 'int'>SALIDA
<class 'str'>Los tipos controlan qué operaciones (o métodos) pueden realizarse sobre un valor dado.
- El tipo de un valor determina lo que el programa puede hacer con él.
SALIDA
2ERROR
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-2-67f5626a1e07> in <module>()
----> 1 print('hello' - 'h')
TypeError: unsupported operand type(s) for -: 'str' and 'str'Puede utilizar los operadores “+” y “*” en cadenas.
- “Sumar” cadenas de caracteres las concatena.
SALIDA
Ahmed Walsh- Al multiplicar una cadena de caracteres por un número entero
N se crea una nueva cadena que consiste en esa cadena de
caracteres repetida N veces.
- Dado que la multiplicación es una suma repetida.
SALIDA
==========Las cadenas tienen una longitud (pero los números no).
- La función incorporada
lencuenta el número de caracteres de una cadena.
SALIDA
11- Pero los números no tienen longitud (ni siquiera cero).
ERROR
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-3-f769e8e8097d> in <module>()
----> 1 print(len(52))
TypeError: object of type 'int' has no len()Debe convertir números en cadenas o viceversa cuando opera con ellos.
- No puede sumar números y cadenas.
ERROR
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-fe4f54a023c6> in <module>()
----> 1 print(1 + '2')
TypeError: unsupported operand type(s) for +: 'int' and 'str'- No está permitido porque es ambiguo: ¿debería
1 + '2'ser3o'12'? - Algunos tipos pueden convertirse en otros utilizando el nombre del tipo como función.
SALIDA
3
12Puede mezclar enteros y flotantes libremente en las operaciones.
- Los números enteros y los de coma flotante pueden mezclarse en
aritmética.
- Python 3 convierte automáticamente enteros a flotantes cuando es necesario.
SALIDA
half is 0.5
three squared is 9.0Las variables sólo cambian de valor cuando se les asigna algo.
- Si hacemos que una celda de una hoja de cálculo dependa de otra, y actualizamos esta última, la primera se actualiza automáticamente.
- Esto no ocurre en los lenguajes de programación.
PYTHON
variable_one = 1
variable_two = 5 * variable_one
variable_one = 2
print('first is', variable_one, 'and second is', variable_two)SALIDA
first is 2 and second is 5- El ordenador lee el valor de
variable_oneal hacer la multiplicación, crea un nuevo valor y se lo asigna avariable_two. - Después, el valor de
variable_twose fija al nuevo valor y no depende devariable_onepor lo que su valor no cambia automáticamente cuando cambiavariable_one.
Fracciones
¿Qué tipo de valor es 3.4? ¿Cómo puedes averiguarlo?
Conversión automática de tipos
¿Qué tipo de valor es 3,25 + 4?
Elija un tipo
¿Qué tipo de valor (entero, número de coma flotante o cadena de caracteres) utilizarías para representar cada uno de los siguientes elementos? Intenta dar más de una buena respuesta para cada problema. Por ejemplo, en # 1, ¿cuándo tendría más sentido contar los días con una variable de coma flotante que con un número entero?
- Número de días transcurridos desde el inicio del año.
- Tiempo transcurrido desde el inicio del año hasta ahora en días.
- Número de serie de un equipo de laboratorio.
- Edad de una muestra de laboratorio
- Población actual de una ciudad.
- Población media de una ciudad a lo largo del tiempo.
Las respuestas a las preguntas son:
- Número entero, ya que el número de días estaría comprendido entre 1 y 365.
- coma flotante, ya que se requieren días fraccionarios
- Cadena de caracteres si el número de serie contiene letras y números, en caso contrario entero si el número de serie consta sólo de números
- ¡Esto variará! ¿Cómo se define la edad de un espécimen? ¿días enteros desde la recogida (entero)? ¿fecha y hora (cadena)?
- Elija coma flotante para representar la población como grandes agregados (por ejemplo, millones), o enteros para representar la población en unidades de individuos.
- Número en coma flotante, ya que es probable que un promedio tenga una parte fraccionaria.
Tipos de división
En Python 3, el operador // realiza la división de
enteros (números enteros), el operador / realiza la
división de coma flotante, y el operador % (o
modulo) calcula y devuelve el resto de la división de
enteros:
SALIDA
5 // 3: 1
5 / 3: 1.6666666666666667
5 % 3: 2Si num_subjects es el número de sujetos que participan
en un estudio, y num_per_survey es el número que puede
participar en una sola encuesta, escriba una expresión que calcule el
número de encuestas necesarias para llegar a todos una sola vez.
Queremos el número mínimo de encuestas que llega a todos una vez, que
es el valor redondeado de num_subjects/ num_per_survey.
Esto equivale a realizar una división por el suelo con // y
sumarle 1. Antes de la división hay que restar 1 al número de sujetos
para el caso en que num_subjects sea divisible por
num_per_survey.
PYTHON
num_subjects = 600
num_per_survey = 42
num_surveys = (num_subjects - 1) // num_per_survey + 1
print(num_subjects, 'subjects,', num_per_survey, 'per survey:', num_surveys)SALIDA
600 subjects, 42 per survey: 15Cadenas a Números
Cuando sea razonable, float() convertirá una cadena a un
número de coma flotante, y int() convertirá un número de
coma flotante a un entero:
SALIDA
string to float: 3.4
float to int: 3Sin embargo, si la conversión no tiene sentido, aparecerá un mensaje de error.
ERROR
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-5-df3b790bf0a2> in <module>
----> 1 print("string to float:", float("Hello world!"))
ValueError: could not convert string to float: 'Hello world!'Dada esta información, ¿qué esperas que haga el siguiente programa?
¿Qué hace realmente?
¿Por qué crees que hace eso?
¿Qué esperas que haga este programa? No sería tan descabellado
esperar que el comando int de Python 3 convirtiera la
cadena “3.4” a 3.4 y una conversión de tipo adicional a 3. Después de
todo, Python 3 realiza muchas otras magias - ¿no es eso parte de su
encanto?
SALIDA
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-2-ec6729dfccdc> in <module>
----> 1 int("3.4")
ValueError: invalid literal for int() with base 10: '3.4'Sin embargo, Python 3 arroja un error. ¿Por qué? Para ser consistente, posiblemente. Si le pides a Python que realice dos typecasts consecutivos, debes convertirlo explícitamente en código.
SALIDA
3Aritmética con diferentes tipos
¿Cuál de las siguientes opciones devolverá el número de coma flotante
2.0? Nota: puede haber más de una respuesta correcta.
first + float(second)float(second) + float(third)first + int(third)first + int(float(third))int(first) + int(float(third))2.0 * second
Respuesta: 1 y 4
Números Complejos
Python proporciona números complejos, que se escriben como
1.0+2.0j. Si val es un número complejo, se
puede acceder a sus partes real e imaginaria usando notación de
puntos como val.real y val.imag.
SALIDA
6.0
2.0- ¿Por qué crees que Python utiliza
jen lugar deipara la parte imaginaria? - ¿Qué esperas que produzca
1 + 2j + 3? - ¿Qué esperas que sea
4j? ¿Y4 jo4 + j?
- Los tratamientos matemáticos estándar suelen utilizar
ipara denotar un número imaginario. Sin embargo, según los informes de los medios de comunicación, se trata de una antigua convención establecida a partir de la ingeniería eléctrica que ahora presenta un área técnicamente costosa de cambiar. Stack Overflow proporciona explicaciones y discusiones adicionales (4+2j)-
4jySyntax Error: invalid syntax. En estos últimos casos,jse considera una variable y la sentencia depende de sijestá definida y, en caso afirmativo, de su valor asignado.
- Cada valor tiene un tipo.
- Utilice la función incorporada
typepara encontrar el tipo de un valor. - Los tipos controlan las operaciones que se pueden realizar con los valores.
- Las cadenas pueden sumarse y multiplicarse.
- Las cadenas tienen longitud (pero los números no).
- Debe convertir números en cadenas o viceversa cuando opera con ellos.
- Puede mezclar enteros y flotantes libremente en las operaciones.
- Las variables sólo cambian de valor cuando se les asigna algo.
Content from Funciones incorporadas y ayuda
Última actualización: 2025-07-01 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo utilizar las funciones incorporadas?
- ¿Cómo puedo averiguar lo que hacen?
- ¿Qué tipo de errores pueden ocurrir en los programas?
Objetivos
- Explica el propósito de las funciones.
- Llama correctamente a las funciones incorporadas de Python.
- Anida correctamente las llamadas a funciones incorporadas.
- Utilice la ayuda para mostrar la documentación de las funciones incorporadas.
- Describir correctamente las situaciones en las que se producen SyntaxError y NameError.
Usa comentarios para añadir documentación a los programas.
Una función puede tomar cero o más argumentos.
- Ya hemos visto algunas funciones — ahora echemos un vistazo más de cerca.
- Un argumento es un valor que se pasa a una función.
-
lentoma exactamente uno. -
int,str, yfloatcrean un nuevo valor a partir de uno existente. -
printtoma cero o más. -
printsin argumentos imprime una línea en blanco.- Siempre se deben usar paréntesis, incluso si están vacíos, para que Python sepa que se está llamando a una función.
SALIDA
before
afterCada función devuelve algo.
- Cada llamada a una función produce algún resultado.
- Si la función no tiene un resultado útil que devolver, normalmente
devuelve el valor especial
None.Nonees un objeto de Python que se sustituye cuando no hay ningún valor.
SALIDA
example
result of print is NoneLas funciones incorporadas más utilizadas son max,
min, y round.
- Utilice
maxpara encontrar el mayor valor de uno o más valores. - Usa
minpara encontrar el más pequeño. - Ambos funcionan tanto con cadenas de caracteres como con números.
- “Mayor” y “menor” utilizan (0-9, A-Z, a-z) para comparar letras.
SALIDA
3
0Puede que las funciones sólo funcionen para ciertos (combinaciones de) argumentos.
-
maxymindeben tener al menos un argumento.- “Mayor del conjunto vacío” es una pregunta sin sentido.
- Y se les debe dar cosas que puedan ser comparadas significativamente.
ERROR
TypeError Traceback (most recent call last)
<ipython-input-52-3f049acf3762> in <module>
----> 1 print(max(1, 'a'))
TypeError: '>' not supported between instances of 'str' and 'int'Las funciones pueden tener valores por defecto para algunos argumentos.
-
roundredondeará un número de coma flotante. - Por defecto, redondea a cero decimales.
SALIDA
4- Podemos especificar el número de decimales que queremos.
SALIDA
3.7Las funciones adjuntas a objetos se llaman métodos
- Las funciones toman otra forma que será común en los episodios de pandas.
- Los métodos tienen paréntesis como las funciones, pero van después de la variable.
- Algunos métodos se utilizan para operaciones internas de Python, y están marcados con doble subrayado.
PYTHON
my_string = 'Hello world!' # creación de un string
print(len(my_string)) # la función len toma un string y devuelve la longitud del string
print(my_string.swapcase()) # llamada al método swapcase de mi objeto my_string
print(my_string.__len__()) # llamando al método interno __len__ en el objeto my_string, usado por len(my_string)SALIDA
12
hELLO WORLD!
12- Incluso puede verlos encadenados. Funcionan de izquierda a derecha.
PYTHON
print(my_string.isupper()) # no todas las letras son mayúsculas
print(my_string.upper()) # esto lo convierte todo a mayúsculas
print(my_string.upper().isupper()) # ahora son todo mayúsculasSALIDA
False
HELLO WORLD
TrueUse la función incorporada help para obtener ayuda de
una función.
- Cada función incorporada tiene documentación en línea.
SALIDA
Help on built-in function round in module builtins:
round(number, ndigits=None)
Round a number to a given precision in decimal digits.
The return value is an integer if ndigits is omitted or None. Otherwise
the return value has the same type as the number. ndigits may be negative.El Jupyter Notebook tiene dos formas de obtener ayuda.
- Opción 1: Coloque el cursor cerca del lugar donde se invoca la
función en una celda (es decir, el nombre de la función o sus
parámetros),
- Mantén pulsado Shift y pulsa Tab.
- Haga esto varias veces para ampliar la información devuelta.
- Opción 2: Escribe el nombre de la función en una celda con un signo de interrogación detrás. A continuación, ejecute la celda.
Python informa de un error de sintaxis cuando no puede entender el código fuente de un programa.
- Ni siquiera intentará ejecutar el programa si no puede ser analizado.
ERROR
File "<ipython-input-56-f42768451d55>", line 2
name = 'Feng
^
SyntaxError: EOL while scanning string literalERROR
File "<ipython-input-57-ccc3df3cf902>", line 2
age = = 52
^
SyntaxError: invalid syntax- Fíjate mejor en el mensaje de error:
ERROR
File "<ipython-input-6-d1cc229bf815>", line 1
print ("hello world"
^
SyntaxError: unexpected EOF while parsing- El mensaje indica un problema en la primera línea de la entrada
(“línea 1”).
- En este caso la sección “ipython-input” del nombre del archivo nos indica que estamos trabajando con entrada en IPython, el intérprete de Python utilizado por el Jupyter Notebook.
- La parte
-6-del nombre del archivo indica que el error se produjo en la celda 6 de nuestro Cuaderno. - A continuación se muestra la línea de código problemática, indicando
el problema con un puntero
^.
Python informa de un error de ejecución cuando algo va mal mientras se ejecuta un programa. {#error en tiempo de ejecución}
ERROR
NameError Traceback (most recent call last)
<ipython-input-59-1214fb6c55fc> in <module>
1 age = 53
----> 2 remaining = 100 - aege # mis-spelled 'age'
NameError: name 'aege' is not defined- Corrige los errores de sintaxis leyendo el código fuente y los errores de ejecución rastreando la ejecución del programa.
Qué ocurre cuando
- Orden de las operaciones:
1.1 * radiance = 1.11.1 - 0.5 = 0.6min(radiance, 0.6) = 0.62.0 + 0.6 = 2.6max(2.1, 2.6) = 2.6- Al final,
radiance = 2.6
Encuentra la Diferencia
- Predice lo que imprimirá cada una de las sentencias
printdel siguiente programa. - ¿Se ejecuta
max(len(rich), poor)o produce un mensaje de error? Si se ejecuta, ¿tiene algún sentido su resultado?
SALIDA
cSALIDA
tinSALIDA
4max(len(rich), poor) lanza un TypeError. Esto se
convierte en max(4, 'tin') y como discutimos anteriormente
una cadena y un entero no pueden ser comparados significativamente.
ERROR
TypeError Traceback (most recent call last)
<ipython-input-65-bc82ad05177a> in <module>
----> 1 max(len(rich), poor)
TypeError: '>' not supported between instances of 'str' and 'int'¿Por qué no?
¿Por qué max y min no devuelven
None cuando se llaman sin argumentos?
max y min devuelven TypeErrors en este caso
porque no se suministró el número correcto de parámetros. Si sólo
devolviera None, el error sería mucho más difícil de
rastrear, ya que probablemente se almacenaría en una variable y se
utilizaría más adelante en el programa, sólo para lanzar probablemente
un error en tiempo de ejecución.
Último carácter de una cadena
Si Python empieza a contar desde cero, y len devuelve el
número de caracteres de una cadena, ¿qué expresión índice obtendrá el
último carácter de la cadena name? (Nota: veremos una forma
más sencilla de hacer esto en un episodio posterior)
name[len(name) - 1]
¡Explora la documentación de Python!
La documentación oficial de Python es posiblemente la fuente de información más completa sobre el lenguaje. Está disponible en diferentes idiomas y contiene muchos recursos útiles. La página de funciones incorporadas contiene un catálogo de todas estas funciones, incluyendo las que hemos cubierto en esta lección. Algunas de ellas son más avanzadas e innecesarias por el momento, pero otras son muy sencillas y útiles.
- Utiliza comentarios para añadir documentación a los programas.
- Una función puede tomar cero o más argumentos.
- Las funciones incorporadas más utilizadas son
max,minyround. - Puede que las funciones sólo funcionen para ciertos (combinaciones de) argumentos.
- Las funciones pueden tener valores por defecto para algunos argumentos.
- Utilice la función incorporada
helppara obtener ayuda sobre una función. - El Jupyter Notebook tiene dos formas de obtener ayuda.
- Toda función devuelve algo.
- Python informa de un error de sintaxis cuando no puede entender el código fuente de un programa.
- Python informa de un error de ejecución cuando algo va mal mientras se ejecuta un programa.
- Corrige los errores de sintaxis leyendo el código fuente, y los errores de ejecución rastreando la ejecución del programa.
Content from Café de la mañana
Última actualización: 2025-02-28 | Mejora esta página
Ejercicio de reflexión
Durante el café, reflexiona y discute sobre lo siguiente:
- ¿Cuáles son los diferentes tipos de errores que informará Python?
- ¿El código siempre produjo los resultados esperados? En caso negativo, ¿por qué?
- ¿Hay algo que podamos hacer para evitar errores cuando escribimos código?
Content from Librerías
Última actualización: 2025-07-01 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo utilizar software que ha escrito otra gente?
- ¿Cómo puedo averiguar qué hace ese programa?
Objetivos
- Explicar qué son las librerías de software y por qué los programadores las crean y utilizan.
- Escribir programas que importen y utilicen módulos de la librería estándar de Python.
- Buscar y leer documentación de la librería estándar de forma interactiva (en el intérprete) y en línea.
La mayor parte de la potencia de un lenguaje de programación está en sus librerías.
- Una librería es una colección de ficheros (llamados
módulos) que contienen funciones para ser usadas por otros
programas.
- También puede contener valores de datos (por ejemplo, constantes numéricas) y otras cosas.
- Se supone que los contenidos de la librería están relacionados, pero no hay forma de hacer cumplir esto.
- La librería estándar de Python es un extenso conjunto de módulos que vienen con el propio Python.
- Muchas librerías adicionales están disponibles en PyPI (the Python Package Index).
- Veremos más adelante cómo escribir nuevas librerías.
librerías y módulos
Una librería es una colección de módulos, pero a menudo los términos se usan indistintamente, especialmente porque muchas librerías sólo consisten en un único módulo, así que no te preocupes si los mezclas.
Un programa debe importar un módulo de librería antes de usarlo.
- Utilice
importpara cargar un módulo de librería en la memoria de un programa. - Luego refiérase a cosas del módulo como
module_name.thing_name.- Python usa
.para significar “parte de”.
- Python usa
- Usando
math, uno de los módulos de la librería estándar:
SALIDA
pi is 3.141592653589793
cos(pi) is -1.0- Tienes que referirte a cada elemento con el nombre del módulo.
-
math.cos(pi)no funciona: la referencia apino “hereda” de algún modo la referencia de la función amath.
-
Utilice help para conocer el contenido de un módulo de
librería.
- Funciona igual que la ayuda para una función.
SALIDA
Help on module math:
NAME
math
MODULE REFERENCE
http://docs.python.org/3/library/math
The following documentation is automatically generated from the Python
source files. It may be incomplete, incorrect or include features that
are considered implementation detail and may vary between Python
implementations. When in doubt, consult the module reference at the
location listed above.
DESCRIPTION
This module is always available. It provides access to the
mathematical functions defined by the C standard.
FUNCTIONS
acos(x, /)
Return the arc cosine (measured in radians) of x.
⋮ ⋮ ⋮Importar elementos específicos de un módulo de librería para acortar programas.
- Utilice
from ... import ...para cargar sólo elementos específicos de un módulo de librería. - Luego refiérase a ellos directamente sin el nombre de la librería como prefijo.
SALIDA
cos(pi) is -1.0Crear un alias para un módulo de librería al importarlo para acortar programas.
- Utilice
import ... as ...para dar un alias corto a una librería al importarla. - A continuación, haga referencia a los elementos de la librería utilizando ese nombre abreviado.
SALIDA
cos(pi) is -1.0- Comúnmente utilizado para librerías de uso frecuente o con nombres
largos.
- Por ejemplo, la librería de ploteo
matplotliba menudo tiene el aliasmpl.
- Por ejemplo, la librería de ploteo
- Pero puede hacer que los programas sean más difíciles de entender, ya que los lectores deben aprender los alias de su programa.
Explorando el Módulo de Matemáticas
- ¿Qué función del módulo
mathpuedes usar para calcular una raíz cuadrada sin usarsqrt? - Dado que la librería contiene esta función, ¿por qué existe
sqrt?
Usando
help(math)vemos que tenemospow(x,y)además desqrt(x), así que podríamos usarpow(x, 0.5)para encontrar una raíz cuadrada.La función
sqrt(x)es posiblemente más legible quepow(x, 0.5)cuando se implementan ecuaciones. La legibilidad es una piedra angular de la buena programación, por lo que tiene sentido proporcionar una función especial para este caso común específico.
Además, el diseño de la librería math de Python tiene su
origen en el estándar C, que incluye tanto sqrt(x) como
pow(x,y), por lo que un poco de la historia de la
programación se muestra en los nombres de las funciones de Python.
Localizando el Módulo Correcto
Desea seleccionar un carácter aleatorio de una cadena:
- ¿Qué módulo de librería estándar podría ayudarle?
- ¿Qué función seleccionarías de ese módulo? ¿Existen alternativas?
- Intenta escribir un programa que utilice la función.
El módulo aleatorio parece que podría ayudar.
La cadena tiene 11 caracteres, cada uno con un índice posicional de 0
a 10. Podría utilizar las funciones random.randrange
o random.randint
para obtener un número entero aleatorio entre 0 y 10, y luego
seleccionar el carácter bases en ese índice:
o de forma más compacta:
¿Quizás haya encontrado la función random.sample?
Permite escribir un poco menos, pero puede ser un poco más difícil de
entender con sólo leerla:
Tenga en cuenta que esta función devuelve una lista de valores. Aprenderemos sobre listas en el episodio 11.
La solución más simple y corta es la función random.choice
que hace exactamente lo que queremos:
Ejemplo de Programación de Rompecabezas (Problema de Parson)
Reorganice las siguientes sentencias para que se imprima una base de ADN aleatoria y su índice en la cadena. Puede que no se necesiten todas las sentencias. Siéntete libre de usar/añadir variables intermedias.
¿Cuándo está disponible la ayuda?
Cuando un colega tuyo teclea help(math), Python informa
de un error:
ERROR
NameError: name 'math' is not defined¿Qué se le ha olvidado hacer a tu colega?
Importación del módulo math (import math)
puede escribirse como
Como acabas de escribir el código y estás familiarizado con él, puede que encuentres la primera versión más fácil de leer. Pero cuando se trata de leer un enorme trozo de código escrito por otra persona, o cuando se vuelve al propio trozo enorme de código después de varios meses, los nombres no abreviados suelen ser más fáciles, excepto cuando hay convenciones claras de abreviación.
¡Hay Muchas Formas De Importar Librerías!
Empareja las siguientes sentencias de impresión con las llamadas a librería apropiadas.
Comandos de impresión:
print("sin(pi/2) =", sin(pi/2))print("sin(pi/2) =", m.sin(m.pi/2))print("sin(pi/2) =", math.sin(math.pi/2))
Llamadas a librerías:
from math import sin, piimport mathimport math as mfrom math import *
- Llamadas a las librerías 1 y 4. Para referirse directamente a
sinypisin el nombre de la librería como prefijo, es necesario utilizar la sentenciafrom ... import .... Mientras que la llamada a librería 1 importa específicamente las dos funcionessinypi, la llamada a librería 4 importa todas las funciones del módulomath. - Llamada a la librería 3. Aquí se hace referencia a
sinypicon un nombre de librería abreviadomen lugar demath. La llamada a librería 3 hace exactamente eso utilizando la sintaxisimport ... as ...- crea un alias paramathcon el nombre abreviadom. - Llamada a la librería 2. Aquí se hace referencia a
sinypicon el nombre de librería normalmath, por lo que basta con la llamada normalimport ....
Nota: aunque la llamada a librería 4 funciona,
importar todos los nombres de un módulo usando una importación comodín
no es recomendable ya que hace
que no quede claro qué nombres del módulo se usan en el código. En
general, es mejor hacer las importaciones tan específicas como sea
posible y sólo importar lo que el código utiliza. En la llamada a
librería 1, la sentencia import nos dice explícitamente que
la función sin es importada del módulo math,
pero la llamada a librería 4 no transmite esta información.
Importar elementos específicos
Lo más probable es que encuentres esta versión más fácil de leer ya
que es menos densa. La principal razón para no utilizar esta forma de
importación es evitar conflictos de nombres. Por ejemplo, no importaría
degrees de esta forma si también quisiera usar el nombre
degrees para una variable o función propia. O si también
importaras una función llamada degrees de otra
librería.
SALIDA
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-1-d72e1d780bab> in <module>
1 from math import log
----> 2 log(0)
ValueError: math domain error- El logaritmo de
xsólo está definido parax > 0, por lo que 0 queda fuera del dominio de la función. - Aparece un error de tipo
ValueError, indicando que la función recibió un valor de argumento inapropiado. El mensaje adicional “error de dominio matemático” aclara cuál es el problema.
- La mayor parte de la potencia de un lenguaje de programación está en sus librerías.
- Un programa debe importar un módulo de librería para poder utilizarlo.
- Utilice
helppara conocer el contenido de un módulo de librería. - Importa elementos específicos de una librería para acortar programas.
- Crea un alias para una librería al importarla para acortar programas.
Content from Lectura de datos tabulares en DataFrames
Última actualización: 2025-03-01 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo leer datos tabulares?
Objetivos
- Importa la biblioteca Pandas.
- Utiliza Pandas para cargar un simple conjunto de datos CSV.
- Obtiene información básica sobre un Pandas DataFrame.
Utiliza la librería Pandas para realizar estadísticas sobre datos tabulares.
- Pandas es una biblioteca de Python ampliamente utilizada para estadísticas, en particular sobre datos tabulares.
- Toma prestadas muchas características de los marcos de datos de R.
- Una tabla bidimensional cuyas columnas tienen nombres y potencialmente tienen diferentes tipos de datos.
- Cargar Pandas con
import pandas as pd. El aliaspdse utiliza comúnmente para referirse a la biblioteca Pandas en código. - Leer un fichero de datos de valores separados por comas (CSV) con
pd.read_csv.- Argumento es el nombre del fichero a leer.
- Devuelve un marco de datos que se puede asignar a una variable
PYTHON
import pandas as pd
data_oceania = pd.read_csv('data/gapminder_gdp_oceania.csv')
print(data_oceania)SALIDA
country gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 \
0 Australia 10039.59564 10949.64959 12217.22686
1 New Zealand 10556.57566 12247.39532 13175.67800
gdpPercap_1967 gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 \
0 14526.12465 16788.62948 18334.19751 19477.00928
1 14463.91893 16046.03728 16233.71770 17632.41040
gdpPercap_1987 gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 \
0 21888.88903 23424.76683 26997.93657 30687.75473
1 19007.19129 18363.32494 21050.41377 23189.80135
gdpPercap_2007
0 34435.36744
1 25185.00911- Las columnas de un marco de datos son las variables observadas y las filas son las observaciones.
- Pandas utiliza la barra invertida
\para mostrar las líneas envueltas cuando la salida es demasiado ancha para caber en la pantalla. - El uso de nombres descriptivos para los marcos de datos nos ayuda a distinguir entre varios marcos de datos para que no sobrescribamos accidentalmente un marco de datos o leamos de uno equivocado.
Archivo no encontrado
Nuestras lecciones almacenan sus ficheros de datos en un
subdirectorio data, por lo que la ruta al fichero es
data/gapminder_gdp_oceania.csv. Si olvida incluir
data/, o si lo incluye pero su copia del fichero está en
otro lugar, obtendrá un error de
ejecución que termina con una línea como esta:
ERROR
FileNotFoundError: [Errno 2] No such file or directory: 'data/gapminder_gdp_oceania.csv'Utilice index_col para especificar que los valores de
una columna deben utilizarse como encabezamientos de fila.
- Los títulos de las filas son números (0 y 1 en este caso).
- Realmente quiero indexar por país.
- Para ello, pase el nombre de la columna a
read_csvcomo parámetroindex_col. - Al nombrar el marco de datos
data_oceania_countrynos indica qué región incluyen los datos (oceania) y cómo están indexados (country).
PYTHON
data_oceania_country = pd.read_csv('data/gapminder_gdp_oceania.csv', index_col='country')
print(data_oceania_country)SALIDA
gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 gdpPercap_1967 \
country
Australia 10039.59564 10949.64959 12217.22686 14526.12465
New Zealand 10556.57566 12247.39532 13175.67800 14463.91893
gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 gdpPercap_1987 \
country
Australia 16788.62948 18334.19751 19477.00928 21888.88903
New Zealand 16046.03728 16233.71770 17632.41040 19007.19129
gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 gdpPercap_2007
country
Australia 23424.76683 26997.93657 30687.75473 34435.36744
New Zealand 18363.32494 21050.41377 23189.80135 25185.00911Utilice el método DataFrame.info() para obtener más
información sobre un marco de datos.
SALIDA
<class 'pandas.core.frame.DataFrame'>
Index: 2 entries, Australia to New Zealand
Data columns (total 12 columns):
gdpPercap_1952 2 non-null float64
gdpPercap_1957 2 non-null float64
gdpPercap_1962 2 non-null float64
gdpPercap_1967 2 non-null float64
gdpPercap_1972 2 non-null float64
gdpPercap_1977 2 non-null float64
gdpPercap_1982 2 non-null float64
gdpPercap_1987 2 non-null float64
gdpPercap_1992 2 non-null float64
gdpPercap_1997 2 non-null float64
gdpPercap_2002 2 non-null float64
gdpPercap_2007 2 non-null float64
dtypes: float64(12)
memory usage: 208.0+ bytes- Se trata de un
DataFrame - Dos filas llamadas
'Australia'y'New Zealand' - Doce columnas, cada una de las cuales tiene dos valores reales en
coma flotante de 64 bits.
- Más adelante hablaremos de los valores nulos, que se utilizan para representar las observaciones que faltan.
- Utiliza 208 bytes de memoria.
La variable DataFrame.columns almacena información
sobre las columnas del marco de datos.
- Nótese que se trata de datos, no de un método. (No tiene
paréntesis)
- Como
math.pi. - Así que no use
()para intentar llamarlo.
- Como
- Llamada variable miembro, o simplemente miembro.
SALIDA
Index(['gdpPercap_1952', 'gdpPercap_1957', 'gdpPercap_1962', 'gdpPercap_1967',
'gdpPercap_1972', 'gdpPercap_1977', 'gdpPercap_1982', 'gdpPercap_1987',
'gdpPercap_1992', 'gdpPercap_1997', 'gdpPercap_2002', 'gdpPercap_2007'],
dtype='object')Utilice DataFrame.T para transponer un marco de
datos.
- A veces se desea tratar las columnas como filas y viceversa.
- Transponer (escrito
.T) no copia los datos, sólo cambia la visión que el programa tiene de ellos. - Al igual que
columns, es una variable miembro.
SALIDA
country Australia New Zealand
gdpPercap_1952 10039.59564 10556.57566
gdpPercap_1957 10949.64959 12247.39532
gdpPercap_1962 12217.22686 13175.67800
gdpPercap_1967 14526.12465 14463.91893
gdpPercap_1972 16788.62948 16046.03728
gdpPercap_1977 18334.19751 16233.71770
gdpPercap_1982 19477.00928 17632.41040
gdpPercap_1987 21888.88903 19007.19129
gdpPercap_1992 23424.76683 18363.32494
gdpPercap_1997 26997.93657 21050.41377
gdpPercap_2002 30687.75473 23189.80135
gdpPercap_2007 34435.36744 25185.00911Utilice DataFrame.describe() para obtener estadísticas
resumidas sobre los datos.
DataFrame.describe() obtiene las estadísticas de resumen
sólo de las columnas que tienen datos numéricos. Todas las demás
columnas se ignoran, a menos que se utilice el argumento
include='all'.
SALIDA
gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 gdpPercap_1967 \
count 2.000000 2.000000 2.000000 2.000000
mean 10298.085650 11598.522455 12696.452430 14495.021790
std 365.560078 917.644806 677.727301 43.986086
min 10039.595640 10949.649590 12217.226860 14463.918930
25% 10168.840645 11274.086022 12456.839645 14479.470360
50% 10298.085650 11598.522455 12696.452430 14495.021790
75% 10427.330655 11922.958888 12936.065215 14510.573220
max 10556.575660 12247.395320 13175.678000 14526.124650
gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 gdpPercap_1987 \
count 2.00000 2.000000 2.000000 2.000000
mean 16417.33338 17283.957605 18554.709840 20448.040160
std 525.09198 1485.263517 1304.328377 2037.668013
min 16046.03728 16233.717700 17632.410400 19007.191290
25% 16231.68533 16758.837652 18093.560120 19727.615725
50% 16417.33338 17283.957605 18554.709840 20448.040160
75% 16602.98143 17809.077557 19015.859560 21168.464595
max 16788.62948 18334.197510 19477.009280 21888.889030
gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 gdpPercap_2007
count 2.000000 2.000000 2.000000 2.000000
mean 20894.045885 24024.175170 26938.778040 29810.188275
std 3578.979883 4205.533703 5301.853680 6540.991104
min 18363.324940 21050.413770 23189.801350 25185.009110
25% 19628.685413 22537.294470 25064.289695 27497.598692
50% 20894.045885 24024.175170 26938.778040 29810.188275
75% 22159.406358 25511.055870 28813.266385 32122.777857
max 23424.766830 26997.936570 30687.754730 34435.367440- No es especialmente útil con sólo dos registros, pero sí cuando hay miles.
Lectura de otros datos
Leer los datos de gapminder_gdp_americas.csv (que deben
estar en el mismo directorio que gapminder_gdp_oceania.csv)
en una variable llamada data_americas y mostrar sus
estadísticas de resumen.
Para leer un CSV, utilizamos pd.read_csv y le pasamos el
nombre de fichero 'data/gapminder_gdp_americas.csv'.
También volvemos a pasar el nombre de columna 'country' al
parámetro index_col para indexar por países. Las
estadísticas resumidas pueden visualizarse con el método
DataFrame.describe().
Inspección de datos
Después de leer los datos de América, utiliza
help(data_americas.head) y
help(data_americas.tail) para averiguar qué hacen
DataFrame.head y DataFrame.tail.
- ¿Qué llamada al método mostrará las tres primeras filas de estos datos?
- ¿Qué método mostrará las tres últimas columnas de estos datos? (Sugerencia: es posible que tengas que cambiar la vista de los datos)
- Podemos ver las cinco primeras filas de
data_americasejecutandodata_americas.head()que nos permite ver el principio del DataFrame. Podemos especificar el número de filas que deseamos ver especificando el parámetronen nuestra llamada adata_americas.head(). Para ver las tres primeras filas, ejecute:
SALIDA
continent gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 \
country
Argentina Americas 5911.315053 6856.856212 7133.166023
Bolivia Americas 2677.326347 2127.686326 2180.972546
Brazil Americas 2108.944355 2487.365989 3336.585802
gdpPercap_1967 gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 \
country
Argentina 8052.953021 9443.038526 10079.026740 8997.897412
Bolivia 2586.886053 2980.331339 3548.097832 3156.510452
Brazil 3429.864357 4985.711467 6660.118654 7030.835878
gdpPercap_1987 gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 \
country
Argentina 9139.671389 9308.418710 10967.281950 8797.640716
Bolivia 2753.691490 2961.699694 3326.143191 3413.262690
Brazil 7807.095818 6950.283021 7957.980824 8131.212843
gdpPercap_2007
country
Argentina 12779.379640
Bolivia 3822.137084
Brazil 9065.800825- Para consultar las tres últimas filas de
data_americas, utilizaríamos el comando,americas.tail(n=3), análogo ahead()utilizado anteriormente. Sin embargo, aquí queremos ver las tres últimas columnas, así que tenemos que cambiar la vista y utilizartail(). Para ello, creamos un nuevo DataFrame en el que se intercambian filas y columnas:
Podemos ver las tres últimas columnas de americas viendo
las tres últimas filas de americas_flipped:
SALIDA
country Argentina Bolivia Brazil Canada Chile Colombia \
gdpPercap_1997 10967.3 3326.14 7957.98 28954.9 10118.1 6117.36
gdpPercap_2002 8797.64 3413.26 8131.21 33329 10778.8 5755.26
gdpPercap_2007 12779.4 3822.14 9065.8 36319.2 13171.6 7006.58
country Costa Rica Cuba Dominican Republic Ecuador ... \
gdpPercap_1997 6677.05 5431.99 3614.1 7429.46 ...
gdpPercap_2002 7723.45 6340.65 4563.81 5773.04 ...
gdpPercap_2007 9645.06 8948.1 6025.37 6873.26 ...
country Mexico Nicaragua Panama Paraguay Peru Puerto Rico \
gdpPercap_1997 9767.3 2253.02 7113.69 4247.4 5838.35 16999.4
gdpPercap_2002 10742.4 2474.55 7356.03 3783.67 5909.02 18855.6
gdpPercap_2007 11977.6 2749.32 9809.19 4172.84 7408.91 19328.7
country Trinidad and Tobago United States Uruguay Venezuela
gdpPercap_1997 8792.57 35767.4 9230.24 10165.5
gdpPercap_2002 11460.6 39097.1 7727 8605.05
gdpPercap_2007 18008.5 42951.7 10611.5 11415.8Muestra los datos que deseamos, pero es posible que prefiramos mostrar tres columnas en lugar de tres filas, por lo que podemos darle la vuelta:
Nota: podríamos haber hecho lo anterior en una sola línea de código “encadenando” los comandos:
Lectura de ficheros en otros directorios
Los datos de su proyecto actual están almacenados en un archivo
llamado microbes.csv, que se encuentra en una carpeta
llamada field_data. Usted está haciendo el análisis en un
cuaderno llamado analysis.ipynb en una carpeta hermana
llamada thesis:
SALIDA
your_home_directory
+-- field_data/
| +-- microbes.csv
+-- thesis/
+-- analysis.ipynb¿Qué valor(es) debe pasar a read_csv para leer
microbes.csv en analysis.ipynb?
Necesitamos especificar la ruta al fichero de interés en la llamada a
pd.read_csv. Primero tenemos que “saltar” fuera de la
carpeta thesis utilizando ‘../’ y luego a la carpeta
field_data utilizando data_campo/. A
continuación, podemos especificar el nombre de archivo
microbes.csv. El resultado es el siguiente:
Datos de escritura
Además de la función read_csv para leer datos de un
fichero, Pandas proporciona una función to_csv para
escribir dataframes en ficheros. Aplicando lo que has aprendido sobre la
lectura de archivos, escribe uno de tus dataframes en un archivo llamado
processed.csv. Puedes utilizar help para
obtener información sobre cómo utilizar to_csv.
Para escribir el DataFrame data_americas en un fichero
llamado processed.csv, ejecute el siguiente comando:
Para obtener ayuda sobre read_csv o to_csv,
puede ejecutar, por ejemplo:
Observe que help(to_csv) o help(pd.to_csv)
dan error Esto se debe a que to_csv no es una función
global de Pandas, sino una función miembro de DataFrames. Esto significa
que sólo se puede llamar en una instancia de un DataFrame, por ejemplo,
data_americas.to_csv o data_oceania.to_csv
- Utiliza la librería Pandas para obtener estadísticas básicas a partir de datos tabulares.
- Utilice
index_colpara especificar que los valores de una columna deben utilizarse como encabezamientos de fila. - Utilice
DataFrame.infopara obtener más información sobre un marco de datos. - La variable
DataFrame.columnsalmacena información sobre las columnas del marco de datos. - Utilice
DataFrame.Tpara transponer un marco de datos. - Utilice
DataFrame.describepara obtener estadísticas resumidas sobre los datos.
Content from Pandas DataFrames
Última actualización: 2025-07-01 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo hacer un análisis estadístico de datos tabulares?
Objetivos
- Selecciona valores individuales de un marco de datos Pandas.
- Selecciona filas enteras o columnas enteras de un marco de datos.
- Selecciona un subconjunto de filas y columnas de un marco de datos en una sola operación.
- Seleccionar un subconjunto de un marco de datos mediante un único criterio booleano.
Nota sobre Pandas DataFrames/Series
Un DataFrame es una colección de Series; El DataFrame es la forma en que Pandas representa una tabla, y Series es la estructura de datos que Pandas utiliza para representar una columna.
Pandas está construido sobre la librería Numpy, lo que en la práctica significa que la mayoría de los métodos definidos para Numpy Arrays se aplican a Pandas Series/DataFrames.
Lo que hace que Pandas sea tan atractivo es la potente interfaz para acceder a registros individuales de la tabla, el manejo adecuado de los valores que faltan y las operaciones de base de datos relacional entre DataFrames.
Seleccionar valores
Para acceder a un valor en la posición [i,j] de un
DataFrame, tenemos dos opciones, dependiendo de cuál sea el significado
de i en uso. Recuerde que un DataFrame proporciona un
índice como forma de identificar las filas de la tabla; una
fila, entonces, tiene una posición dentro de la tabla así como
una etiqueta, que identifica unívocamente su entrada
en el DataFrame.
Usar DataFrame.iloc[..., ...] para seleccionar valores
por su posición (de entrada)
- Puede especificar la ubicación por índice numérico de forma análoga a la versión 2D de la selección de caracteres en cadenas.
PYTHON
import pandas as pd
data = pd.read_csv('data/gapminder_gdp_europe.csv', index_col='country')
print(data.iloc[0, 0])SALIDA
1601.056136Usa DataFrame.loc[..., ...] para seleccionar valores
por su etiqueta (de entrada).
- Puede especificar la ubicación por nombre de fila y/o columna.
SALIDA
1601.056136Use : solo para significar todas las columnas o todas
las filas.
- Igual que la notación de corte habitual de Python.
SALIDA
gdpPercap_1952 1601.056136
gdpPercap_1957 1942.284244
gdpPercap_1962 2312.888958
gdpPercap_1967 2760.196931
gdpPercap_1972 3313.422188
gdpPercap_1977 3533.003910
gdpPercap_1982 3630.880722
gdpPercap_1987 3738.932735
gdpPercap_1992 2497.437901
gdpPercap_1997 3193.054604
gdpPercap_2002 4604.211737
gdpPercap_2007 5937.029526
Name: Albania, dtype: float64- Obtendría el mismo resultado imprimiendo
data.loc["Albania"](sin un segundo índice).
SALIDA
country
Albania 1601.056136
Austria 6137.076492
Belgium 8343.105127
⋮ ⋮ ⋮
Switzerland 14734.232750
Turkey 1969.100980
United Kingdom 9979.508487
Name: gdpPercap_1952, dtype: float64- Obtendría el mismo resultado imprimiendo
data["gdpPercap_1952"] - También se obtiene el mismo resultado imprimiendo
data.gdpPercap_1952(no recomendado, porque se confunde fácilmente con la notación.para métodos)
Selecciona múltiples columnas o filas usando
DataFrame.loc y un slice con nombre.
SALIDA
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy 8243.582340 10022.401310 12269.273780
Montenegro 4649.593785 5907.850937 7778.414017
Netherlands 12790.849560 15363.251360 18794.745670
Norway 13450.401510 16361.876470 18965.055510
Poland 5338.752143 6557.152776 8006.506993En el código anterior, descubrimos que el troceado utilizando
loc es inclusivo en ambos extremos, lo que difiere
del troceado utilizando iloc, donde el
troceado indica todo hasta el índice final, pero sin incluirlo.
El resultado del corte puede utilizarse en operaciones posteriores.
- Normalmente no se imprime sólo un trozo.
- Todos los operadores estadísticos que funcionan en marcos de datos enteros funcionan de la misma manera en cortes.
- Por ejemplo, calcular el máximo de una porción.
SALIDA
gdpPercap_1962 13450.40151
gdpPercap_1967 16361.87647
gdpPercap_1972 18965.05551
dtype: float64SALIDA
gdpPercap_1962 4649.593785
gdpPercap_1967 5907.850937
gdpPercap_1972 7778.414017
dtype: float64Utiliza comparaciones para seleccionar datos en función de su valor.
- La comparación se aplica elemento por elemento.
- Devuelve un marco de datos de forma similar de
TrueyFalse.
PYTHON
# Use a subset of data to keep output readable.
subset = data.loc['Italy':'Poland', 'gdpPercap_1962':'gdpPercap_1972']
print('Subset of data:\n', subset)
# Which values were greater than 10000 ?
print('\nWhere are values large?\n', subset > 10000)SALIDA
Subset of data:
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy 8243.582340 10022.401310 12269.273780
Montenegro 4649.593785 5907.850937 7778.414017
Netherlands 12790.849560 15363.251360 18794.745670
Norway 13450.401510 16361.876470 18965.055510
Poland 5338.752143 6557.152776 8006.506993
Where are values large?
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy False True True
Montenegro False False False
Netherlands True True True
Norway True True True
Poland False False FalseSeleccionar valores o NaN usando una máscara booleana.
- Un marco lleno de booleanos a veces se llama máscara por cómo se puede usar.
SALIDA
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
country
Italy NaN 10022.40131 12269.27378
Montenegro NaN NaN NaN
Netherlands 12790.84956 15363.25136 18794.74567
Norway 13450.40151 16361.87647 18965.05551
Poland NaN NaN NaN- Obtiene el valor donde la máscara es verdadera, y NaN (Not a Number) donde es falsa.
- Útil porque los NaNs son ignorados por operaciones como max, min, promedio, etc.
SALIDA
gdpPercap_1962 gdpPercap_1967 gdpPercap_1972
count 2.000000 3.000000 3.000000
mean 13120.625535 13915.843047 16676.358320
std 466.373656 3408.589070 3817.597015
min 12790.849560 10022.401310 12269.273780
25% 12955.737547 12692.826335 15532.009725
50% 13120.625535 15363.251360 18794.745670
75% 13285.513523 15862.563915 18879.900590
max 13450.401510 16361.876470 18965.055510Agrupar por: split-apply-combine
Los métodos de vectorización y las operaciones de agrupación de Pandas son características que proporcionan a los usuarios mucha flexibilidad para analizar sus datos.
Por ejemplo, supongamos que queremos tener una visión más clara de cómo se dividen los países europeos según su PIB.
- Podemos echar un vistazo dividiendo los países en dos grupos durante los años estudiados, los que presentaron un PIB superior a la media europea y los que tuvieron un PIB inferior.
- A continuación, estimamos una puntuación de riqueza basada en los valores históricos (de 1962 a 2007), en la que tenemos en cuenta cuántas veces ha participado un país en los grupos de PIB más bajo o *más alto
PYTHON
mask_higher = data > data.mean()
wealth_score = mask_higher.aggregate('sum', axis=1) / len(data.columns)
print(wealth_score)SALIDA
country
Albania 0.000000
Austria 1.000000
Belgium 1.000000
Bosnia and Herzegovina 0.000000
Bulgaria 0.000000
Croatia 0.000000
Czech Republic 0.500000
Denmark 1.000000
Finland 1.000000
France 1.000000
Germany 1.000000
Greece 0.333333
Hungary 0.000000
Iceland 1.000000
Ireland 0.333333
Italy 0.500000
Montenegro 0.000000
Netherlands 1.000000
Norway 1.000000
Poland 0.000000
Portugal 0.000000
Romania 0.000000
Serbia 0.000000
Slovak Republic 0.000000
Slovenia 0.333333
Spain 0.333333
Sweden 1.000000
Switzerland 1.000000
Turkey 0.000000
United Kingdom 1.000000
dtype: float64Por último, para cada grupo de la tabla wealth_score,
sumamos su contribución (financiera) a lo largo de los años encuestados
utilizando métodos encadenados:
SALIDA
gdpPercap_1952 gdpPercap_1957 gdpPercap_1962 gdpPercap_1967 \
0.000000 36916.854200 46110.918793 56850.065437 71324.848786
0.333333 16790.046878 20942.456800 25744.935321 33567.667670
0.500000 11807.544405 14505.000150 18380.449470 21421.846200
1.000000 104317.277560 127332.008735 149989.154201 178000.350040
gdpPercap_1972 gdpPercap_1977 gdpPercap_1982 gdpPercap_1987 \
0.000000 88569.346898 104459.358438 113553.768507 119649.599409
0.333333 45277.839976 53860.456750 59679.634020 64436.912960
0.500000 25377.727380 29056.145370 31914.712050 35517.678220
1.000000 215162.343140 241143.412730 263388.781960 296825.131210
gdpPercap_1992 gdpPercap_1997 gdpPercap_2002 gdpPercap_2007
0.000000 92380.047256 103772.937598 118590.929863 149577.357928
0.333333 67918.093220 80876.051580 102086.795210 122803.729520
0.500000 36310.666080 40723.538700 45564.308390 51403.028210
1.000000 315238.235970 346930.926170 385109.939210 427850.333420Selección de valores individuales
Extensión del corte
¡No, no producen la misma salida! La salida de la primera sentencia es
SALIDA
gdpPercap_1952 gdpPercap_1957
country
Albania 1601.056136 1942.284244
Austria 6137.076492 8842.598030La segunda sentencia da:
SALIDA
gdpPercap_1952 gdpPercap_1957 gdpPercap_1962
country
Albania 1601.056136 1942.284244 2312.888958
Austria 6137.076492 8842.598030 10750.721110
Belgium 8343.105127 9714.960623 10991.206760Claramente, la segunda sentencia produce una columna y una fila
adicionales en comparación con la primera sentencia.
¿Qué conclusión podemos sacar? Vemos que un corte numérico, 0:2,
omite el índice final (es decir, el índice 2) en el rango
proporcionado, mientras que un corte con nombre,
‘gdpPercap_1952’:‘gdpPercap_1962’, incluye el elemento
final.
Reconstruyendo Datos
Explica qué hace cada línea del siguiente programa corto: ¿qué hay en
first, second, etc.?
Repasemos este trozo de código línea por línea.
Esta línea carga el conjunto de datos que contiene los datos del PIB
de todos los países en un marco de datos llamado first. El
parámetro index_col='country' selecciona la columna que se
utilizará como etiquetas de fila en el marco de datos.
Esta línea realiza una selección: sólo se extraen las filas de
first cuya columna “continente” coincida con “Américas”.
Observe cómo la expresión booleana dentro de los corchetes,
first['continent'] == 'Americas', se utiliza para
seleccionar sólo aquellas filas en las que la expresión es verdadera.
Intente imprimir esta expresión ¿Puede imprimir también sus elementos
individuales Verdadero/Falso? (pista: asigna primero la expresión a una
variable)
Como sugiere la sintaxis, esta línea elimina la fila de
second donde la etiqueta es ‘Puerto Rico’. El marco de
datos resultante third tiene una fila menos que el marco de
datos original second.
Volvemos a aplicar la función drop, pero en este caso no eliminamos
una fila, sino una columna entera. Para ello, tenemos que especificar
también el parámetro axis (queremos eliminar la segunda
columna que tiene el índice 1).
El paso final es escribir los datos con los que hemos estado
trabajando en un fichero csv. Pandas hace esto fácil con la función
to_csv(). El único argumento requerido para la función es
el nombre del fichero. Ten en cuenta que el fichero se escribirá en el
directorio desde el que iniciaste la sesión de Jupyter o Python.
Para cada columna de data, idxmin devolverá
el valor del índice correspondiente al mínimo de cada columna;
idxmax hará lo mismo para el valor máximo de cada
columna.
Puede utilizar estas funciones siempre que desee obtener el índice de fila del valor mínimo/máximo y no el valor mínimo/máximo real.
Practica con la selección
Supongamos que se ha importado Pandas y se han cargado los datos de PIB de Gapminder para Europa. Escriba una expresión para seleccionar cada uno de los siguientes elementos:
- PIB per cápita de todos los países en 1982.
- PIB per cápita de Dinamarca para todos los años.
- PIB per cápita de todos los países para los años después de 1985.
- PIB per cápita de cada país en 2007 como múltiplo del PIB per cápita
de ese país en
1:
2:
3:
Pandas es lo suficientemente inteligente como para reconocer el
número al final de la etiqueta de la columna y no le da un error, aunque
en realidad no exista ninguna columna llamada
gdpPercap_1985. Esto es útil si más tarde se añaden nuevas
columnas al fichero CSV.
4:
Muchas formas de acceso
Existen al menos dos formas de acceder a un valor o a un segmento de
un DataFrame: por nombre o por índice. Sin embargo, existen muchas
otras. Por ejemplo, se puede acceder a una sola columna o fila como un
objeto DataFrame o Series.
Sugiere distintas formas de realizar las siguientes operaciones en un DataFrame:
- Accede a una sola columna
- Accede a una única fila
- Accede a un elemento individual del DataFrame
- Accede a varias columnas
- Accede a varias filas
- Accede a un subconjunto de filas y columnas específicas
- Accede a un subconjunto de rangos de filas y columnas
1. Accede a una sola columna:
PYTHON
# por nombre
data["col_name"] # as a Series
data[["col_name"]] # as a DataFrame
# por nombre utilizando .loc
data.T.loc["col_name"] # as a Series
data.T.loc[["col_name"]].T # as a DataFrame
# notación punto (Series)
data.col_name
# por índice (iloc)
data.iloc[:, col_index] # as a Series
data.iloc[:, [col_index]] # as a DataFrame
# utilizando una máscara
data.T[data.T.index == "col_name"].T2. Accede a una única fila:
PYTHON
# por nombre utilizando .loc
data.loc["row_name"] # as a Series
data.loc[["row_name"]] # as a DataFrame
# por nombre
data.T["row_name"] # as a Series
data.T[["row_name"]].T # as a DataFrame
# por índice
data.iloc[row_index] # as a Series
data.iloc[[row_index]] # as a DataFrame
# utilizando máscara
data[data.index == "row_name"]3. Accede a un elemento individual del DataFrame:
PYTHON
# por nombre de columna/fila
data["column_name"]["row_name"] # as a Series
data[["col_name"]].loc["row_name"] # as a Series
data[["col_name"]].loc[["row_name"]] # as a DataFrame
data.loc["row_name"]["col_name"] # as a value
data.loc[["row_name"]]["col_name"] # as a Series
data.loc[["row_name"]][["col_name"]] # as a DataFrame
data.loc["row_name", "col_name"] # as a value
data.loc[["row_name"], "col_name"] # as a Series. Preserves index. Column name is moved to `.name`.
data.loc["row_name", ["col_name"]] # as a Series. Index is moved to `.name.` Sets index to column name.
data.loc[["row_name"], ["col_name"]] # as a DataFrame (preserves original index and column name)
# nombres de columna/fila: notacíon de punto
data.col_name.row_name
# índices de columna/fila
data.iloc[row_index, col_index] # as a value
data.iloc[[row_index], col_index] # as a Series. Preserves index. Column name is moved to `.name`
data.iloc[row_index, [col_index]] # as a Series. Index is moved to `.name.` Sets index to column name.
data.iloc[[row_index], [col_index]] # as a DataFrame (preserves original index and column name)
# nombre columna + índice fila
data["col_name"][row_index]
data.col_name[row_index]
data["col_name"].iloc[row_index]
# índice columna + nombre fila
data.iloc[:, [col_index]].loc["row_name"] # as a Series
data.iloc[:, [col_index]].loc[["row_name"]] # as a DataFrame
# utilizando máscaras
data[data.index == "row_name"].T[data.T.index == "col_name"].T4. Accede a varias columnas:
PYTHON
# por nombre
data[["col1", "col2", "col3"]]
data.loc[:, ["col1", "col2", "col3"]]
# por índice
data.iloc[:, [col1_index, col2_index, col3_index]]5. Accede a varias filas
PYTHON
# por nombre
data.loc[["row1", "row2", "row3"]]
# por índice
data.iloc[[row1_index, row2_index, row3_index]]6. Accede a un subconjunto de filas y columnas específicas
PYTHON
# por nombres
data.loc[["row1", "row2", "row3"], ["col1", "col2", "col3"]]
# por indices
data.iloc[[row1_index, row2_index, row3_index], [col1_index, col2_index, col3_index]]
# nombre columna + indice fila
data[["col1", "col2", "col3"]].iloc[[row1_index, row2_index, row3_index]]
# índice columna + nombre fila
data.iloc[:, [col1_index, col2_index, col3_index]].loc[["row1", "row2", "row3"]]7. Accede a un subconjunto de rangos de filas y columnas
PYTHON
# por nombre
data.loc["row1":"row2", "col1":"col2"]
# por índice
data.iloc[row1_index:row2_index, col1_index:col2_index]
# nombre columna + indice fila
data.loc[:, "col1_name":"col2_name"].iloc[row1_index:row2_index]
# índice columna + nombre fila
data.iloc[:, col1_index:col2_index].loc["row1":"row2"]Explorar los métodos disponibles utilizando la
función dir()
Python incluye una función dir() que se puede utilizar
para mostrar todos los métodos disponibles (funciones) que están
incorporados en un objeto de datos. En el Episodio 4, utilizamos algunos
métodos con una cadena. Pero podemos ver muchos más disponibles usando
dir():
Este comando devuelve:
PYTHON
['__add__',
...
'__subclasshook__',
'capitalize',
'casefold',
'center',
...
'upper',
'zfill']Puede utilizar help() o Shift+Tab
para obtener más información sobre lo que hacen estos métodos.
Supongamos que se ha importado Pandas y se han cargado los datos del
PIB de Gapminder para Europa como data. A continuación,
utilice dir() para encontrar la función que imprime la
mediana del PIB per cápita en todos los países europeos para cada año en
que la información está disponible.
Interpretación
Las fronteras de Polonia han sido estables desde 1945, pero cambiaron varias veces en los años anteriores. ¿Cómo gestionaría esta situación si estuviera creando una tabla del PIB per cápita de Polonia para todo el siglo XX?
- Usa
DataFrame.iloc[..., ...]para seleccionar valores por posición entera. - Use
:solo para significar todas las columnas o todas las filas. - Selecciona múltiples columnas o filas usando
DataFrame.locy una rebanada con nombre. - El resultado del corte puede usarse en operaciones posteriores.
- Utiliza comparaciones para seleccionar datos en función de su valor.
- Selecciona valores o NaN usando una máscara booleana.
Content from Trazando
Última actualización: 2025-07-01 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo representar mis datos?
- ¿Cómo puedo guardar mi gráfico para publicarlo?
Objetivos
- Crea un gráfico de series temporales mostrando un único conjunto de datos.
- Crea un gráfico de dispersión que muestra la relación entre dos conjuntos de datos.
matplotlib es la
librería de gráficos científicos más utilizada en Python.
- Comúnmente usa una sub-biblioteca llamada
matplotlib.pyplot. - Por defecto, Jupyter Notebook muestra los gráficos en línea.
- Los gráficos simples son (bastante) fáciles de crear.
PYTHON
time = [0, 1, 2, 3]
position = [0, 100, 200, 300]
plt.plot(time, position)
plt.xlabel('Time (hr)')
plt.ylabel('Position (km)')
Mostrar todas las figuras abiertas
En nuestro ejemplo de Jupyter Notebook, la ejecución de la celda debería generar la figura directamente debajo del código. La figura también se incluye en el documento de Notebook para su futura visualización. Sin embargo, otros entornos Python como una sesión Python interactiva iniciada desde un terminal o un script Python ejecutado a través de la línea de comandos requieren un comando adicional para mostrar la figura.
Indica a matplotlib que muestre una figura:
Este comando también puede usarse dentro de un Cuaderno - por ejemplo, para mostrar múltiples figuras si varias son creadas por una sola celda.
Trazar datos directamente desde un Pandas dataframe.
- También podemos graficar Pandas dataframes.
- Antes de graficar, convertimos los encabezados de columna de un tipo
de datos
stringainteger, ya que representan valores numéricos, usando str.replace() para eliminar el prefijogpdPercap_y luego astype(int) para convertir la serie de valores de cadena (['1952', '1957', ..., '2007']) a una serie de enteros:[1925, 1957, ..., 2007].
PYTHON
import pandas as pd
data = pd.read_csv('data/gapminder_gdp_oceania.csv', index_col='country')
# Extraer el año de los últimos 4 caracteres de cada nombre de columna
# Los nombres actuales de las columnas tienen la estructura 'gdpPercap_(año)',
# por lo que queremos conservar solo la parte del (año) para mayor claridad al graficar PIB vs. años
# Para ello usamos replace(), que elimina de la cadena los caracteres indicados en el argumento
# Este método funciona con cadenas, así que usamos replace() desde las funciones vectorizadas de cadenas de Pandas: Series.str
years = data.columns.str.replace('gdpPercap_', '')
# Convierte los valores de los años a integers, guardando los resultados de vuelta
data.columns = years.astype(int)
data.loc['Australia'].plot()
Selecciona y transforma los datos, luego los grafica.
- Por defecto,
DataFrame.plottraza con las filas como eje X. - Podemos transponer los datos para graficar múltiples series.

Hay muchos estilos disponibles.
- Por ejemplo, haga un gráfico de barras usando un estilo más elegante.

Los datos también pueden ser graficados llamando directamente a la
función matplotlib plot.
- El comando es
plt.plot(x, y) - El color y el formato de los marcadores también se puede especificar
como un argumento opcional adicional, por ejemplo,
b-es una línea azul,g--es una línea discontinua verde.
Obtener datos de Australia del marco de datos
PYTHON
years = data.columns
gdp_australia = data.loc['Australia']
plt.plot(years, gdp_australia, 'g--')
Puede graficar varios conjuntos de datos juntos.
PYTHON
# Select two countries' worth of data.
gdp_australia = data.loc['Australia']
gdp_nz = data.loc['New Zealand']
# Plot with differently-colored markers.
plt.plot(years, gdp_australia, 'b-', label='Australia')
plt.plot(years, gdp_nz, 'g-', label='New Zealand')
# Create legend.
plt.legend(loc='upper left')
plt.xlabel('Year')
plt.ylabel('GDP per capita ($)')Añadir una leyenda
A menudo, cuando se trazan múltiples conjuntos de datos en la misma figura, es deseable tener una leyenda que describa los datos.
Esto se puede hacer en matplotlib en dos etapas:
- Proporciona una etiqueta para cada conjunto de datos en la figura:
PYTHON
plt.plot(years, gdp_australia, label='Australia')
plt.plot(years, gdp_nz, label='New Zealand')- Indica a
matplotlibque cree la leyenda.
Por defecto matplotlib intentará colocar la leyenda en una posición
adecuada. Si prefiere especificar una posición, puede hacerlo con el
argumento loc=, por ejemplo, para colocar la leyenda en la
esquina superior izquierda del gráfico, especifique
loc='upper left'

- Traza un gráfico de dispersión correlacionando el PIB de Australia y Nueva Zelanda
- Utilice
plt.scatteroDataFrame.plot.scatter


Mínimos y Máximos
Rellena los espacios en blanco siguientes para representar el PIB per cápita mínimo a lo largo del tiempo para todos los países de Europa. Modifícalo de nuevo para trazar el PIB per cápita máximo a lo largo del tiempo para Europa.
![Una línea de código Python, print(nombre_del_átomo[0]), demuestra que el uso del índice cero mostrará sólo la letra inicial, en este caso “h” de helio](fig/2_indexing.svg){kind=link}
Correlaciones
Modifica el ejemplo de las notas para crear un gráfico de dispersión que muestre la relación entre el PIB per cápita mínimo y máximo entre los países de Asia para cada año del conjunto de datos. ¿Qué relación observas (si la hay)?
PYTHON
data_asia = pd.read_csv('data/gapminder_gdp_asia.csv', index_col='country')
data_asia.describe().T.plot(kind='scatter', x='min', y='max')
No se aprecian correlaciones particulares entre los valores mínimos y máximos del PIB año tras año. Parece que las fortunas de los países asiáticos no suben y bajan juntas.
Correlaciones (continued)
Parece que la variabilidad de este valor se debe a una fuerte caída después de 1972. ¿Tal vez haya algo de geopolítica en juego? Dado el predominio de los países productores de petróleo, tal vez el índice del crudo Brent sería una comparación interesante Mientras que Myanmar tiene sistemáticamente el PIB más bajo, la nación con el PIB más alto ha variado más notablemente.
Más Correlaciones
Este breve programa crea un gráfico que muestra la correlación entre el PIB y la esperanza de vida para 2007, normalizando el tamaño del marcador por la población:
PYTHON
data_all = pd.read_csv('data/gapminder_all.csv', index_col='country')
data_all.plot(kind='scatter', x='gdpPercap_2007', y='lifeExp_2007',
s=data_all['pop_2007']/1e6)Utilizando la ayuda en línea y otros recursos, explique qué hace cada
argumento de plot.

Un buen lugar para buscar es la documentación de la función plot - help(data_all.plot).
tipo - Como ya se ha visto, determina el tipo de gráfico que se dibujará.
x e y - Un nombre de columna o índice que determina qué datos se colocarán en los ejes x e y del gráfico
s - Encontrará más detalles en la documentación de plt.scatter. Un solo número o un valor para cada punto de datos. Determina el tamaño de los puntos trazados.
Guardar el gráfico en un archivo
Si estás satisfecho con el gráfico que ves, puede que quieras guardarlo en un archivo, tal vez para incluirlo en una publicación. Hay una función en el módulo matplotlib.pyplot que hace esto: savefig. Llamando a esta función, por ejemplo con
guardará la figura actual en el archivo my_figure.png.
El formato del archivo se deducirá automáticamente de la extensión del
nombre del archivo (otros formatos son pdf, ps, eps y svg).
Tenga en cuenta que las funciones en plt se refieren a
una variable de figura global y después de que una figura se ha mostrado
en la pantalla (por ejemplo, con plt.show) matplotlib hará
que esta variable se refiera a una nueva figura vacía. Por lo tanto,
asegúrese de llamar a plt.savefig antes de que el gráfico
se muestre en pantalla, de lo contrario puede encontrar un archivo con
un gráfico vacío.
Cuando se usan dataframes, los datos son a menudo generados y
graficados en pantalla en una sola línea. Además de usar
plt.savefig, podemos guardar una referencia a la figura
actual en una variable local (con plt.gcf) y llamar al
método de clase savefig desde esa variable para guardar la
figura en un fichero.
Haciendo sus gráficos accesibles
Siempre que estés generando gráficos para un artículo o una presentación, hay algunas cosas que puedes hacer para asegurarte de que todo el mundo pueda entender tus gráficos.
- Asegúrese siempre de que su texto es lo suficientemente grande como
para ser leído. Utilice el parámetro
fontsizeenxlabel,ylabel,title, ylegend, ytick_paramsconlabelsizepara aumentar el tamaño del texto de los números en sus ejes. - Del mismo modo, debe hacer que los elementos de su gráfico sean
fáciles de ver. Utilice
spara aumentar el tamaño de sus marcadores de dispersión ylinewidthpara aumentar el tamaño de sus líneas de trazado. - El uso del color (y nada más) para distinguir entre los diferentes
elementos del gráfico hará que sus gráficos sean ilegibles para
cualquiera que sea daltónico, o que tenga una impresora de oficina en
blanco y negro. Para las líneas, el parámetro
linestylele permite utilizar diferentes tipos de líneas. Para los gráficos de dispersión,markerle permite cambiar la forma de sus puntos. Si no está seguro de sus colores, puede utilizar Coblis u Oráculo de colores para simular el aspecto que tendrían sus gráficos para las personas daltónicas.
-
matplotlibes la librería de gráficos científicos más utilizada en Python. - Traza datos directamente desde un marco de datos Pandas.
- Selecciona y transforma datos, luego los grafica.
- Dispone de muchos estilos de representación gráfica: consulte la Galería gráfica de Python para más opciones.
- Puede graficar varios conjuntos de datos juntos.
Content from Almuerzo
Última actualización: 2025-02-28 | Mejora esta página
Durante el almuerzo, reflexiona y discute sobre lo siguiente:
- ¿Qué tipo de paquetes podrías utilizar en Python y por qué los utilizarías?
- ¿Cómo habría que formatear los datos para utilizarlos en los marcos de datos de Pandas? ¿Los datos que tienes cumplirían estos requisitos?
- ¿Qué limitaciones o problemas podrías encontrar al pensar en cómo aplicar lo que hemos aprendido a tus propios proyectos o datos?
Content from Listas
Última actualización: 2025-02-28 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo almacenar varios valores?
Objetivos
- Explica por qué los programas necesitan colecciones de valores.
- Escribe programas que creen listas planas, las indexen, las rebanen y las modifiquen mediante asignaciones y llamadas a métodos.
Una lista almacena muchos valores en una sola estructura.
- Hacer cálculos con cien variables llamadas
pressure_001,pressure_002, etc., sería al menos tan lento como hacerlos a mano. - Utiliza una lista para almacenar muchos valores juntos.
- Entre corchetes
[...]. - Valores separados por comas
,.
- Entre corchetes
- Utilice
lenpara averiguar cuántos valores hay en una lista.
PYTHON
pressures = [0.273, 0.275, 0.277, 0.275, 0.276]
print('pressures:', pressures)
print('length:', len(pressures))SALIDA
pressures: [0.273, 0.275, 0.277, 0.275, 0.276]
length: 5Utiliza el índice de un elemento para obtenerlo de una lista.
- Igual que las cadenas.
PYTHON
print('zeroth item of pressures:', pressures[0])
print('fourth item of pressures:', pressures[4])SALIDA
zeroth item of pressures: 0.273
fourth item of pressures: 0.276Los valores de las listas se pueden reemplazar asignándoles.
- Utilice una expresión de índice a la izquierda de la asignación para reemplazar un valor.
SALIDA
pressures is now: [0.265, 0.275, 0.277, 0.275, 0.276]Añadir elementos a una lista la alarga.
- Utilice
list_name.appendpara añadir elementos al final de una lista.
PYTHON
primes = [2, 3, 5]
print('primes is initially:', primes)
primes.append(7)
print('primes has become:', primes)SALIDA
primes is initially: [2, 3, 5]
primes has become: [2, 3, 5, 7]-
appendes un método de listas.- Como una función, pero ligada a un objeto concreto.
- Utilice
object_name.method_namepara llamar a métodos.- Se parece deliberadamente a la forma en que nos referimos a las cosas en una biblioteca.
- Conoceremos otros métodos de listas a medida que avancemos.
- Utilice
help(list)para una vista previa.
- Utilice
-
extendes similar aappend, pero permite combinar dos listas. Por ejemplo:
PYTHON
teen_primes = [11, 13, 17, 19]
middle_aged_primes = [37, 41, 43, 47]
print('primes is currently:', primes)
primes.extend(teen_primes)
print('primes has now become:', primes)
primes.append(middle_aged_primes)
print('primes has finally become:', primes)SALIDA
primes is currently: [2, 3, 5, 7]
primes has now become: [2, 3, 5, 7, 11, 13, 17, 19]
primes has finally become: [2, 3, 5, 7, 11, 13, 17, 19, [37, 41, 43, 47]]Tenga en cuenta que mientras extend mantiene la
estructura “plana” de la lista, añadir una lista a una lista significa
que el último elemento en primes será una lista, no un
entero. Las listas pueden contener valores de cualquier tipo, por lo que
son posibles listas de listas.
Utilice del para eliminar elementos de una lista por
completo.
- Utilizamos
del list_name[index]para eliminar un elemento de una lista (en el ejemplo, 9 no es un número primo) y así acortarla. -
delno es una función ni un método, sino una sentencia del lenguaje.
PYTHON
primes = [2, 3, 5, 7, 9]
print('primes before removing last item:', primes)
del primes[4]
print('primes after removing last item:', primes)SALIDA
primes before removing last item: [2, 3, 5, 7, 9]
primes after removing last item: [2, 3, 5, 7]La lista vacía no contiene valores.
- Utilice
[]solo para representar una lista que no contiene ningún valor.- “El cero de las listas”
- Útil como punto de partida para recoger valores (que veremos en el próximo episodio).
Las listas pueden contener valores de diferentes tipos.
- Una lista puede contener números, cadenas y cualquier otra cosa.
Las cadenas de caracteres pueden indexarse como listas.
- Obtiene caracteres individuales de una cadena de caracteres utilizando índices entre corchetes.
PYTHON
element = 'carbon'
print('zeroth character:', element[0])
print('third character:', element[3])SALIDA
zeroth character: c
third character: bLas cadenas de caracteres son inmutables.
- No se pueden cambiar los caracteres de una cadena una vez creada.
- Inmutable: no se puede modificar después de la creación.
- Por el contrario, las listas son mutables: pueden modificarse in situ.
- Python considera la cadena como un único valor con partes, no como una colección de valores.
ERROR
TypeError: 'str' object does not support item assignment- Tanto las listas como las cadenas de caracteres son colecciones.
Indexar más allá del final de la colección es un error.
- Python reporta un
IndexErrorsi intentamos acceder a un valor que no existe.- Esto es un tipo de error de ejecución.
- No puede detectarse al analizar el código porque el índice podría calcularse a partir de los datos.
SALIDA
IndexError: string index out of rangeRellene los espacios en blanco
¿Qué tamaño tiene una rebanada?
Si start y stop son enteros no negativos,
¿cuánto mide la lista values[start:stop]?
La lista values[start:stop] tiene hasta
stop - start elementos. Por ejemplo,
values[1:4] tiene los 3 elementos values[1],
values[2], y values[3]. ¿Por qué “hasta”? Como
vimos en el episodio 2, si
stop es mayor que la longitud total de la lista
values, seguiremos obteniendo una lista, pero será más
corta de lo esperado.
-
list('some string')convierte una cadena en una lista que contiene todos sus caracteres. -
joindevuelve una cadena que es la concatenación de cada elemento de cadena de la lista y añade el separador entre cada elemento de la lista. El resultado esx-y-z. El separador entre los elementos es la cadena que proporciona este método.
Trabajar con el final
¿Qué imprime el siguiente programa?
- ¿Cómo interpreta Python un índice negativo?
- Si una lista o cadena tiene N elementos, ¿cuál es el índice más negativo que se puede utilizar con seguridad con ella, y qué lugar representa ese índice?
- Si
valueses una lista, ¿qué hacedel values[-1]? - ¿Cómo puedes mostrar todos los elementos menos el último sin cambiar
values? (Sugerencia: tendrás que combinar el troceado y la indexación negativa)
El programa imprime m.
- Python interpreta un índice negativo como que empieza por el final
(en lugar de empezar por el principio). El último elemento es
-1. - El último índice que se puede utilizar con seguridad con una lista
de N elementos es el elemento
-N, que representa el primer elemento. -
del values[-1]elimina el último elemento de la lista. values[:-1]
El programa imprime
-
stridees el tamaño de paso de la rebanada. - El corte
1::2selecciona todos los elementos pares de una colección: comienza con el elemento1(que es el segundo elemento, ya que la indexación comienza en0), sigue hasta el final (ya que no se daend), y utiliza un tamaño de paso de2(es decir, selecciona cada dos elementos).
SALIDA
lithiumLa primera sentencia imprime toda la cadena, ya que la rebanada va más allá de la longitud total de la cadena. La segunda sentencia devuelve una cadena vacía, ya que el trozo se sale de los límites de la cadena.
El programa A imprime
SALIDA
letters is ['g', 'o', 'l', 'd'] and result is ['d', 'g', 'l', 'o']El programa B imprime
SALIDA
letters is ['d', 'g', 'l', 'o'] and result is Nonesorted(letters) devuelve una copia ordenada de la lista
letters (la lista original letters permanece
inalterada), mientras que letters.sort() ordena la lista
letters en su lugar y no devuelve nada.
El programa A imprime
SALIDA
new is ['D', 'o', 'l', 'd'] and old is ['D', 'o', 'l', 'd']El programa B imprime
SALIDA
new is ['D', 'o', 'l', 'd'] and old is ['g', 'o', 'l', 'd']new = old hace que new sea una referencia a
la lista old; new y old apuntan
al mismo objeto.
new = old[:] sin embargo crea un nuevo objeto lista
new que contiene todos los elementos de la lista
old; new y old son objetos
diferentes.
- Una lista almacena muchos valores en una única estructura.
- Utiliza el índice de un elemento para obtenerlo de una lista.
- Los valores de las listas pueden sustituirse asignándoles.
- Añadir elementos a una lista la alarga.
- Utilice
delpara eliminar elementos de una lista por completo. - La lista vacía no contiene valores.
- Las listas pueden contener valores de distintos tipos.
- Las cadenas de caracteres pueden indexarse como listas.
- Las cadenas de caracteres son inmutables.
- Indexar más allá del final de la colección es un error.
Content from Bucles For
Última actualización: 2025-02-28 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo hacer que un programa haga muchas cosas?
Objetivos
- Explica para qué se usan normalmente los bucles for.
- Traza la ejecución de un bucle simple (no anidado) e indica correctamente los valores de las variables en cada iteración.
- Escriba bucles for que utilicen el patrón Acumulador para agregar valores.
Un bucle for ejecuta órdenes una vez por cada valor de una colección.
- Hacer cálculos sobre los valores de una lista uno a uno es tan
doloroso como trabajar con
pressure_001,pressure_002, etc. - Un bucle for le dice a Python que ejecute algunas sentencias una vez por cada valor de una lista, una cadena de caracteres o alguna otra colección.
- “para cada cosa en este grupo, haz estas operaciones”
- Este bucle
fores equivalente a:
- Y la salida del bucle
fores:
SALIDA
2
3
5Un bucle for se compone de una colección, una variable
de bucle y un cuerpo.
- La colección,
[2, 3, 5], es sobre la que se está ejecutando el bucle. - El cuerpo,
print(number), especifica qué hacer para cada valor de la colección. - La variable de bucle,
number, es la que cambia en cada iteración del bucle.- Lo “actual”.
La primera línea del bucle for debe terminar con dos
puntos, y el cuerpo debe tener sangría.
- Los dos puntos al final de la primera línea indican el inicio de un bloque de sentencias.
- Python usa sangría en lugar de
{}obegin/endpara mostrar anidamiento.- Cualquier sangría consistente es legal, pero casi todo el mundo utiliza cuatro espacios.
ERROR
IndentationError: expected an indented block- La sangría siempre tiene sentido en Python.
ERROR
File "<ipython-input-7-f65f2962bf9c>", line 2
lastName = "Smith"
^
IndentationError: unexpected indent- Este error puede solucionarse eliminando los espacios sobrantes al principio de la segunda línea.
Las variables de bucle pueden llamarse como se quiera.
- Como todas las variables, las variables de bucle son:
- Creado a petición.
- Sin sentido: sus nombres pueden ser cualquier cosa.
El cuerpo de un bucle puede contener muchas sentencias.
- Pero ningún bucle debe tener más de unas pocas líneas.
- Difícil para los seres humanos mantener en mente grandes trozos de código.
SALIDA
2 4 8
3 9 27
5 25 125Use range para iterar sobre una secuencia de
números.
- La función incorporada
rangeproduce una secuencia de números.- No una lista: los números se producen bajo demanda para hacer más eficiente el bucle sobre rangos grandes.
-
range(N)son los números 0..N-1- Exactamente los índices legales de una lista o cadena de caracteres de longitud N
SALIDA
a range is not a list: range(0, 3)
0
1
2El patrón Acumulador convierte muchos valores en uno.
- Un patrón común en los programas es:
- Inicializa una variable acumulador a cero, la cadena vacía o la lista vacía.
- Actualiza la variable con valores de una colección.
PYTHON
# Sum the first 10 integers.
total = 0
for number in range(10):
total = total + (number + 1)
print(total)SALIDA
55- Lee
total = total + (number + 1)como:- Suma 1 al valor actual de la variable de bucle
number. - Añádelo al valor actual de la variable acumuladora
total. - Asigna esto a
total, reemplazando el valor actual.
- Suma 1 al valor actual de la variable de bucle
- Tenemos que añadir
number + 1porquerangeproduce 0..9, no 1..10.
Clasificación de errores
¿Un error de sangría es un error de sintaxis o de ejecución?
Un IndentationError es un error de sintaxis. Los programas con errores de sintaxis no pueden iniciarse. Un programa con un error de ejecución se iniciará pero se lanzará un error bajo ciertas condiciones.
| Line no | Variables |
|---|---|
| 1 | total = 0 |
| 2 | total = 0 char = ‘t’ |
| 3 | total = 1 char = ‘t’ |
| 2 | total = 1 char = ‘i’ |
| 3 | total = 2 char = ‘i’ |
| 2 | total = 2 char = ‘n’ |
| 3 | total = 3 char = ‘n’ |
Practica Acumulando (continued)
Crea un acrónimo: A partir de la lista
["red", "green", "blue"], crea el acrónimo
"RGB" usando un bucle for.
Pista: Puede que necesites usar un método de cadena para formatear correctamente el acrónimo.
Suma Acumulada
Reordena y aplica la sangría adecuada a las líneas de código
siguientes para que impriman una lista con la suma acumulada de datos.
El resultado debe ser [1, 3, 5, 10].
Identificación de errores de nombres de variables
- Lee el siguiente código e intenta identificar cuáles son los errores sin ejecutarlo.
- Ejecuta el código y lee el mensaje de error. ¿Qué tipo de
NameErrorcrees que es? ¿Es una cadena sin comillas, una variable mal escrita, o una variable que debería haber sido definida pero no lo fue? - Corrige el error.
- Repita los pasos 2 y 3, hasta que haya corregido todos los errores.
- Los nombres de variables en Python distinguen entre mayúsculas y
minúsculas:
numberyNumberse refieren a variables diferentes. - La variable
messagedebe inicializarse como una cadena vacía. - Queremos añadir la cadena
"a"amessage, no la variable indefinidaa.
Identificación de errores de posición
- Un bucle for ejecuta órdenes una vez por cada valor de una colección.
- Un bucle
forse compone de una colección, una variable de bucle y un cuerpo. - La primera línea del bucle
fordebe terminar con dos puntos, y el cuerpo debe tener sangría. - La sangría siempre tiene sentido en Python.
- Las variables de bucle pueden llamarse como se quiera (pero se recomienda encarecidamente dar un nombre significativo a la variable de bucle).
- El cuerpo de un bucle puede contener muchas sentencias.
- Utilice
rangepara iterar sobre una secuencia de números. - El patrón Acumulador convierte muchos valores en uno.
Content from Condicionales
Última actualización: 2025-02-28 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo pueden los programas hacer cosas diferentes para datos diferentes?
Objetivos
- Escribir correctamente programas que utilicen sentencias if y else y expresiones booleanas sencillas (sin operadores lógicos).
- Rastrea la ejecución de condicionales no anidadas y condicionales dentro de bucles.
Usar sentencias if para controlar si un bloque de
código se ejecuta o no.
- Una sentencia
if(más propiamente llamada sentencia condicional) controla si un bloque de código se ejecuta o no. - La estructura es similar a una sentencia
for:- La primera línea se abre con
ify termina con dos puntos - El cuerpo que contiene una o más sentencias tiene sangría (normalmente de 4 espacios)
- La primera línea se abre con
PYTHON
mass = 3.54
if mass > 3.0:
print(mass, 'is large')
mass = 2.07
if mass > 3.0:
print (mass, 'is large')SALIDA
3.54 is largeLos condicionales se usan a menudo dentro de bucles.
- No tiene mucho sentido usar una condicional cuando conocemos el valor (como arriba).
- Pero útil cuando tenemos una colección que procesar.
SALIDA
3.54 is large
9.22 is largeUse else para ejecutar un bloque de código cuando una
condición if es no verdadera.
-
elsepuede utilizarse después deif. - Nos permite especificar una alternativa a ejecutar cuando la rama
ifno está tomada.
PYTHON
masses = [3.54, 2.07, 9.22, 1.86, 1.71]
for m in masses:
if m > 3.0:
print(m, 'is large')
else:
print(m, 'is small')SALIDA
3.54 is large
2.07 is small
9.22 is large
1.86 is small
1.71 is smallUtilice elif para especificar pruebas adicionales.
- Puede proporcionar varias opciones alternativas, cada una con su propia prueba.
- Utilice
elif(abreviatura de “else if”) y una condición para especificarlas. - Siempre asociado a un
if. - Debe ir antes de
else(que es el “catch all”).
PYTHON
masses = [3.54, 2.07, 9.22, 1.86, 1.71]
for m in masses:
if m > 9.0:
print(m, 'is HUGE')
elif m > 3.0:
print(m, 'is large')
else:
print(m, 'is small')SALIDA
3.54 is large
2.07 is small
9.22 is HUGE
1.86 is small
1.71 is smallLas condiciones se prueban una vez, en orden.
- Python recorre las ramas de la condicional en orden, probando cada una a su vez.
- El orden es importante.
PYTHON
grade = 85
if grade >= 90:
print('grade is A')
elif grade >= 80:
print('grade is B')
elif grade >= 70:
print('grade is C')SALIDA
grade is B- No vuelve atrás automáticamente y reevalúa si los valores cambian.
PYTHON
velocity = 10.0
if velocity > 20.0:
print('moving too fast')
else:
print('adjusting velocity')
velocity = 50.0SALIDA
adjusting velocity- Utiliza a menudo condicionales en un bucle para “evolucionar” los valores de las variables.
PYTHON
velocity = 10.0
for i in range(5): # execute the loop 5 times
print(i, ':', velocity)
if velocity > 20.0:
print('moving too fast')
velocity = velocity - 5.0
else:
print('moving too slow')
velocity = velocity + 10.0
print('final velocity:', velocity)SALIDA
0 : 10.0
moving too slow
1 : 20.0
moving too slow
2 : 30.0
moving too fast
3 : 25.0
moving too fast
4 : 20.0
moving too slow
final velocity: 30.0Crear una tabla con los valores de las variables para seguir la ejecución de un programa.
| i | 0 | . | 1 | . | 2 | . | 3 | . | 4 | . |
| velocity | 10.0 | 20.0 | . | 30.0 | . | 25.0 | . | 20.0 | . | 30.0 |
- El programa debe tener una sentencia
printfuera del cuerpo del bucle para mostrar el valor final develocity, ya que su valor se actualiza en la última iteración del bucle.
Relaciones compuestas usando and,
or y paréntesis
A menudo, se desea que alguna combinación de cosas sea verdadera.
Puede combinar relaciones dentro de una condicional utilizando
and y or. Siguiendo con el ejemplo anterior,
supongamos que tenemos
PYTHON
mass = [ 3.54, 2.07, 9.22, 1.86, 1.71]
velocity = [10.00, 20.00, 30.00, 25.00, 20.00]
i = 0
for i in range(5):
if mass[i] > 5 and velocity[i] > 20:
print("Fast heavy object. Duck!")
elif mass[i] > 2 and mass[i] <= 5 and velocity[i] <= 20:
print("Normal traffic")
elif mass[i] <= 2 and velocity[i] <= 20:
print("Slow light object. Ignore it")
else:
print("Whoa! Something is up with the data. Check it")Al igual que con la aritmética, puede y debe utilizar paréntesis
siempre que exista una posible ambigüedad. Una buena regla general es
usar siempre paréntesis cuando se mezclan and y
or en la misma condición. Es decir, en lugar de
escribe uno de estos:
PYTHON
if (mass[i] <= 2 or mass[i] >= 5) and velocity[i] > 20:
if mass[i] <= 2 or (mass[i] >= 5 and velocity[i] > 20):para que quede perfectamente claro para un lector (y para Python) lo que realmente quieres decir.
SALIDA
25.0Recorte de Valores
Rellena los espacios en blanco para que este programa cree una nueva lista que contenga ceros donde los valores de la lista original eran negativos y unos donde los valores de la lista original eran positivos.
PYTHON
original = [-1.5, 0.2, 0.4, 0.0, -1.3, 0.4]
result = ____
for value in original:
if ____:
result.append(0)
else:
____
print(result)SALIDA
[0, 1, 1, 1, 0, 1]Inicializando
Modifica este programa para que encuentre los valores mayor y menor de la lista sin importar el rango de valores original.
PYTHON
values = [...some test data...]
smallest, largest = None, None
for v in values:
if ____:
smallest, largest = v, v
____:
smallest = min(____, v)
largest = max(____, v)
print(smallest, largest)¿Cuáles son las ventajas y desventajas de utilizar este método para hallar el rango de los datos?
PYTHON
values = [-2,1,65,78,-54,-24,100]
smallest, largest = None, None
for v in values:
if smallest is None and largest is None:
smallest, largest = v, v
else:
smallest = min(smallest, v)
largest = max(largest, v)
print(smallest, largest)Si escribiste == None en lugar de is None,
también funciona, pero los programadores de Python siempre escriben
is None debido a la forma especial en que None
funciona en el lenguaje.
Se puede argumentar que una ventaja de utilizar este método sería
hacer el código más legible. Sin embargo, una desventaja es que este
código no es eficiente porque dentro de cada iteración de la declaración
del bucle for, hay dos bucles más que se ejecutan sobre dos
números cada uno (las funciones min y max).
Sería más eficiente iterar sobre cada número una sola vez:
PYTHON
values = [-2,1,65,78,-54,-24,100]
smallest, largest = None, None
for v in values:
if smallest is None or v < smallest:
smallest = v
if largest is None or v > largest:
largest = v
print(smallest, largest)Ahora tenemos un bucle, pero cuatro pruebas de comparación. Hay dos formas de mejorarlo: o bien utilizar menos comparaciones en cada iteración, o bien utilizar dos bucles que contengan cada uno sólo una prueba de comparación. La solución más sencilla suele ser la mejor:
- Utilice sentencias
ifpara controlar si se ejecuta o no un bloque de código. - Los condicionales se usan a menudo dentro de bucles.
- Utilice
elsepara ejecutar un bloque de código cuando una condiciónifes no verdadera. - Utilice
elifpara especificar pruebas adicionales. - Las condiciones se prueban una vez, en orden.
- Crea una tabla con los valores de las variables para seguir la ejecución de un programa.
Content from Bucle sobre conjuntos de datos
Última actualización: 2025-07-01 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo procesar muchos conjuntos de datos con un solo comando?
Objetivos
- Ser capaz de leer y escribir expresiones globbing que coincidan con conjuntos de ficheros.
- Utilice glob para crear listas de ficheros.
- Escribe bucles for para realizar operaciones sobre ficheros dados sus nombres en una lista.
Utiliza un bucle for para procesar ficheros dada una
lista de sus nombres.
- Un nombre de fichero es una cadena de caracteres.
- Y las listas pueden contener cadenas de caracteres.
PYTHON
import pandas as pd
for filename in ['data/gapminder_gdp_africa.csv', 'data/gapminder_gdp_asia.csv']:
data = pd.read_csv(filename, index_col='country')
print(filename, data.min())SALIDA
data/gapminder_gdp_africa.csv gdpPercap_1952 298.846212
gdpPercap_1957 335.997115
gdpPercap_1962 355.203227
gdpPercap_1967 412.977514
⋮ ⋮ ⋮
gdpPercap_1997 312.188423
gdpPercap_2002 241.165877
gdpPercap_2007 277.551859
dtype: float64
data/gapminder_gdp_asia.csv gdpPercap_1952 331
gdpPercap_1957 350
gdpPercap_1962 388
gdpPercap_1967 349
⋮ ⋮ ⋮
gdpPercap_1997 415
gdpPercap_2002 611
gdpPercap_2007 944
dtype: float64Use glob.glob
para encontrar conjuntos de ficheros cuyos nombres coincidan con un
patrón.
- En Unix, el término “globbing” significa “buscar un conjunto de ficheros con un patrón”.
- Los patrones más comunes son:
-
*significa “coincide con cero o más caracteres” -
?significa “coincide exactamente con un carácter”
-
- La librería estándar de Python contiene el módulo
globpara proporcionar la funcionalidad de coincidencia de patrones - El módulo
globcontiene una función también llamadaglobpara encontrar patrones de ficheros - Por ejemplo,
glob.glob('*.txt')coincide con todos los ficheros del directorio actual cuyos nombres terminen en.txt. - El resultado es una lista (posiblemente vacía) de cadenas de caracteres.
SALIDA
all csv files in data directory: ['data/gapminder_all.csv', 'data/gapminder_gdp_africa.csv', \
'data/gapminder_gdp_americas.csv', 'data/gapminder_gdp_asia.csv', 'data/gapminder_gdp_europe.csv', \
'data/gapminder_gdp_oceania.csv']SALIDA
all PDB files: []Utilice glob y for para procesar lotes de
ficheros.
- Ayuda mucho si los ficheros se nombran y almacenan de forma sistemática y consistente para que los patrones simples encuentren los datos correctos.
PYTHON
for filename in glob.glob('data/gapminder_*.csv'):
data = pd.read_csv(filename)
print(filename, data['gdpPercap_1952'].min())SALIDA
data/gapminder_all.csv 298.8462121
data/gapminder_gdp_africa.csv 298.8462121
data/gapminder_gdp_americas.csv 1397.717137
data/gapminder_gdp_asia.csv 331.0
data/gapminder_gdp_europe.csv 973.5331948
data/gapminder_gdp_oceania.csv 10039.59564- Incluye todos los datos, así como los datos por región.
- Utilice un patrón más específico en los ejercicios para excluir todo el conjunto de datos.
- Pero tenga en cuenta que el mínimo de todo el conjunto de datos es también el mínimo de uno de los conjuntos de datos, lo que es una buena comprobación de la corrección.
Determinación de coincidencias
¿Cuál de estos ficheros no coincide con la expresión
glob.glob('data/*as*.csv')?
data/gapminder_gdp_africa.csvdata/gapminder_gdp_americas.csvdata/gapminder_gdp_asia.csv
1 no coincide con el glob.
Tamaño mínimo de fichero
Modifica este programa para que imprima el número de registros del fichero que menos registros tenga.
PYTHON
import glob
import pandas as pd
fewest = ____
for filename in glob.glob('data/*.csv'):
dataframe = pd.____(filename)
fewest = min(____, dataframe.shape[0])
print('smallest file has', fewest, 'records')Tenga en cuenta que el método DataFrame.shape()
devuelve una tupla con el número de filas y columnas del marco de
datos.
PYTHON
import glob
import pandas as pd
fewest = float('Inf')
for filename in glob.glob('data/*.csv'):
dataframe = pd.read_csv(filename)
fewest = min(fewest, dataframe.shape[0])
print('smallest file has', fewest, 'records')Puede que hayas elegido inicializar la variable fewest
con un número mayor que los números con los que estás tratando, pero eso
podría traerte problemas si reutilizas el código con números mayores.
Python te permite usar infinito positivo, que funcionará sin importar lo
grandes que sean tus números. ¿Qué otras cadenas especiales reconoce la
función float?
Comparación de datos
Escribe un programa que lea los conjuntos de datos regionales y represente el PIB per cápita medio de cada región a lo largo del tiempo en un único gráfico. Pandas emitirá un error si encuentra columnas no numéricas en el cálculo de un marco de datos, por lo que es posible que tenga que filtrar esas columnas o decirle a pandas que las ignore.
Esta solución construye una leyenda útil utilizando el método string
split method para extraer el region de la
ruta ‘data/gapminder_gdp_a_specific_region.csv’.
PYTHON
import glob
import pandas as pd
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1,1)
for filename in glob.glob('data/gapminder_gdp*.csv'):
dataframe = pd.read_csv(filename)
# extraer <región> del nombre de archivo, que se espera en el formato 'data/gapminder_gdp_<region>.csv'
# dividiremos la cadena utilizando el método split y `_` como separador,
# recuperaremos la última cadena de la lista que devuelve split (`<region>.csv`),
# y luego eliminaremos la extensión `.csv` de esa cadena.
# NOTA: el módulo pathlib, que se cubre en el siguiente apartado, también ofrece
# abstracciones convenientes para trabajar con rutas del sistema de archivos y podría resolver esto también:
# from pathlib import Path
# region = Path(filename).stem.split('_')[-1]
region = filename.split('_')[-1][:-4]
# exreae los años de las columnas del dataframe
headings = dataframe.columns[1:]
years = headings.str.split('_').str.get(1)
# pandas tira errores cuando se encuentra con columnas no-numŕeicas en la computación de un dataframe
# pero podemos decir a pandas que los ignore con el parámetro 'numeric_only`
dataframe.mean(numeric_only=True).plot(ax=ax, label=region)
# NOTA: otra manera de hacer esto es seleccionar solo las columnas con gdp en su nombre utilizando el método de filtraje
# dataframe.filter(like="gdp").mean().plot(ax=ax, label=region)
# set the title and labels
ax.set_title('GDP Per Capita for Regions Over Time')
ax.set_xticks(range(len(years)))
ax.set_xticklabels(years)
ax.set_xlabel('Year')
plt.tight_layout()
plt.legend()
plt.show()Tratamiento de rutas de ficheros
El módulo pathlib
proporciona abstracciones útiles para la manipulación de ficheros y
rutas, como devolver el nombre de un fichero sin la extensión. Esto es
muy útil cuando se realiza un bucle sobre archivos y directorios. En el
siguiente ejemplo, creamos un objeto Path e inspeccionamos
sus atributos.
PYTHON
from pathlib import Path
p = Path("data/gapminder_gdp_africa.csv")
print(p.parent)
print(p.stem)
print(p.suffix)SALIDA
data
gapminder_gdp_africa
.csvPista: Comprueba todos los atributos y métodos
disponibles en el objeto Path con la función
dir().
- Utiliza un bucle
forpara procesar ficheros a partir de una lista de nombres. - Utilice
glob.globpara encontrar conjuntos de ficheros cuyos nombres coincidan con un patrón. - Utilice
globyforpara procesar lotes de ficheros.
Content from Café de la tarde
Última actualización: 2025-02-28 | Mejora esta página
Ejercicio de reflexión
Durante el descanso, reflexiona y discute sobre lo siguiente:
- Un refrán común en ingeniería de software es “No te repitas”. ¿Cómo nos ayudan las técnicas que hemos aprendido en las últimas lecciones a evitar repetirnos? Ten en cuenta que, en la práctica, esto tiene sus matices y debe equilibrarse con hacer lo más sencillo que pueda funcionar.
- ¿Cuáles son los pros y los contras de hacer que una variable sea global o local en una función?
- ¿Cuándo considerarías convertir un bloque de código en una definición de función?
Content from Funciones de escritura
Última actualización: 2025-07-01 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo crear mis propias funciones?
Objetivos
- Explica e identifica la diferencia entre definición de función y llamada a función.
- Escribe una función que tome un número pequeño y fijo de argumentos y produzca un único resultado.
Descomponer los programas en funciones para facilitar su comprensión.
- Los seres humanos sólo pueden mantener unos pocos elementos en la memoria de trabajo a la vez.
- Comprender ideas más grandes/más complicadas entendiendo y
combinando piezas.
- Componentes de una máquina.
- Lemas para demostrar teoremas.
- Las funciones tienen el mismo propósito en los programas.
- Encapsular la complejidad para que podamos tratarla como una única “cosa”.
- También permite reutilizar.
- Escribir una vez, usar muchas veces.
Define una función usando def con un nombre, parámetros
y un bloque de código.
- Comienza la definición de una nueva función con
def. - Seguido del nombre de la función.
- Debe obedecer las mismas reglas que los nombres de variables.
- Entonces parámetros entre paréntesis.
- Paréntesis vacíos si la función no toma ninguna entrada.
- Lo discutiremos en detalle dentro de un momento.
- Entonces dos puntos.
- A continuación, un bloque de código con sangría.
Definir una función no la ejecuta.
- Definir una función no la ejecuta.
- Como asignar un valor a una variable.
- Debe llamar a la función para ejecutar el código que contiene.
SALIDA
Hello!Los argumentos de una llamada a función se corresponden con sus parámetros definidos.
- Las funciones son más útiles cuando pueden operar sobre diferentes datos.
- Especifica parámetros al definir una función.
- Se convierten en variables cuando se ejecuta la función.
- Se asignan los argumentos en la llamada (es decir, los valores pasados a la función).
- Si no nombras los argumentos cuando los usas en la llamada, los argumentos se emparejarán con los parámetros en el orden en que los parámetros están definidos en la función.
PYTHON
def print_date(year, month, day):
joined = str(year) + '/' + str(month) + '/' + str(day)
print(joined)
print_date(1871, 3, 19)SALIDA
1871/3/19O bien, podemos nombrar los argumentos cuando llamamos a la función, lo que nos permite especificarlos en cualquier orden y añade claridad al sitio de llamada; de lo contrario, mientras uno está leyendo el código podría olvidar si el segundo argumento es el mes o el día, por ejemplo.
SALIDA
1871/3/19- Vía Twitter:
()contiene los ingredientes de la función mientras que el cuerpo contiene la receta.
Las funciones pueden devolver un resultado a su invocador usando
return.
- Utiliza
return ...para devolver un valor al llamante. - Puede aparecer en cualquier parte de la función.
- Pero las funciones son más fáciles de entender si aparece
return:- Al principio para tratar casos especiales.
- Al final, con un resultado final.
SALIDA
average of actual values: 2.6666666666666665SALIDA
average of empty list: None- Recuerda: toda función devuelve algo.
- Una función que no explícitamente
returnun valor devuelve automáticamenteNone.
SALIDA
1871/3/19
result of call is: NoneIdentificación de errores de sintaxis
- Lee el siguiente código e intenta identificar cuáles son los errores sin ejecutarlo.
- Ejecuta el código y lee el mensaje de error. ¿Es un
SyntaxErroro unIndentationError? - Corrige el error.
- Repite los pasos 2 y 3 hasta que hayas corregido todos los errores.
SALIDA
calling <function report at 0x7fd128ff1bf8> 22.5Una llamada a una función siempre necesita paréntesis, de lo contrario se obtiene la dirección de memoria del objeto de la función. Por lo tanto, si quisiéramos llamar a la función llamada informe, y darle el valor 22.5 para informar, podríamos tener nuestra llamada a la función de la siguiente manera
SALIDA
calling
pressure is 22.5Orden de operaciones
- ¿Qué falla en este ejemplo?
PYTHON
result = print_time(11, 37, 59)
def print_time(hour, minute, second):
time_string = str(hour) + ':' + str(minute) + ':' + str(second)
print(time_string)- Después de solucionar el problema anterior, explica por qué ejecutar este código de ejemplo:
da esta salida:
SALIDA
11:37:59
result of call is: None- ¿Por qué el resultado de la llamada es
None?
El problema con el ejemplo es que la función
print_time()se define después de hacer la llamada a la función. Python no sabe cómo resolver el nombreprint_timeya que no se ha definido todavía y lanzará unNameErrorpor ejemplo,NameError: name 'print_time' is not definedLa primera línea de salida
11:37:59es impresa por la primera línea de código,result = print_time(11, 37, 59)que vincula el valor devuelto por la invocaciónprint_timea la variableresult. La segunda línea es de la segunda llamada de impresión para imprimir el contenido de la variableresult.print_time()no devuelve explícitamentereturnun valor, por lo que devuelve automáticamenteNone.
Hallar el Primer
Rellena los espacios en blanco para crear una función que tome una lista de números como argumento y devuelva el primer valor negativo de la lista. ¿Qué hace la función si la lista está vacía? ¿Y si la lista no tiene números negativos?
Llamado por su nombre
Anteriormente vimos esta función:
PYTHON
def print_date(year, month, day):
joined = str(year) + '/' + str(month) + '/' + str(day)
print(joined)Vimos que podemos llamar a la función usando nombres de argumentos, así:
- ¿Qué imprime
print_date(day=1, month=2, year=2003)? - ¿Cuándo has visto una llamada a una función como ésta?
- ¿Cuándo y por qué es útil llamar así a las funciones?
2003/2/1- Vimos ejemplos de uso de argumentos con nombre al trabajar
con la librería pandas. Por ejemplo, cuando se lee un conjunto de datos
usando
data = pd.read_csv('data/gapminder_gdp_europe.csv', index_col='country'), el último argumentoindex_coles un argumento con nombre. - El uso de argumentos con nombre puede hacer que el código sea más legible, ya que uno puede ver en la llamada a la función qué nombre tienen los diferentes argumentos dentro de la función. También puede reducir las posibilidades de pasar argumentos en el orden incorrecto, ya que al utilizar argumentos con nombre el orden no importa.
Encapsulación de un bloque If/Print
El siguiente código se ejecutará en una impresora de etiquetas para huevos de gallina. Una balanza digital informará de la masa de un huevo de gallina (en gramos) al ordenador y éste imprimirá una etiqueta.
PYTHON
import random
for i in range(10):
# simulando la masa de un huevo de gallina
# la masa (aleatoria) será de 70 +/- 20 gramos
mass = 70 + 20.0 * (2.0 * random.random() - 1.0)
print(mass)
# la maquinaria de los huevos de gallina imprime una etiqueta
if mass >= 85:
print("jumbo")
elif mass >= 70:
print("large")
elif mass < 70 and mass >= 55:
print("medium")
else:
print("small")El bloque if que clasifica los huevos podría ser útil en otras
situaciones, así que para evitar repetirlo, podríamos plegarlo en una
función, get_egg_label(). Revisando el programa para usar
la función tendríamos esto:
PYTHON
# versíón revisada
import random
for i in range(10):
# simulando la masa de un huevo de gallina
# la masa (aleatoria) será de 70 +/- 20 gramos
mass = 70 + 20.0 * (2.0 * random.random() - 1.0)
print(mass, get_egg_label(mass))- Cree una definición de función para
get_egg_label()que funcione con el programa revisado anteriormente. Tenga en cuenta que el valor de retorno de la funciónget_egg_label()será importante. La salida de ejemplo del programa anterior sería71.23 large. - Un huevo sucio puede tener una masa superior a 90 gramos, y un huevo
estropeado o roto probablemente tendrá una masa inferior a 50 gramos.
Modifique su función
get_egg_label()para tener en cuenta estas condiciones de error. Un ejemplo de salida podría ser25 too light, probably spoiled.
PYTHON
def get_egg_label(mass):
# la maquinaria de los huevos de gallina imprime una etiqueta
egg_label = "Unlabelled"
if mass >= 90:
egg_label = "warning: egg might be dirty"
elif mass >= 85:
egg_label = "jumbo"
elif mass >= 70:
egg_label = "large"
elif mass < 70 and mass >= 55:
egg_label = "medium"
elif mass < 50:
egg_label = "too light, probably spoiled"
else:
egg_label = "small"
return egg_labelAnálisis encapsulado de datos
Supongamos que se ha ejecutado el siguiente código:
PYTHON
import pandas as pd
data_asia = pd.read_csv('data/gapminder_gdp_asia.csv', index_col=0)
japan = data_asia.loc['Japan']- Complete los enunciados siguientes para obtener el PIB medio de Japón en los años indicados para la década de 1980.
PYTHON
year = 1983
gdp_decade = 'gdpPercap_' + str(year // ____)
avg = (japan.loc[gdp_decade + ___] + japan.loc[gdp_decade + ___]) / 2- Abstrae el código anterior en una única función.
PYTHON
def avg_gdp_in_decade(country, continent, year):
data_countries = pd.read_csv('data/gapminder_gdp_'+___+'.csv',delimiter=',',index_col=0)
____
____
____
return avg- ¿Cómo generalizaría esta función si no supiera de antemano qué años concretos aparecen como columnas en los datos? Por ejemplo, ¿qué pasaría si también tuviéramos datos de los años que terminan en 1 y 9 para cada década? (Sugerencia: utilice las columnas para filtrar las que corresponden a la década, en lugar de enumerarlas en el código)
- El PIB medio de Japón a lo largo de los años reportados para la década de 1980 se calcula con:
PYTHON
year = 1983
gdp_decade = 'gdpPercap_' + str(year // 10)
avg = (japan.loc[gdp_decade + '2'] + japan.loc[gdp_decade + '7']) / 2- Que se codifica como una función es:
PYTHON
def avg_gdp_in_decade(country, continent, year):
data_countries = pd.read_csv('data/gapminder_gdp_' + continent + '.csv', index_col=0)
c = data_countries.loc[country]
gdp_decade = 'gdpPercap_' + str(year // 10)
avg = (c.loc[gdp_decade + '2'] + c.loc[gdp_decade + '7'])/2
return avg- Para obtener la media de los años relevantes, necesitamos hacer un bucle sobre ellos:
PYTHON
def avg_gdp_in_decade(country, continent, year):
data_countries = pd.read_csv('data/gapminder_gdp_' + continent + '.csv', index_col=0)
c = data_countries.loc[country]
gdp_decade = 'gdpPercap_' + str(year // 10)
total = 0.0
num_years = 0
for yr_header in c.index: # c's index contains reported years
if yr_header.startswith(gdp_decade):
total = total + c.loc[yr_header]
num_years = num_years + 1
return total/num_yearsLa función se puede llamar ahora por:
SALIDA
20880.023800000003Simulación de un sistema dinámico
En matemáticas, un sistema dinámico es un sistema en el que una función describe la dependencia temporal de un punto en un espacio geométrico. Un ejemplo canónico de sistema dinámico es el mapa logístico, un modelo de crecimiento que calcula una nueva densidad de población (entre 0 y 1) a partir de la densidad actual. En el modelo, el tiempo toma valores discretos 0, 1, 2, …
- Definir una función llamada
logistic_mapque toma dos entradas:x, que representa la población actual (en el momentot), y un parámetror = 1. Esta función debe devolver un valor que representa el estado del sistema (población) en el momentot + 1, utilizando la función de mapeo:
f(t+1) = r * f(t) * [1 - f(t)]
Utilizando un bucle
forowhile, itere la funciónlogistic_mapdefinida en la parte 1, partiendo de una población inicial de 0.5, durante un periodo de tiempot_final = 10. Almacena los resultados intermedios en una lista, de forma que al finalizar el bucle hayas acumulado una secuencia de valores que representen el estado del mapa logístico en los tiempost = [0,1,...,t_final](11 valores en total). Imprima esta lista para ver la evolución de la población.Encapsule la lógica de su bucle en una función llamada
iterateque toma la población inicial como primera entrada, el parámetrot_finalcomo segunda entrada y el parámetrorcomo tercera entrada. La función debe devolver la lista de valores que representan el estado del mapa logístico en los tiempost = [0,1,...,t_final]. Ejecute esta función para los periodost_final = 100y1000e imprima algunos de los valores. ¿La población tiende hacia un estado estacionario?
PYTHON
initial_population = 0.5
t_final = 10
r = 1.0
population = [initial_population]
for t in range(t_final):
population.append( logistic_map(population[t], r) )PYTHON
def iterate(initial_population, t_final, r):
population = [initial_population]
for t in range(t_final):
population.append( logistic_map(population[t], r) )
return population
for period in (10, 100, 1000):
population = iterate(0.5, period, 1)
print(population[-1])SALIDA
0.06945089389714401
0.009395779870614648
0.0009913908614406382La población parece acercarse a cero.
Uso de funciones con condicionales en Pandas
Las funciones a menudo contienen condicionales. He aquí un breve ejemplo que indicará en qué cuartil se encuentra el argumento basándose en los valores codificados a mano para los puntos de corte de los cuartiles.
PYTHON
def calculate_life_quartile(exp):
if exp < 58.41:
# This observation is in the first quartile
return 1
elif exp >= 58.41 and exp < 67.05:
# This observation is in the second quartile
return 2
elif exp >= 67.05 and exp < 71.70:
# This observation is in the third quartile
return 3
elif exp >= 71.70:
# This observation is in the fourth quartile
return 4
else:
# This observation has bad data
return None
calculate_life_quartile(62.5)SALIDA
2Esa función se usaría típicamente dentro de un bucle
for, pero Pandas tiene una forma diferente y más eficiente
de hacer lo mismo, y es aplicando una función a un marco de
datos o a una porción de un marco de datos. He aquí un ejemplo,
utilizando la definición anterior.
PYTHON
data = pd.read_csv('data/gapminder_all.csv')
data['life_qrtl'] = data['lifeExp_1952'].apply(calculate_life_quartile)Hay muchas cosas en esa segunda línea, así que vayamos por partes. En
el lado derecho de la = empezamos con
data['lifeExp'], que es la columna en el marco de datos
llamado data etiquetado lifExp. Utilizamos el
apply() para hacer lo que dice, aplicar el
calculate_life_quartile al valor de esta columna para cada
fila en el marco de datos.
- Descomponer los programas en funciones para facilitar su comprensión.
- Define una función usando
defcon un nombre, parámetros y un bloque de código. - Definir una función no la ejecuta.
- Los argumentos de una llamada a una función coinciden con sus parámetros definidos.
- Las funciones pueden devolver un resultado a su invocador utilizando
return.
Content from Ámbito de una variable
Última actualización: 2025-02-28 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo funcionan realmente las llamadas a funciones?
- ¿Cómo puedo determinar dónde se han producido los errores?
Objetivos
- Identifica las variables locales y globales.
- Identifica parámetros como variables locales.
- Lee un traceback y determina el archivo, función y número de línea en el que ocurrió el error, el tipo de error y el mensaje de error.
El ámbito de una variable es la parte de un programa que puede ‘ver’ esa variable.
- Hay un número limitado de nombres sensatos para las variables.
- La gente que usa funciones no debería tener que preocuparse de qué nombres de variables usó el autor de la función.
- La gente que escribe funciones no debería preocuparse por los nombres de las variables que usa el invocador de la función.
- La parte de un programa en la que una variable es visible se llama su ámbito.
-
pressurees una variable global.- Definida fuera de cualquier función particular.
- Visible en todas partes.
-
tytemperatureson variables locales enadjust.- Definida en la función.
- No visible en el programa principal.
- Recuerda: un parámetro de función es una variable a la que se le asigna automáticamente un valor cuando se llama a la función.
SALIDA
adjusted: 0.01238691049085659ERROR
Traceback (most recent call last):
File "/Users/swcarpentry/foo.py", line 8, in <module>
print('temperature after call:', temperature)
NameError: name 'temperature' is not definedLectura de mensajes de error
Lee el traceback de abajo, e identifica lo siguiente:
- ¿Cuántos niveles tiene el traceback?
- ¿Cuál es el nombre del fichero donde se ha producido el error?
- ¿Cuál es el nombre de la función en la que se ha producido el error?
- ¿En qué número de línea de esta función se produjo el error?
- ¿Cuál es el tipo de error?
- ¿Cuál es el mensaje de error?
ERROR
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-2-e4c4cbafeeb5> in <module>()
1 import errors_02
----> 2 errors_02.print_friday_message()
/Users/ghopper/thesis/code/errors_02.py in print_friday_message()
13
14 def print_friday_message():
---> 15 print_message("Friday")
/Users/ghopper/thesis/code/errors_02.py in print_message(day)
9 "sunday": "Aw, the weekend is almost over."
10 }
---> 11 print(messages[day])
12
13
KeyError: 'Friday'- Tres niveles.
errors_02.pyprint_message- Línea 11
-
KeyError. Estos errores se producen cuando intentamos buscar una clave que no existe (normalmente en una estructura de datos como un diccionario). Podemos encontrar más información sobreKeyErrory otras excepciones incorporadas en los Python docs. KeyError: 'Friday'
- El ámbito de una variable es la parte de un programa que puede ‘ver’ esa variable.
Content from Estilo de programación
Última actualización: 2025-07-01 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo puedo hacer mis programas más legibles?
- ¿Cómo formatean su código la mayoría de los programadores?
- ¿Cómo pueden los programas comprobar su propio funcionamiento?
Objetivos
- Proporcione justificaciones sólidas para las reglas básicas de estilo de codificación.
- Refactorice programas de una página para hacerlos más legibles y justifique los cambios.
- Utiliza los estándares de codificación de la comunidad Python (PEP-8).
Estilo de codificación
Un estilo de codificación consistente ayuda a otros (incluyendo a nuestros futuros yoes) a leer y entender el código más fácilmente. El código se lee mucho más a menudo de lo que se escribe, y como dice el Zen of Python, “La legibilidad cuenta”. Python propuso un estilo estándar a través de una de sus primeras Propuestas de Mejora de Python (PEP), PEP8.
Algunos puntos que vale la pena destacar:
- documente su código y asegúrese de que las suposiciones, algoritmos internos, entradas esperadas, salidas esperadas, etc., están claros
- use nombres de variables claros y semánticamente significativos
- use espacios en blanco, no tabuladores, para sangrar las líneas (los tabuladores pueden causar problemas en diferentes editores de texto, sistemas operativos y sistemas de control de versiones)
Siga el estilo estándar de Python en su código.
-
PEP8: una
guía de estilo para Python que trata temas como el nombre de las
variables, la sangría del código, la estructura de las sentencias
import, etc. Adherirse a PEP8 hace que sea más fácil para otros desarrolladores de Python leer y entender tu código, y comprender cómo deben ser sus contribuciones. - Para comprobar que tu código cumple con PEP8, puedes utilizar la aplicación pycodestyle y herramientas como el formateador de código negro pueden formatear automáticamente tu código para que se ajuste a PEP8 y pycodestyle (también existe un formateador para cuadernos Jupyter nb_black).
- Algunos grupos y organizaciones siguen diferentes guías de estilo además de PEP8. Por ejemplo, la guía de estilo de Google sobre Python hace recomendaciones ligeramente diferentes. Google escribió una aplicación que puede ayudarte a formatear tu código en su estilo o en PEP8 llamada yapf.
- Con respecto al estilo de codificación, la clave es la consistencia. Elige un estilo para tu proyecto, ya sea PEP8, el estilo de Google o cualquier otro, y haz todo lo posible para asegurarte de que tú y cualquier otra persona con la que colabores os atenéis a él. La coherencia dentro de un proyecto suele tener más impacto que el estilo concreto utilizado. Un estilo coherente hará que tu software sea más fácil de leer y entender para los demás y para tu futuro yo.
Utilice aserciones para comprobar errores internos.
Las aserciones son un método sencillo pero potente para asegurarse de que el contexto en el que se ejecuta el código es el esperado.
PYTHON
def calc_bulk_density(mass, volume):
'''Return dry bulk density = powder mass / powder volume.'''
assert volume > 0
return mass / volumeSi la aserción es False, el intérprete de Python lanza
una excepción en tiempo de ejecución AssertionError. El
código fuente de la expresión que falló se mostrará como parte del
mensaje de error. Para ignorar las aserciones en su código ejecute el
intérprete con la opción ‘-O’ (optimizar). Las aserciones deben contener
sólo comprobaciones simples y nunca cambiar el estado del programa. Por
ejemplo, una aserción nunca debe contener una asignación.
Utiliza docstrings para proporcionar ayuda integrada.
Si lo primero en una función es una cadena de caracteres que no está asignada directamente a una variable, Python la adjunta a la función, accesible a través de la función de ayuda incorporada. Esta cadena que proporciona documentación también se conoce como docstring.
PYTHON
def average(values):
"Return average of values, or None if no values are supplied."
if len(values) == 0:
return None
return sum(values) / len(values)
help(average)SALIDA
Help on function average in module __main__:
average(values)
Return average of values, or None if no values are supplied.¿Qué se mostrará?
Resalta las líneas en el código de abajo que estarán disponibles como ayuda en línea. ¿Hay líneas que deberían estar disponibles, pero no lo estarán? ¿Alguna línea producirá un error de sintaxis o un error de ejecución?
PYTHON
"Find maximum edit distance between multiple sequences."
# This finds the maximum distance between all sequences.
def overall_max(sequences):
'''Determine overall maximum edit distance.'''
highest = 0
for left in sequences:
for right in sequences:
'''Avoid checking sequence against itself.'''
if left != right:
this = edit_distance(left, right)
highest = max(highest, this)
# Report.
return highestDocumenta Esto
Utiliza comentarios para describir y ayudar a otros a entender secciones potencialmente poco intuitivas o líneas individuales de código. Son especialmente útiles para quien pueda necesitar entender y editar su código en el futuro, incluido usted mismo.
Use docstrings para documentar las entradas aceptables y las salidas
esperadas de un método o clase, su propósito, suposiciones y
comportamiento previsto. Los docstrings se muestran cuando un usuario
invoca el método incorporado help en su método o clase.
Convierte el comentario de la siguiente función en un docstring y
comprueba que help lo muestra correctamente.
Limpiar este código
- Lee este breve programa e intenta predecir lo que hace.
- Ejecútalo: ¿cómo de precisa fue tu predicción?
- Refactoriza el programa para hacerlo más legible. Recuerda ejecutarlo después de cada cambio para asegurarte de que su comportamiento no ha cambiado.
- Compara tu reescritura con la de tu vecino. ¿Qué has hecho igual? ¿Qué hiciste diferente y por qué?
He aquí una solución.
PYTHON
def string_machine(input_string, iterations):
"""
Toma una cadena de entrada (input_string) y genera una nueva cadena con '-' y '*'
según si los caracteres tienen o no caracteres adyacentes idénticos.
Itera este procedimiento con las cadenas resultantes durante el número de
iteraciones especificado.
"""
print(input_string)
input_string_length = len(input_string)
old = input_string
for i in range(iterations):
new = ''
# iterate through characters in previous string
for j in range(input_string_length):
left = j-1
right = (j+1) % input_string_length # ensure right index wraps around
if old[left] == old[right]:
new = new + '-'
else:
new = new + '*'
print(new)
# store new string as old
old = new
string_machine('et cetera', 10)SALIDA
et cetera
*****-***
----*-*--
---*---*-
--*-*-*-*
**-------
***-----*
--**---**
*****-***
----*-*--
---*---*-- Siga el estilo estándar de Python en su código.
- Utilice docstrings para proporcionar ayuda integrada.
Content from Recapitulación
Última actualización: 2025-02-28 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Qué hemos aprendido?
- ¿Qué más hay y dónde puedo encontrarlo?
Objetivos
- Nombra y localiza sitios de la comunidad científica de Python para software, talleres y ayuda.
Leslie Lamport dijo una vez: “Escribir es la forma que tiene la naturaleza de mostrarte lo descuidado que es tu pensamiento” Lo mismo ocurre con la programación: muchas cosas que parecen obvias cuando las pensamos resultan ser cualquier cosa menos cuando tenemos que explicarlas con precisión.
Python apoya a una comunidad grande y diversa a través de la academia y la industria.
La documentación de Python 3 cubre el núcleo del lenguaje y la biblioteca estándar.
PyCon es la mayor conferencia anual de la comunidad Python.
SciPy es una rica colección de utilidades científicas. También es el nombre de una serie de conferencias anuales.
Jupyter es el hogar del Proyecto Jupyter.
Pandas es el hogar de la biblioteca de datos Pandas.
Stack Overflow’s general Python section puede ser útil, así como las secciones sobre NumPy, SciPy, y Pandas.
- Python apoya a una amplia y diversa comunidad académica e industrial.
Content from Comentarios
Última actualización: 2025-02-28 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Qué tal la clase?
Objetivos
- Recopilar comentarios sobre la clase
Recoge los comentarios de los participantes.
- Intentamos mejorar constantemente este curso.